
AI pipelines rarely fail loudly. They run, return clean outputs, and pass downstream validation — except the answer is wrong. A summarization step invents metrics. A classification agent returns inconsistent labels. None throw exceptions, so pipelines look fine. These failures are AI hallucinations.
LLM hallucinations are hard to catch because models generate them with the same confidence as correct answers. Prompt tweaks alone don’t fix these issues. Teams need to expose inputs and outputs at every node.
This guide covers what causes AI hallucinations, how to identify them in production, and how to build pipeline architectures that catch them before they reach users.
What are AI hallucinations?
In the context of LLMs, AI hallucinations are fluent, confident outputs that contradict source material, fabricate information, or violate prompt constraints. An LLM picks the next token by statistical likelihood, not factual verification. It pattern-matches without fact-checking. When training data is sparse or contradictory, the model produces a plausible answer with no internal signal it might be wrong.
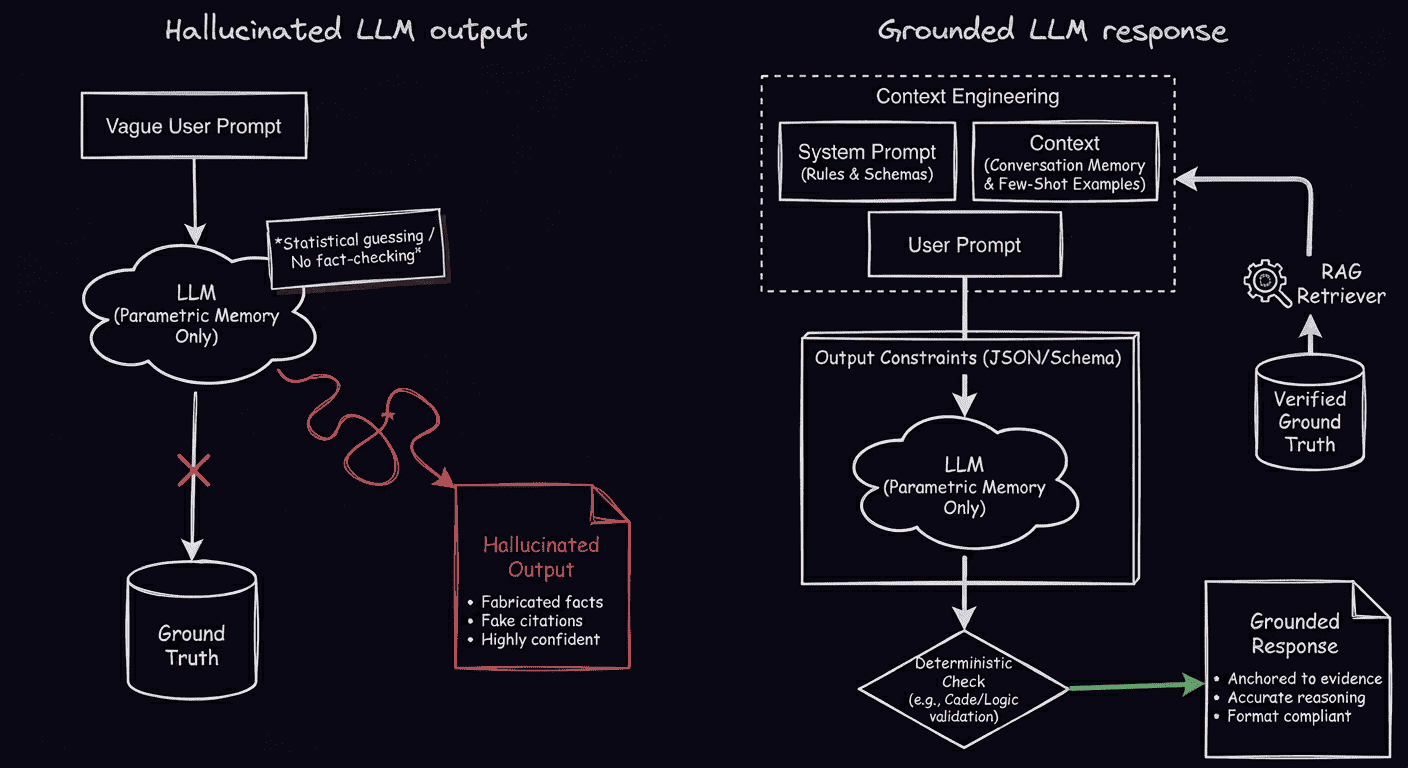
What causes AI hallucinations?
Hallucinations come from a few failure modes. Review these different causes to refine your approach at the source.
Training data gaps and knowledge cutoffs
LLMs only know what was in their training data, fixed at a cutoff date. Ask about something that happened after the cutoff, and the model will refuse or invent a response — e.g. if users ask about a person who joined a company last week or a paper published this morning. Retrieval closes that gap, but fine-tuning a prompt doesn't.
Training data bias and contamination
Even within the database, accuracy isn't uniform. Training data mixes outdated articles, contradictory sources, and outright misinformation alongside ground truth. For instance, Google AI Overview recommended adding glue to pizza in 2024 due to its retrieval system pulling a Reddit joke as a legitimate source. Retrieval over a verified, curated source overrides this, but only if the source is actually curated.
Lack of grounding and model overconfidence
Without an explicit reference, an LLM defaults to its parametric memory. This is a compressed summary of training that blends sources and approximates numbers, and supported answers and inventions arrive with the same confidence. Pinning each step to retrieved evidence forces the model to cite, not invent.
Prompt ambiguity and over-constraint
While hallucinations are most often tied to architecture, a vague prompt invites the model to fill in the blanks. If you demand three bullets, each starting with a verb and citing two sources, the model gets pushed into a corner. It must satisfy every rule, which might mean inventing content to fit the form. The best fix is to tighten the question and loosen the format.
Model configuration
LLMs sample from a probability distribution rather than picking the most likely token. Higher temperature and top-p widen the distribution. This works for creative writing but not for anything that needs exact accuracy. For extraction, classification, and structured generation, lower the temperature and set seeds where supported.
Types of AI hallucinations
Treating hallucinations as one category makes detection harder. Five types show up repeatedly in production, and each has a different signature. Here are the AI hallucination examples engineering teams hit most often.
Factual fabrication
The model invents a fact: a statistic, a person, or a product feature that doesn't exist. In 2024, a Canadian tribunal ordered Air Canada to honor a bereavement-fare refund after its customer-service chatbot provided incorrect policy information. The detection signal is a mismatch with a verified source. If the answer can't be matched against retrieved documents or a structured database, it's a fabrication.
Citation hallucination
The model produces a plausibly formatted citation — with author, journal, and year — for a non-existent paper. A New York lawyer was sanctioned in 2023 for filing a federal brief in Mata v. Avianca with six ChatGPT-fabricated citations. These citations read legitimately, but the AI invented every detail. Verify the information: Every citation must resolve to a URL, DOI, or document ID.
Source conflation
The model blends information from two real sources into one false statement. In RAG systems, the retriever returns chunks from different documents. For instance, it attributes product B’s pricing to product A. One way to reduce such hallucinations is making sure every claim traces to one chunk, not a synthesis.
Reasoning errors
The output is fluent and each fact is right, but the chain of reasoning between them isn't. For example, a pricing agent identifies two SKUs and their prices, then returns a sum off by ten percent. Hallucination detection at the reasoning layer means validating intermediate outputs, not just final answers.
Instruction drift
Over long contexts or multi-turn conversations, the model loses track of the original instruction. For instance, a classification agent told to output one of three labels might return four-word descriptions. Check structurally — the output should conform to the prompt’s schema, not just read coherently.
How to prevent AI hallucinations
While clarity helps, no prompt fully stops hallucinations. Reliability comes from the architecture around the model. Use deterministic checks wherever possible and AI for everything else.
Ground outputs in verified data with RAG
Retrieval-augmented generation pulls relevant documents from a vector database before generation, conditioning the output on real source material. Retrieval quality is a key factor. Hybrid search catches results that either method alone would miss. Re-ranking then scores a broad set of candidates for actual relevance before passing the top results to the model. However, the limitation remains: A RAG hallucination still happens when the retriever pulls irrelevant chunks or chunk boundaries split the answer.
Constrain the model with structured outputs
Free-form text invites drift. A JSON object that conforms to a schema removes most of the surface where hallucinations ride. Keep in mind, a perfectly formed JSON object can still contain a fabricated value, so structure isn't the same as truth.
Add stepwise validation in agentic pipelines
Agentic systems chain multiple LLM calls, which can result in compounding errors down the line. Validating each output before it passes interrupts the chain. However, validation can be resource heavy and performance intensive. Reserve it for steps where wrong answers are costly.
Wrap AI steps with deterministic logic
Some steps have a correct answer that code can verify. Wrap those steps. For any price calculation, date comparison, or database lookup, the model’s output should pass a programmatic check first. Caveat: This works for verifiable claims, not subjective tasks like tone or summary.
Engineer context with memory and few-shot examples
In-context examples anchor model behavior more reliably than prompt instructions alone. A well-chosen few-shot example shows the model the exact format, reasoning style, and level of detail you expect. For multi-turn conversations, memory management is equally important: Preserving relevant context while dropping noise from earlier turns keeps the model grounded in what matters for the current step. The main limitation is shifting failure modes. To counter this, rotate your examples over time based on what debugging reveals.
Test and evaluate output systematically
Without evaluation, no one knows whether yesterday's change improved or broke the pipeline. Build a ground truth data set of representative inputs and outputs. Run the pipeline against it on every meaningful change. The main challenge is you’re mainly reducing established hallucinations, not covering new and edge cases.
Building hallucination-resistant AI pipelines in n8n
You can stack these mitigations. A pipeline layers them so each catches what the previous missed. The layers assume uncontrolled input, like user-submitted text, external catalogs, and chatbot prompts. Trusted internal data with a capable model needs fewer guardrails. Models on high-throughput pipelines need more.
n8n lets you build resilient AI pipelines as visible workflow steps: each layer is a node or group of nodes you can inspect, test, and adjust independently.
Layer 0 — Context engineering
Curate the context before generation. Memory nodes preserve relevant conversation state, and few-shot examples show the model the expected format. This catches under-specified prompts and routing errors before they cascade.
Layer 1 — Knowledge grounding
Anchor every answer in retrieved evidence. Vector store nodes pull relevant chunks from your knowledge base for the model to summarize. This process exposes training-data gaps and most factual fabrications.
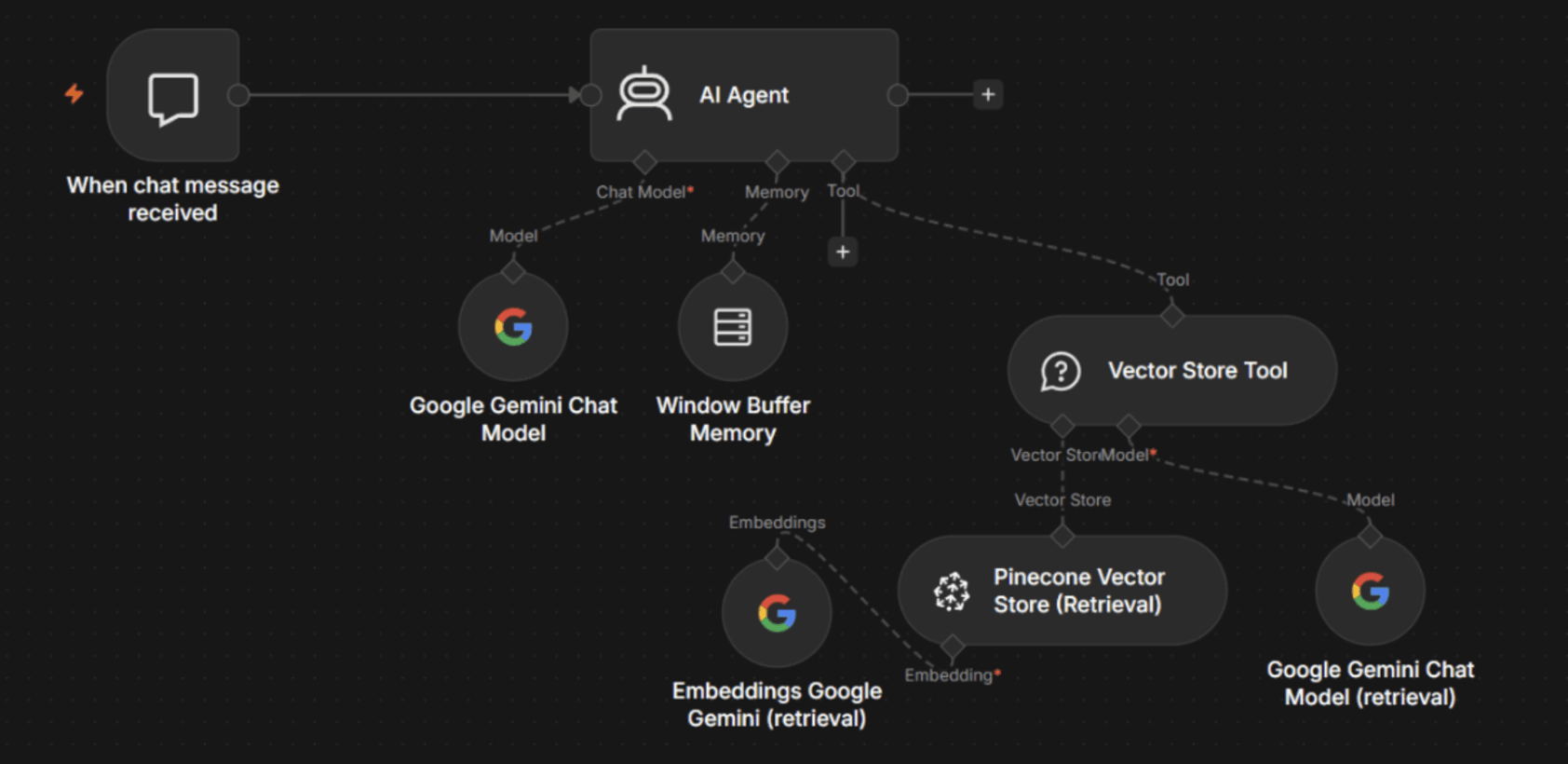
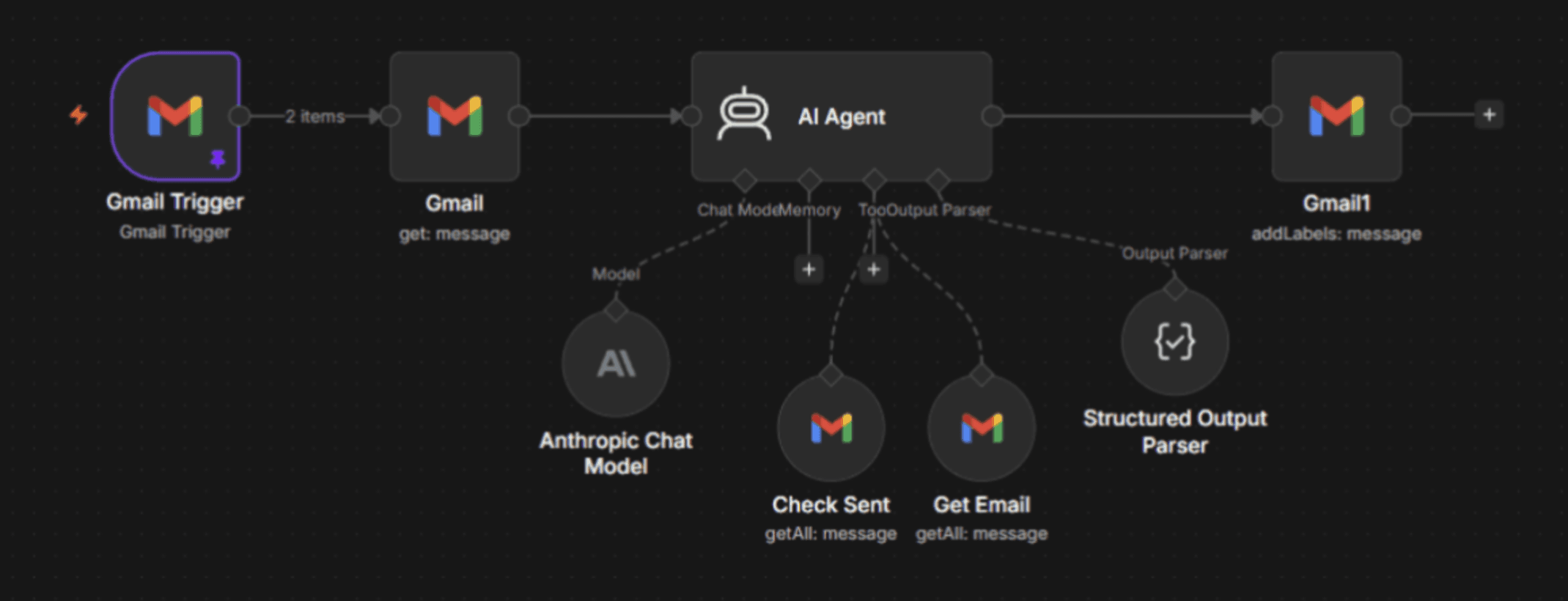
Layer 2 — Output constraints
Force the model into a schema. The Structured Output Parser, paired with the Auto-fixing Output Parser node and the Code node, catches issues before they propagate. This includes malformed responses, type mismatches, and instruction drift.
Layer 3 — Agentic validation
Insert checkpoints between AI steps. The IF node route low-confidence outputs to a human review queue or a stricter model. For agentic systems, the agent chooses between tools and sources rather than running a fixed pipeline. Be sure to use the Guardrails node to limit agent scope. AI with unrestricted access to applications and data can violate company policies.
Layer 4 — Continuous evaluation
Measure regressions before users do. The Evaluation node runs the pipeline against a ground truth dataset on every change, surfacing regressions in factuality, schema conformance, and reasoning quality. Then, results feed back. For example, a factuality regression points to retrieval, and a reasoning regression demands a checkpoint. Without that loop, every fix is a guess.
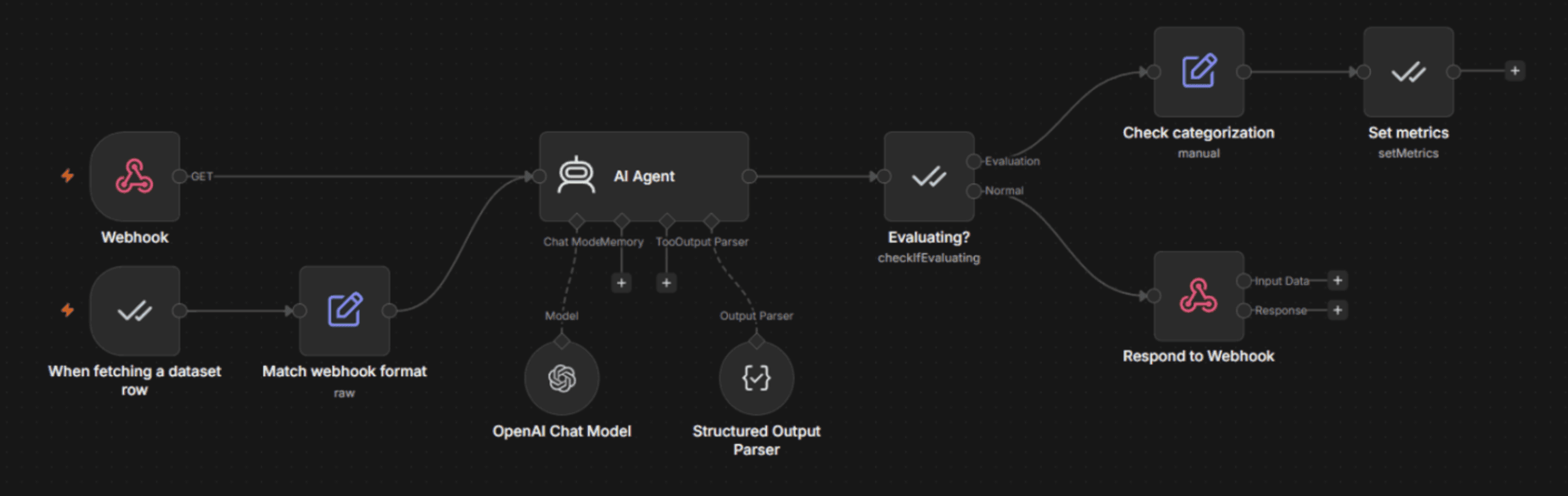
Produce reliable outputs with n8n
AI hallucinations aren't a bug waiting to be patched. They’re a structural property of how LLMs generate text. The work lives in everything around the model — grounding, constraints, validation, and evaluation. You target hallucinations with the right architecture, and n8n gives you the visibility to build and maintain that architecture.
In n8n, each mitigation is a workflow step you can inspect, version, and rerun against your datasets. That makes hallucination resistance engineering work, not prompt tinkering. Try n8n Cloud free, and start building hallucination-resistant pipelines you can inspect at every layer.