Integration patterns describe how data and events move between systems. They help teams scale operations, handle increasing workloads, and adapt to new processes.
In practice, many teams don't choose them but inherit from earlier decisions. A scheduled SQL script becomes the company's ETL strategy. A webhook someone set up late at night becomes the only link between two platforms. By the time anyone notices, Slack messages and tribal knowledge hold your architecture together. This system isn’t reliable or repeatable, and it isn’t sustainable under growth.
In this guide, we cover common integration patterns and the ways they fit into daily work.
Integration patterns every technical team should know
Every integration decision has two layers. There's the immediate question — how do I get this data from A to B — and the structural question underneath it: how should A and B be connected in the first place?
Teams that solve only the first layer end up with systems that work individually but become increasingly difficult to maintain, extend, and debug as the number of connections grows.
We’ll discuss both, starting with data patterns because they're the decisions you face first and most often. Then we’ll move into architectural patterns that determine whether those decisions hold up at scale.
Data integration patterns
Data integration patterns govern the movement of information between systems, like databases, warehouses, and SaaS apps. The right one comes down to volume and freshness — how much data, how fast it has to land — plus whether the source can push to you or has to be polled.
These are distinct from enterprise application integration patterns. We’ll cover those below.
ETL and ELT
The distinction matters less than it used to, but it hasn't disappeared. Cloud warehouses like Snowflake, BigQuery, and Databricks handle transformation efficiently at the storage layer, so ELT has become the default for analytics workloads — load raw, transform in the warehouse. In contrast, ETL transforms in a staging layer before the load. It still wins when the target is a transactional database that can't accept raw data, or when compliance rules require scrubbing PII before it lands anywhere central. Use ELT for analytics and ETL when the destination has rules.
Migration
Migrations are one-time bulk moves. This might be decommissioning a legacy CRM, consolidating two acquired companies onto one ERP, or switching billing providers. You build it and run it once or twice.
Broadcast
Broadcast pushes the same record from one source to many targets, in near real time. Say a new customer signs up. That record needs to land in the CRM, the billing system, and the analytics warehouse, ideally within seconds. Broadcast is one-way and asynchronous, which means the source has no idea whether downstream systems accepted the data. It’s best to implement idempotency to ensure the same event processed twice doesn't create duplicate records; and dead-letter handling to route failed messages to a separate queue for review.
Bidirectional sync
This pattern instantly updates two or more connected platforms. Two systems act as sources of truth and need to stay in agreement — like a contact updated in HubSpot showing up in Salesforce, and vice versa. The challenge in this pattern is its strength. Real-time updates are useful, but which version wins when both records change in the same minute? Some teams underestimate this and ship something that quietly corrupts data for months.
Change Data Capture (CDC)
CDC tracks changes in a source database and propagates them downstream in near real time. Unlike ETL, which moves data on a schedule, CDC streams only what changed since the last sync. Tools like Debezium capture changes directly from the database transaction log. This helps to keep analytics warehouses up to date without full table scans or intensive polling.
Aggregation
Aggregation is the reporting pattern. It pulls data from several systems, unifies and lands in one destination. The challenge with this pattern is smooth consolidation. For instance, every source might call the “customer” something distinct, and the pattern must rationalize those differences by transforming and translating the data.
Aggregation runs through multi-source workflows with several data transformation nodes for combining data from multiple sources. Built-in retry logic and error workflows mean failures get captured automatically instead of letting them pass unnoticed.
Enterprise integration patterns
Enterprise integration patterns (EIP) describe how applications communicate — loose coupling and asynchronous messaging at the core, with resilience built in. They’re the layer above the data plumbing.
Point-to-point
The simplest EIP: System A talks directly to System B. This straightforward process works fine when you have a handful of integrations. But it could collapse around the eighth or ninth integration, when you realize you've built dozens of brittle connectors. A single API change can break multiple integrations at once, and tracing which connections are affected becomes harder with every new endpoint.
Hub-and-spoke
A central broker sits between all systems. Each app talks only to the hub, and the hub handles routing, transformation, and protocol translation. This is the standard response to point-to-point sprawl, and it's how most modern integration platforms are organized. The risk is creating a single point of failure. If the hub is down, communication between systems can stop.
Event-driven
Event-driven systems publish events when something happens, and other systems react. There’s no polling or scheduled jobs. Event-driven architecture excels when latency matters and the producer doesn't need to know who the consumers are. The trade-off is observability: Tracing a problem across three services and a queue is harder than reading a single linear log.
Publish-subscribe
With this pattern, a producer publishes messages to a topic, and any number of subscribers consume them independently. It's broadcast plus durability — messages are queued, retried, and replayable. Pub/sub is the core of many modern event architectures, from Kafka and SNS to Google Pub/Sub itself.
API-led connectivity
This layers APIs by purpose. Instead of building one monolithic API, you organize them into three types. System APIs that expose raw data, process APIs that orchestrate business logic across them, and experience APIs that sit on top to serve specific channels, like mobile and web apps. It's solid discipline for large organizations, though smaller teams find the layering more complex than useful.
Saga
When a business transaction spans multiple services, the saga pattern coordinates the sequence. Each service performs its step and publishes an event for the next. If any step fails, compensating actions undo the previous ones. It's the alternative to distributed transactions, which don't scale well across microservices.
How to choose the right integration pattern
There’s no universal best pattern, but these five criteria narrow it down quickly:
- Direction: Is the data flowing one way, or do both systems need to stay in sync?
- Latency: Do you need changes propagated in seconds? Or is a nightly refresh fine?
- Scale: How many endpoints do you have? Is it a handful? Or higher like a dozen or more?
- Volume: How much data are you handling? Are you integrating a few thousand records daily or a few million?
- Cadence: Are you implementing a one-time cutover? Or are you managing ongoing pipelines?
Most production architectures combine patterns. For instance, a real-time customer signup fanning out to five downstream tools is a broadcast, and almost certainly event-driven. But if you're switching help desk vendors mid-contract, you’ll likely choose migration.
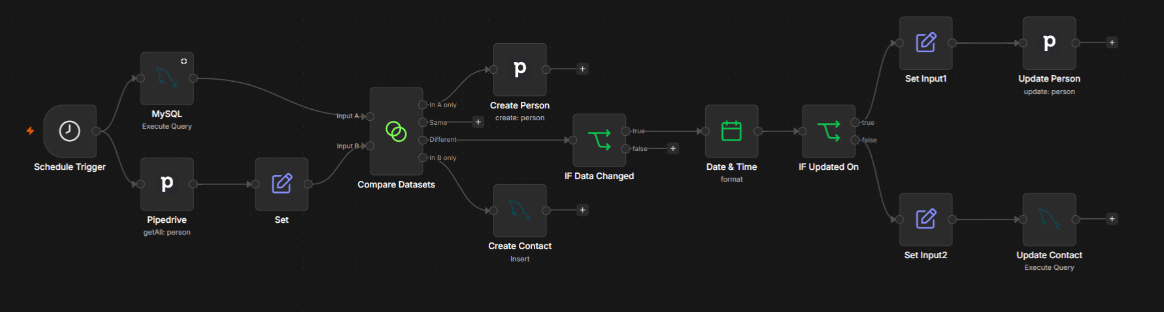
When patterns overlap, you don't need separate tools for each one. You build workflows that take care of each pattern, with every step traceable in the execution history.
Choosing patterns deliberately
Integration architecture compounds. Every pattern you add becomes a dependency that other systems build on top of. The cost of changing a pattern six months in is significantly higher than choosing the right one upfront.
That's why the two-layer framework matters: data patterns determine what moves and how fast, enterprise patterns determine whether the architecture stays manageable as the number of connections grows.
n8n gives you a single platform where both layers coexist — scheduled pipelines next to event-driven webhooks, bidirectional syncs alongside broadcast workflows. Every execution is logged, every step is easy to track, and every pattern can be modified without rewriting the connections around it.
Try n8n Cloud free to start building production integration workflows without writing custom code for every connection.
FAQ
What are integration design patterns?
Integration design patterns are reusable architectural approaches for connecting different systems. They standardize messaging, routing, and data transformation between services.
What are integration architecture patterns?
Integration architecture patterns describe how a system’s integrations are structured and organized. A few examples are point–to-point, hub-and-spoke, and pub/sub. They focus on governance more than the mechanics of any individual connection. In this article, we cover these under enterprise integration patterns.
When should you combine integration patterns?
Production architectures almost always call for running two or three at once. A SaaS company might simultaneously broadcast signup events in real time, ELT order data into the warehouse overnight, and bidirectionally sync customer records with their CRM.
Are integration patterns the same as iPaaS?
No, iPaaS is the category of tools you use to implement patterns. They’re managed platforms that handle connectors, scheduling, and execution. Integration patterns are the architectural decisions you make about how data should move, regardless of tooling.