
Open-source models are changing the LLM landscape, promising better security, cost-efficiency, and customization for AI deployments. While ChatGPT has over 180 million users, on-premises solutions already control more than half of the LLM market, with projections indicating continued growth in the coming years.
The trend is clear: since early 2023, new open-source model releases have nearly doubled compared to their closed-source counterparts.

Today, we’ll dive into the world of open-source LLMs and:
- discuss the reasons behind the surge in open-source LLM deployments;
- recognize potential pitfalls and challenges;
- review the 11 best open-source LLMs on the market;
- show you how to easily access these powerful open-source AI models;
- guide you on how to get started with open-source LLMs using Ollama and LangChain in n8n.
Read on to find out!
Are there any open-source LLMs?
For this article, we’ve selected 11 popular open-source LLM models, focusing on both widely used and available in Ollama.
Our review covers a range of pre-trained “base” models and their fine-tuned variants. These models come in various sizes, and you can either use them directly or opt for fine-tuned versions from original developers or third-party sources.
Here's our open-source LLM leaderboard:
| Model Family |
Developer | Params | Context window |
Use-cases | License |
|---|---|---|---|---|---|
| Llama 3 | Meta | 1B, 3B, 8B, 70B, 405B |
8k, 128k | - General text generation - Multilingual tasks - Code generation - Long-form content - Fine-tuning for specific domains |
Llama Community License |
| Mistral | Mistral AI | 3B-124B | 32k-128k | - High-complexity tasks - Multilingual processing - Code generation - Image understanding - Edge computing - On-device AI - Function calling - Efficient large-scale processing |
Apache 2.0 Mistral Research License Commercial License |
| Falcon 3 | TII | 1B, 3B, 7B, 10B |
8k-32k | - General text generation - Code generation - Mathematical tasks - Scientific knowledge - Multilingual applications - Fine-tuning for specific domains |
TII Falcon License |
| Gemma 2 | 2B, 9B, 27B | 8k | - General text generation - Question answering - Summarization - Code generation - Fine-tuning for specific domains |
Gemma license | |
| Phi-3.x / 4 | Microsoft | 3.8B (mini) 7B (small) 14B (medium) 42B (MoE) |
4k, 8k, 128k 16k (Phi-4) |
- General text generation - Multi-lingual tasks - Code understanding - Math reasoning - Image understanding (vision model) - On-device inference |
Microsoft Research License |
| Command R | Cohere | 7B, 35B, 104B | 128k | - Conversational AI - RAG - Tool use - Multilingual tasks - Long-form content generation |
CC-BY-NC 4.0 |
| StableLM 2 | Stability AI | 1.6B, 3B, 12B | Up to 16k | - Multilingual text generation - Code generation and understanding - Fine-tuning for specific tasks - Research and commercial applications |
Stability AI Community and Enterprise licenses |
| StarCoder2 | BigCode | 3B, 7B, 15B | 16k | - Code completion - Multi-language programming - Code understanding - Fine-tuning for specific tasks |
Apache 2.0 |
| Yi | 01.AI | 6B, 9B, 34B | 4k, 8k, 200k | - Bilingual text generation - Code understanding and generation - Math and reasoning tasks - Fine-tuning for specific domains |
Apache 2.0 |
| Qwen2.5 | Alibaba | 0.5B to 72B | 128K | - General text generation - Multilingual tasks - Code generation - Mathematical reasoning - Structured data processing |
Qwen license (3B and 72B size models) Apache 2.0 (others) |
| DeepSeek-V2.x/V3 | DeepSeek AI | 16B, 236B, 671B for V3 (2.4B-37B activated) |
32k-128k | - General text generation - Multilingual tasks - Code generation - Fine-tuning - Advanced reasoning (V3) |
DeepSeek License |
For a comprehensive list of available LLMs beyond our selection, you can explore the Awesome-LLM GitHub repository, which provides an extensive catalog of language models and related resources.
First, there is a dedicated node to connect to Ollama models – the easiest way to start working with locally deployed LLMs.
Second, an OpenAI node allows you to specify a custom endpoint. This way you can swap between OpenAI and open-source LLMs – a perfect solution for working with OpenRouter.
Finally, there are several nodes to other providers, such as HuggingFace, and even a custom HTTP Request node. Thanks to the straightforward user interface in n8n, your LLM-powered workflow automations and AI-agents remain the same when you switch between models. To easily deploy a local model, begin with a n8n’s self-hosted AI starter kit with Ollama integration.
What are the advantages and disadvantages of open-source LLMs?
Open-source LLMs offer several advantages beyond publicly available model weights and increased transparency:
- Full ownership ensures complete control over the model, additional training data, and practical applications.
- Better fine-tuning accuracy is possible due to flexible customization of local model parameters, supported by community contributions.
- Longevity is guaranteed as self-hosted models don’t become obsolete, unlike closed-source providers who may “retire” older models.
- Better cost estimation is possible as expenses shift from potentially volatile usage-based pricing to infrastructure costs. However, total costs may exceed subscription-based services, depending on usage patterns and infrastructure choices.
- Flexibility in choosing software and hardware combinations allows for optimal resource allocation based on specific needs.
- Community contributions enable model optimization through techniques like quantization and pruning, as well as the development of efficient deployment strategies and supporting tools.
Despite their benefits, open-source LLMs come with some potential drawbacks:
- Quality may not match solutions offered by large corporations due to limited resources.
- Vulnerability to attacks is a concern, as bad actors can potentially manipulate input data and interfere with the model’s behavior in open-source environments.
- License requirements vary widely. Some models use permissive licenses (like Apache 2.0), others have non-commercial restrictions, and some (like Meta Llama 3) include specific terms for commercial usage.
What is the best open-source LLM?
There is no single best open-source LLM.
And here’s why.
There are many benchmarks for rating the models, and various research groups decide which benchmarks are suitable. This makes objective comparison rather non-trivial.
Thanks to the Hugging Face, there is a public leaderboard for the open-source LLMs.
It performs tests on 6 key benchmarks using the Eleuther AI Language Model Evaluation Harness. The results are aggregated and each model receives a final score.
The leaderboard has several quick filters for consumer-grade, edge device models and so on. Several adjustable columns such as model size, quantization method, etc. are also available.
The leaderboard is an open competition and anyone can submit their model for evaluation.
Let’s take open-source LLMs one by one and have a closer look at them!
Llama3
Best for: general-purpose applications with scalability needs

Llama 3 is Meta’s latest generation of open-source large language models, offering high performance across a wide range of tasks. The latest Llama 3.3 70B model offers performance comparable to the 405B parameter model at a fraction of the computational cost, making it an attractive option for developers and researchers.
- Multiple model sizes: 1B, 3B, 8B, 70B, and 405B parameters
- Multilingual and multimodal capabilities
- Grouped Query Attention (GQA) for improved inference efficiency
- Context windows of 8k tokens for smaller models, up to 128k tokens for larger models
- Responsible AI development with tools like Llama Guard 2 and Code Shield
- General-purpose text generation and understanding
- Multilingual applications across various languages
- Code generation and understanding
- Long-form content creation and analysis
- Fine-tuning for specific domains or tasks
- Assistant-like interactions in chatbots and AI applications
Mistral
Best for: on-device AI with function calling

Mistral AI, a French startup, has rapidly become a major player in the open-source LLM space. Mistral’s models are designed to cater to a wide range of applications, from edge devices to large-scale enterprise solutions. The company offers both open-source models under Apache 2.0 license and commercial models with negotiable licenses. The latest Ministral model (3B and 8B) is particularly noteworthy for its performance in edge computing scenarios, outperforming similarly-sized models from tech giants.
- Multiple model sizes: from 3B to 124B parameters
- Multilingual and multimodal capabilities
- Large context windows up to 128k tokens
- Native function calling support
- Mixture-of-experts (MoE) architecture in some models
- Efficient models for edge computing and on-device AI
- Fine-tuning capabilities for specific domains or tasks
- General-purpose text generation and understanding
- High-complexity reasoning and problem-solving
- Code generation and understanding
- Image analysis and multimodal tasks
- On-device AI for smartphones and laptops
- Efficient large-scale processing with MoE models
Falcon 3
Best for: resource-constrained environments

Falcon 3 is the latest iteration of open-source large language models developed by the Technology Innovation Institute (TII) in Abu Dhabi. This family of models demonstrates impressive performance for small LLMs while democratizing access to advanced AI by enabling efficient operation on light infrastructures, including laptops.
- Multiple model sizes: 1B, 3B, 7B, and 10B parameters
- Trained on 14 trillion tokens, more than double its predecessor
- Superior reasoning and enhanced fine-tuning capabilities
- Extended context windows up to 32k tokens (except 1B model with 8k)
- Multilingual support (English, French, Spanish, and Portuguese)
- Falcon3-Mamba-7B variant using an alternative State Space Model (SSM) architecture
- General-purpose text generation and understanding
- Code generation and comprehension
- Mathematical and scientific tasks
- Multilingual applications
- Fine-tuning for specific domains or tasks
- Efficient deployment in resource-constrained environments
Gemma 2
Best for: responsible AI development and deployment

Gemma 2 is Google’s latest family of open-source LLMs, built on the same research and technology used to create the Gemini models. Offering strong performance for its size, Gemma 2 is designed with a focus on responsible AI development and efficient deployment.
- Multiple model sizes: 2B, 9B, and 27B parameters
- Exceptional performance, with the 27B model outperforming some larger proprietary models
- Optimized for efficient inference across various hardware, from edge devices to cloud deployments
- Built-in safety advancements and responsible AI practices
- Broad framework compatibility (Keras, JAX, PyTorch, Hugging Face, etc.)
- Complementary tools: ShieldGemma for content safety and Gemma Scope for model interpretability
- General-purpose text generation and understanding
- Question answering and summarization
- Code generation and understanding
- Fine-tuning for specific domains or tasks
- Responsible AI research and development
- On-device AI applications (especially with the 2B model)
Phi 3.x / 4
Best for: cost-effective AI solutions

Phi-3.x / 4 is Microsoft’s family of open-source Small Language Models (SLMs), designed to be highly capable and cost-effective. Phi-3.5 updates bring enhanced multi-lingual support, improved multi-frame image understanding, and a new MoE architecture. Phi-4, the latest model, emphasizes data quality over size. It was trained on synthetic data, filtered public content, and academic resources. The model achieves impressive performance over a range of benchmarks with just 16B parameters.
- Multiple model sizes: 3.8B (mini), 7B (small), 14B (medium), and 42B (MoE) parameters for Phi-3.x; 16B for Phi-4
- Long context window support up to 128K tokens for Phi-3.x, 16K for Phi-4
- Multilingual capabilities in over 20 languages
- Multi-modal support with Phi-3.5-vision for image understanding
- Mixture-of-Experts (MoE) architecture for improved efficiency
- Optimized for ONNX Runtime and various hardware targets
- Developed with Microsoft Responsible AI Standard
- General-purpose text generation and understanding
- Multilingual applications across various languages
- Code understanding and generation
- Mathematical reasoning and problem-solving
- On-device and offline inference scenarios
- Latency-sensitive applications
- Cost-effective AI solutions for resource-constrained environments
Command R
Best for: enterprise-level conversational AI and RAG

Command R is Cohere’s flagship family of LLMs for enterprise-level applications with a focus on conversational interaction and long-context tasks. The family includes Command R, Command R+, and the compact Command R7B, each optimized for different use cases.
- Long context window of 128k tokens
- Multilingual capabilities in 10 primary languages and 13 additional languages
- Tool use and multi-step reasoning for complex tasks
- Customizable safety modes for responsible AI deployment
- Command R7B offers on-device inference capabilities
- High-performance conversational AI and chatbots
- Complex RAG workflows for information retrieval and synthesis
- Multi-step tool use for dynamic, reasoning-based tasks
- Cross-lingual applications and translations
- Code generation and understanding
- Financial and numerical data analysis
- On-device applications (with Command R7B)
StableLM
Best for: rapid prototyping and experimentation

StableLM is Stability AI’s series of open-source LLMs, offering competitive performance in compact sizes. The family includes various model sizes and specializations. The 1.6B model, trained on approximately 2 trillion tokens, outperforms many models under 2B parameters on various benchmarks. Stability AI provides both base and instruction-tuned versions, along with pre-training checkpoints to facilitate further fine-tuning.
- Multiple model sizes: 1.6B, 3B, and 12B parameters
- Multilingual capabilities in English, Spanish, German, Italian, French, Portuguese, and Dutch
- Fill in Middle (FIM) capability for flexible code generation
- Long context support with sequences up to 16k tokens
- Optimized for speed and performance, enabling fast experimentation
- Specialized versions for code generation, Japanese and Arabic languages
- General-purpose text generation and understanding in multiple languages
- Code generation and understanding across various programming languages
- Fine-tuning for specific domains or tasks
- Research and commercial applications
Starcoder
Best for: code-related tasks and multi-language programming

StarCoder2 is the next generation of transparently trained open-source language models for code, developed by the BigCode project. It offers high performance for code-related tasks across a wide range of programming languages. The 15B model, in particular, matches the performance of much larger 33B+ models on many evaluations, while the 3B model matches the performance of the previous 15B StarCoder model, showcasing significant improvements in efficiency and capability.
- Multiple model sizes: 3B, 7B, and 15B parameters
- Trained on 600+ programming languages (15B model)
- Large context window of 16,384 tokens with sliding window attention of 4,096 tokens
- Grouped Query Attention (GQA) for improved efficiency
- Fill-in-the-Middle training objective
- Trained on 3+ trillion tokens (3B and 7B models) to 4+ trillion tokens (15B model)
- Code completion and generation across multiple programming languages
- Code understanding and analysis
- Fine-tuning for specific programming tasks or languages
- Assisting developers in various coding scenarios
- Research in code language models and AI for programming
Yi
Best for: bilingual applications (English and Chinese)

Yi is a series of open-source LLMs developed by 01.AI, offering strong performance in both English and Chinese across a wide range of tasks. The Yi-1.5 series, an upgraded version of the original Yi models, delivers enhanced capabilities in coding, math, reasoning, and instruction-following.
- Multiple model sizes: 6B, 9B, and 34B parameters
- Bilingual support for English and Chinese
- Extended context windows up to 200k tokens for larger models
- Continuous pre-training on high-quality corpus (500B tokens for Yi-1.5)
- Fine-tuned on 3M diverse samples for improved instruction-following
- Optimized for efficient deployment and fine-tuning
- Bilingual text generation and understanding
- Code generation and comprehension
- Mathematical problem-solving and reasoning tasks
- Fine-tuning for domain-specific applications
- Natural language processing in academic and commercial settings
- Building chatbots and AI assistants
Qwen2.5
Best for: multilingual and specialized tasks (coding and math)

Qwen2.5 is Alibaba’s latest series of open-source LLMs with a wide range of sizes and specialized variants for coding and mathematics. These models represent a significant advancement in multilingual capabilities and task-specific performance.
- Multiple model sizes: 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B parameters
- Pretrained on up to 18 trillion tokens
- 128K token context window with generation up to 8K tokens
- Multilingual support for over 29 languages
- Specialized models: Qwen2.5-Coder and Qwen2.5-Math
- Improved instruction following and structured data understanding
- Enhanced JSON output generation
- General-purpose text generation and understanding
- Multilingual applications across various languages
- Code generation and understanding with Qwen2.5-Coder
- Mathematical reasoning and problem-solving with Qwen2.5-Math
- Long-form content creation and analysis
- Structured data processing and JSON output generation
- Chatbot development with improved role-play capabilities
Deepseek 2.x / 3
Best for: efficient large-scale language processing

DeepSeek is a series of powerful open-source LLMs developed by DeepSeek AI, featuring innovative architectures for efficient inference and cost-effective training. The DeepSeek-V2 and V2.5 models are available for use with Ollama. While the recently released DeepSeek-V3 offers even more impressive capabilities with its 671B parameters, it is not yet available in Ollama at the moment of writing.
- Mixture-of-Experts (MoE) architecture for efficient parameter usage
- Multi-head Latent Attention (MLA) for improved inference efficiency
- Large context windows of up to 128k tokens
- Multilingual capabilities, with strong performance in English and Chinese
- Optimized for both general text generation and coding tasks
- General-purpose text generation and understanding
- Multilingual applications and translations
- Code generation and understanding
- Fine-tuning for specific domains or tasks
- Assistant-like interactions in chatbots and AI applications
- Long-form content creation and analysis
Getting started with LangChain and open-source LLMs in n8n
If running an open-source LLM seems too complicated, we’ve got great news: in n8n you can jump-start with Ollama. This powerful integration allows you to connect local models to real-world workflows and automate tasks in a meaningful way.
By combining the flexibility of open-source LLMs with the automation capabilities of n8n, you can build custom AI applications that are both powerful and efficient. LangChain (JavaScript version) is the main framework for building AI agents and LLM-powered workflows in n8n. The possibilities for customization and innovation are virtually limitless – use hundreds of pre-built nodes or write custom JS scripts.
Let’s explore how n8n makes creating custom LLM-powered apps and workflows easy!
There are at least 3 easy ways to build projects with open-source LLMs with n8n LangChain nodes:
- Run small Hugging Face models with a User Access Token completely for free.
- If you want to run larger models or need a quick response, try the Hugging Face service called Custom Inference Endpoints.
- If you have enough computing resources, run the model via Ollama locally or self-hosted.
LangChain nodes in n8n + Ollama integration make it easier to access open-source LLMs and give you handy tools for working with them. Here’s a video with an overview of the most important aspects:
After you’ve installed the self-hosted AI Starter Kit, it’s time for a practical part!
Here is a workflow template that is particularly useful for enterprise environments where data privacy is crucial. It allows for on-premises processing of personal information.
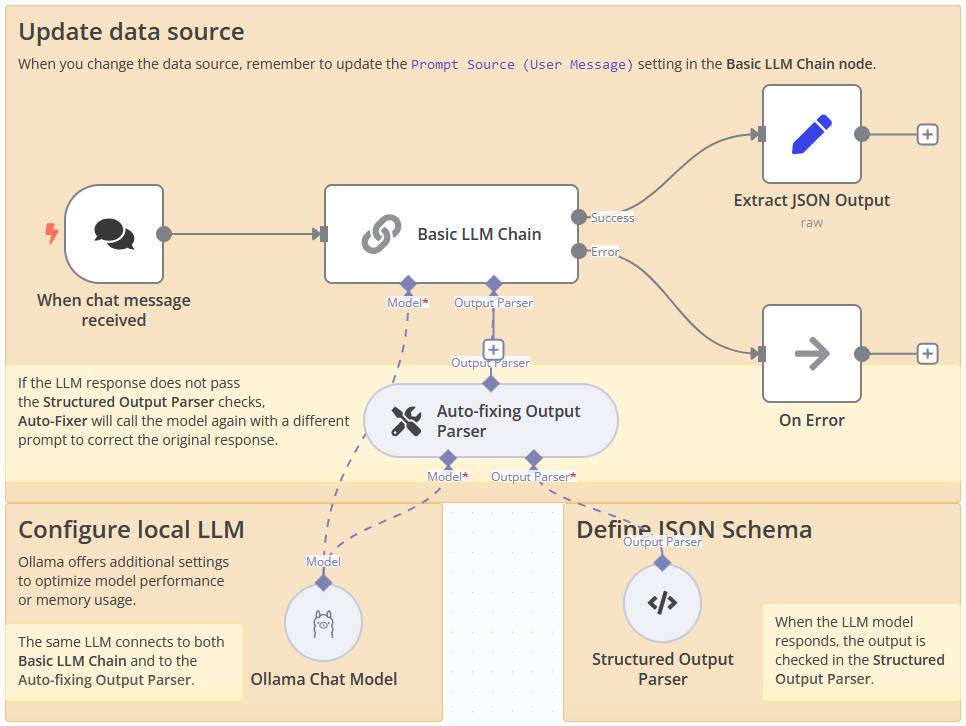
Step 1: Configure the Basic LLM Chain node

The core of the workflow is the Basic LLM Chain node. Configure it as follows:
- Activate the Require Specific Output Format toggle;
- In the Messages section, add a system message with the following content:
Please analyse the incoming user request. Extract information according to the JSON schema. Today is: {{ $now.toISO() }}This is the main prompt with the general task.
Step 2: Add the Chat Trigger node
For this example, we’re using a Chat Trigger to simulate user input.
💡 In a real-world scenario, this could be replaced with various data sources such as database queries, voice transcripts, or incoming Webhook data.
Step 3: Configure the Ollama Chat Model node

Connect the Ollama Chat Model node to provide the language model capabilities:
- Set the model to
mistral-nemo:latest - Set temperature to
0.1for more consistent outputs - Set keep Alive setting to
2hto maintain the model in memory - Enable the Use Memory Locking toggle for improved performance
Step 4: Ensure consistent structured output
- Add an Auto-fixing Output Parser node and connect it to the same Ollama Chat Model.
Add a Structured Output Parser node with the following JSON schema:
{
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "Name of the user"
},
"surname": {
"type": "string",
"description": "Surname of the user"
},
"commtype": {
"type": "string",
"enum": ["email", "phone", "other"],
"description": "Method of communication"
},
"contacts": {
"type": "string",
"description": "Contact details. ONLY IF PROVIDED"
},
"timestamp": {
"type": "string",
"format": "date-time",
"description": "When the communication occurred"
},
"subject": {
"type": "string",
"description": "Brief description of the communication topic"
}
},
"required": ["name", "communicationType"]
}
This JSON schema defines several JSON keys to collect various data like name, surname, communication method, user contacts, topic and the timestamp. However, only the name and the communication method are mandatory parameters. You can adjust the schema according to your needs.
Step 5: Process the output

After the Basic LLM Chain node processes the request, it will produce a JSON with an output key. Transform this output using a Set node:
Set the Mode to JSON
Use the following expression: {{ $json.output }}
Adding a Set node is optional, which we did just for convenience.
Step 6: Handle errors
Add a No Operation node after the Error output from the Basic LLM Chain node. This serves as an intermediary step before further error processing.
That’s it! Now you’re done and can test the workflow. Press the Chat button in the bottom middle part of your instance and provide a text message. For example:
Hi, my name is John. I'd like to be contacted via E-mail at john.smith@example.com regarding my recent order #12345.
You can easily adapt this template to various enterprise use cases by modifying the input source, output schema or post-processing steps.
If you have a specific storage system where you’d like to save the result, consider switching the Basic LLM Chain node to a Tools Agent node. Modern LLMs have built-in capabilities for function calling, so you can define the desired output format which can immediately connect to a database and upload the parsed information.
FAQs
Which types of open-source LLMs are there?
Open-source models fall into two main categories:
- Pre-trained LLMs are created using vast amounts of text data. These models excel at understanding broad contexts and generating coherent text. While valuable for research and general language tasks, they may struggle with specific instructions or specialized applications.
- Fine-tuned LLMs are adapted from pre-trained models. They undergo additional training on targeted datasets, making them more effective for particular use cases like classification, summarization, or question-answering. Fine-tuned models are essential for modern applications such as turn-based chat messaging and function calling.
Note that some authors distinguish fine-tuning from continuous pre-training. The latter involves further pre-training a model with domain-specific data, such as medical or financial reports, to adapt it to a particular field.
How to get started with an open-source LLM?
There are two main approaches to setting up and using open-source LLMs:
- Install locally. Helper tools such as Ollama simplify the process. However, the larger the model, the more difficult it is to meet the hardware requirements. The largest models require industrial-level equipment.
- Instead of hosting everything locally, it’s also possible to rent a virtual server.
VPS with a GPU allows for faster inference, but is more expensive. Several hosting providers have automated the process of model installation and deployment, so the entire setup requires just a few clicks and some waiting time.
Traditional CPU-only virtual servers could be a more cost-efficient alternative, especially when deploying smaller language models without strict requirements on response time.
How to run open-source LLM locally?
There are several ways to run LLMs locally. The easiest approach is to use one of the available frameworks, which can get you up and running in just a few clicks:
- Ollama + OpenWebUI: Ollama as a backend for quick LLM deployment, OpenWebUI as a user-friendly frontend
- GPT4All: General-purpose AI applications and document chat
- LM Studio: LLM customization and fine-tuning
- Jan: Privacy-focused LLM interactions with flexible server options
- NextChat: Building conversational AI with support for various LLMs
How much RAM do I need to run an LLM?
To work, most LLMs have to be loaded into memory (RAM or GPU VRAM). How much memory you need depends on multiple factors (model size, quantization, etc.) as well as specific use-cases (for example, simple inference vs fine-tuning).
Thanks to recent advances, some efficient small language models (SLMs) can run simple tasks on systems with just 4 GB of free RAM. During fine-tuning, however, the requirements increase, because you need to store intermediate steps while model parameter values are updated.
To check specific hardware requirements for an open-source LLM, look up its model card on Hugging Face, GitHub, or the developer's website. For quick estimates, you can use the "Can you run it?" tool for LLMs.
How much does it cost to run an open-source LLM?
While open-source models are free to use, the deployment and infrastructure costs vary. The main cost when running open-source LLMs is hardware. Here’s a concise breakdown of costs depending on different deployment options:
- Locally: free if your computer meets system requirements
- Managed API providers: free limited options or fees comparable to popular services like OpenAI / Anthropic
- Simple VPS: starting from $20/mo for CPU-only servers; GPU server prices are higher, up to dozens of dollars per hour
- Managed options with one-click install on GPU servers: premium pricing
Are open-source LLMs secure?
Open-source LLMs offer transparency but also present certain security challenges:
- Potential vulnerabilities: the publicly available model weights and architecture can attract both collaborators and potential attackers.
- Adversarial attacks: methods like data poisoning, prompt injection, and model evasion can alter input data to produce incorrect or unintended results.
- Wider attack surface: as open-source LLMs are integrated into more applications and platforms, the potential for attacks increases.
While the open-source community actively works on improving LLM security, users should implement additional safeguards. We recommend gating open-source LLMs during prototyping and rollout, making them accessible only through internal services (e.g. via n8n rather than directly by users).
Why to use open-source LLMs commercially?
We’ve gathered insights from real-world users on Reddit to understand why businesses choose open-source LLMs. Here are the key reasons:
- Efficient for simple tasks: smaller open-source models can handle basic text generation, classification, and function calling effectively.
- Data privacy: ideal for processing sensitive documents without relying on external cloud services.
- Integration with existing infrastructure: easy to incorporate if you’re already running ML models on your own GPUs.
- Cost-effective for high volumes: fine-tuning smaller open-source models can offer a better price-performance ratio for large-scale operations.
- Customization: allows setting your own guidelines to align with company policies and ethical standards.
- Transparency: offers the ability to review training data and understand the model’s architecture.
- Control over costs: prototyping with open-source models helps manage expenses before committing to specific providers.ntv
Wrap Up
In this article, we've highlighted that the best open-source LLM depends on your specific use case, as models like Llama3, Mistral, and Falcon 3 excel in different areas such as speed, accuracy, or resource efficiency. We emphasized evaluating models based on factors like task requirements, deployment setup, and available resources.
Additionally, we explained how tools like n8n and LangChain simplify integrating these LLMs into workflows, making it easier to experiment and find the right fit.
What’s next?
Now that you’ve got a grasp on using open-source LLMs with n8n, you can explore more advanced AI-powered automation scenarios. Many of the concepts we’ve covered in our other AI-related articles can be applied to local models as well.
Here are some resources to continue your journey:
- Learn about AI workflow automation trends;
- Create intelligent workflows with AI agents in n8n automation;
Build your own AI chatbot using n8n and Telegram.