Retrieval augmented generation is often positioned as the go-to solution for optimizing LLMs. But despite the integration of RAG in agentic systems, LLMs may still present unsupported or contradictory claims to the retrieved contents.
Imagine a business analyst at a logistics company using an internal AI assistant powered by RAG to interact with financial reports. When the analyst asks, “What is our Q2 performance?”, the assistant responds: “Our Q2 revenue decreased by 15% compared to Q1 due to supply chain disruptions following the Suez Canal blockage.”
While the system correctly retrieved the financial report, noting a 15% revenue drop, it fabricated a justification by attributing the decline to the Suez Canal blockage—an explanation not present in the source material.
Retrieving documents doesn’t guarantee accuracy, so RAG itself must be optimized. This means tuning the search to return the right results, including less noise, and aligning the LLM response with the context retrieved.
That’s why in this article, we’ll discuss how RAG systems can still hallucinate, and provide a framework for evaluating RAG applications using the Ragas framework. Lastly, we’ll present how to implement RAG evaluations in n8n.
Four types of RAG hallucinations
Hallucinations have a slightly different definition in the context of RAG. We use the term to indicate a response is not supported by or aligned with the retrieved context. It is considered a hallucination when the LLM does not generate content based on the textual data provided to it as part of the RAG retrieval process, but rather generates content based on its pre-trained knowledge.
Vectara, the creators of the HHEM evaluation models, give the following example: if the retrieved context states "The capital of France is Berlin", and the LLM outputs "The capital of France is Paris", then the LLM response is hallucinated, despite it being correct.
We can categorize RAG-specific hallucinations into four categories, as described in the paper titled RAGTruth:
- Evident Conflict: for when generative content presents direct contraction or opposition to the provided information. These conflicts are easily verifiable without extensive context, often involving clear factual errors, misspelled names, incorrect numbers, etc.
- Subtle Conflict: for when generative content presents a departure or divergence from the provided information, altering the intended contextual meaning. These conflicts often involve substitution of terms that carry different implications or severity, requiring a deeper understanding of their contextual applications.
- Evident Introduction of Baseless Information: for when generated content includes information not substantiated in the provided information. It involves the creation of hypothetical, fabricated, or hallucinatory details lacking evidence or support.
- Subtle Introduction of Baseless Information: is when generated content extends beyond the provided information by incorporating inferred details, insights, or sentiments. This additional information lacks verifiability and might include subjective assumptions or commonly observed norms rather than explicit facts.
The two-pillar RAG evaluation framework
A good RAG implementation can validate two things:
- Making sure RAG retrieves the right information. This is RAG Document Relevance.
- Ensuring LLM answers are consistent with the context retrieved via RAG. This is RAG Groundedness
Most tools available today use the Ragas library, which provides a set of RAG-specific evaluation functions. We use the evaluations available in the Ragas library in the descriptions below.
RAG Document Relevance: Retrieving the right context
The Context Recall evaluation measures how many of the relevant documents were successfully retrieved. Higher recall means fewer relevant documents were left out. Context Precision is a metric that measures the proportion of relevant chunks in the retrieved contexts. Calculating context recall always requires a reference to compare against.
Both recall and precision can be calculated using a judge LLM or by using deterministic calculations.
LLM-based Context Recall is computed using three variables - the user input, the reference and the retrieved contexts. To estimate context recall from the reference, the reference is broken down into claims, each claim in the reference answer is analyzed to determine whether it can be attributed to the retrieved context or not.
LLM-based Context Precision is used to estimate if a retrieved context is relevant or not by having an LLM compare each of the retrieved contexts or chunks present in retrieved contexts with the response.
Non-LLM-Basedthe Context Recall and Precision compare retrieved contexts or chunks with the reference contexts. These metrics use measures such as semantic similarity, Levenshtein Similarity Ratio and string comparison metrics to determine if a retrieved context is relevant or not.
RAG Groundedness: Evaluating responses against retrieved context
Faithfulness determines how factually consistent a response is with the retrieved context. A response is considered faithful if all its claims can be supported by the retrieved context. Vectara's HHEM-2.1-Open is an open source classifier model that is trained to detect hallucinations from LLM generated text. It can be used to cross-check claims with the given context to determine if it can be inferred from the context.
Response Relevancy measures how relevant a response is to the user input. An answer is considered relevant if it directly and appropriately addresses the original question. This metric focuses on how well the answer matches the intent of the question, without evaluating factual accuracy. It penalizes answers that are incomplete or include unnecessary details.
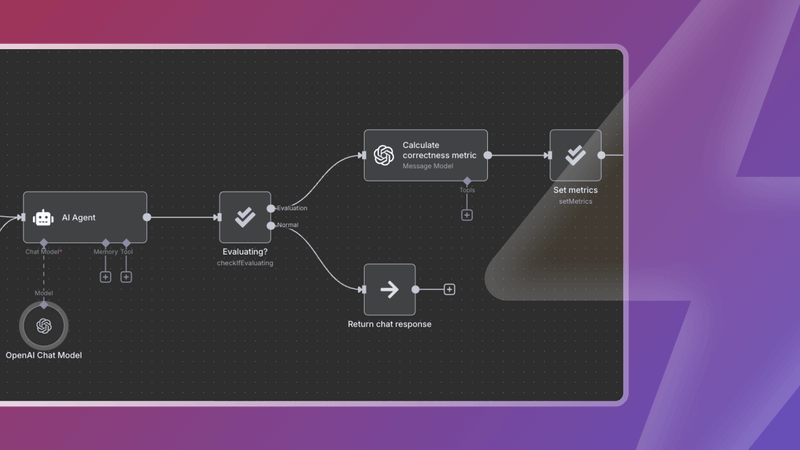
RAG Evaluations in n8n
You can evaluate RAG performance in n8n without external libraries or calls. The evaluations natively available include both RAG document relevance and answer groundedness. These calculate whether the documents retrieved are relevant to the question and if the answer is grounded in the documents retrieved. RAG evaluations are run against a test dataset, and results can be compared across runs to see how the metrics change and drill down into the reasons for those changes.
The Evaluate RAG Response Accuracy with OpenAI workflow template uses LLM-based response relevancy to assess whether the response is based on the retrieved documents. A high score indicates LLM adherence and alignment whereas a low score could signal inadequate prompt or model hallucination.
The RAG document relevance workflow uses an LLM-based context recall to calculate a retrieval score for each input and determine whether the workflow is performing well or not.
To understand more about evaluation in n8n, check out the Introducing Evaluations for AI Workflows blog post, and our technical documentation on the evaluation node.