Each large language model (LLM) has different latency profiles, cost curves, and capabilities. Many teams pick one and lock in. Early on, that instinct makes sense. At scale, it can drive costs and damage output quality. No single LLM is optimal for every query, user tier, and budget cycle.
LLM routing makes selection dynamic. Instead of a one-time configuration, each request routes to the most appropriate model based on task type, cost threshold, and performance requirements.
Model performance varies by task type — your model selection logic should, too. Discover how LLM routing works and which strategies to implement as your system grows in complexity and scale.
What’s LLM routing?
LLM routing is a pattern method that routes user queries to the best possible LLM. It uses an LLM router, which is a control-plane component that sits between your application layer and multiple LLM backends.
Rather than sending every incoming query to a single endpoint, the router analyzes each request and selects the most appropriate model. This is based on predefined criteria, including task type, cost threshold, and user tier.
A well-designed LLM router handles several responsibilities:
- Request analysis: Classifies the query by type, complexity, or domain
- Request forwarding: Routes the analyzed query to the selected model’s API endpoint
- Fallback handling: Detects failures, rate limits, and degraded responses, then reroutes automatically
- Response aggregation: Combines or selects outputs when multiple models are queried in parallel
- Logging: Records which model handled what, at what cost, and with what latency
Why LLM model routing matters in production
Frontier models can cost significantly more per token than smaller alternatives like GPT-4o mini or Mistral 7B. If half your traffic is simple summarization or classification, you’re paying that premium for work a cheaper model handles just as well. At 10 million daily queries, that differential isn't a rounding error — it's a line item that forces a decision.
Routing the right-sized language models also cuts latency for simpler queries. Users waiting on a fast-path response don't need to sit through inference time built for 70B parameter reasoning. Multiply that across millions of daily queries, and the time savings grow fast.
Then there’s the resilience argument. When a provider hits rate limits or degrades, a fallback route keeps the application running.
The organizational failure mode is often the last to get diagnosed. When one model handles everything, it’s harder to judge whether it's the right model for each task. For instance, a general LLM struggles with complex, multi-step math. This case is best left to reasoning-optimized models.
When queries contain sensitive data, routing those prompts to a local LLM stops being an optimization and becomes a compliance requirement. Quality works in the other direction: When simple LLMs handle complex queries, results can be inaccurate and inferior. Routing lets you route complex queries to models which are equipped to process them.
LLM strategies and use cases for routing
Routing strategies range from deterministic rules to trained classifiers, and the right choice isn't always the most sophisticated. It's the one that fits your current problem with acceptable on-going costs. Here are a few to consider.
Static routing
Most production routing starts here, and many never need to go further. Static routing uses predefined rules: Task type X goes to model Y, full stop. It’s simple, fast, and easy to debug. The trade-off is brittleness. Static instructions require maintenance as task distributions shift, and edge cases the model didn’t expect can be processed incorrectly.
For companies with well-defined, predictable use cases, static routing isn't a compromise — it's the right call. Teams need to move tasks to unique LLMs, like routing code generation to a specialized coding model and open-ended Q&A to a general-purpose LLM. The quality gap between general and specialized models on specific tasks is real and measurable, and a router is what lets you exploit it systematically.
Dynamic routing
When task diversity outgrows what static rules can handle, dynamic routing uses a classifier or prediction model to evaluate each query at runtime. RouteLLM from Berkeley's LMSYS group is the most rigorous public example. This system trains a small router on preference data to decide when a cheaper model can match a stronger one's quality. It adds inference latency through processing, so you’ll only see significant savings at sufficient volume.
A lightweight classifier scores query complexity at the routing layer. If the score clears a threshold, the request escalates to a frontier model. If it doesn't, a cheaper, faster model handles it. This is the core insight from RouteLLM and similar algorithms: The majority of real-world queries don't require the most capable model available. Routing them doesn't compromise quality — it prevents wasting capability on tasks that don't need it.
Semantic routing
This method uses embeddings to map incoming queries to task clusters, then routes them to domain-optimized model endpoints. It works well when task types are semantically different. For example, code generation is significantly distinct from open-ended conversation.
The operational challenge is equally important: As the types of queries you process change over time, the embedding clusters become less accurate. Someone has to monitor drift, revalidate cluster boundaries periodically, and decide when the routing model needs retraining against updated data.
Queries containing PII, financial data, and health information may use semantic routing to move to on-premise or locally hosted models rather than cloud APIs. At many organizations, this isn't an optional optimization. Regulations like HIPAA and GLBA mandate rigid access controls and auditability, and semantic LLM routing architecture is the simplest way to comply. Get the rules wrong, and the enforcement gap doesn't show up until an audit.
Cost-based and failover routing
In practice, teams often combine these two methods into a baseline layer that sits beneath more specialized routing logic. Cost-based routing selects models dynamically based on real-time pricing or per user budget caps. This enforces computational costs at the query level rather than discovering overruns in aggregate billing. Failover routing monitors provider accessibility and reroutes when a primary model is unavailable or returning degraded responses.
For example, premium users get faster, more capable models. Free-tier users get cost-optimized responses. The routing decision happens at the session level — before a single token is processed — based on subscription status or service level agreement (SLA) tier. You get premium model performance where it matters and controlled cost where it doesn't, without maintaining two separate pipelines.
Cascading
A related cost-based pattern is cascading, where the system starts with the cheapest model and escalates to more capable ones only when the output doesn't meet a quality threshold. FrugalGPT (Chen et al., 2023) demonstrated this approach can match frontier model quality at significantly lower cost by avoiding expensive models for queries that don't need them.
Engineering trade-offs and challenges
LLM routing adds a layer to your stack, and that layer has a maintenance surface many teams underestimate. Here are a few obstacles to keep in mind:
- Classifier drift: This is the most common long-term failure mode. Task distribution shifts — like new prompt patterns, updated models, and changing user behavior — mean a routing classifier trained six months ago may no longer segment correctly. Training and evaluation aren't one-time tasks. They’re recurring operational work that needs explicit ownership and scheduled benchmarks to stay accurate.
- Multi-provider credential management: Each LLM backend has its own API keys, rate limits, and pricing model. Keeping that configuration synchronized is solvable. A secrets manager and shared config layer handle most of it, but someone has to own it. Some teams use OpenRouter, a unified platform that provides access to hundreds of LLMs.
- Observability: Black box LLMs don’t allow troubleshooting and workflow improvement. You need to know which model handled a request, at what cost, and whether the routing decision itself was correct.
Start routing simply with n8n
LLM routing is a response to specific, diagnosable failure modes, not an architectural pattern to adopt preemptively. Adopt it when cost escalation, quality degradation, or provider dependency risk is visible in your current system. Start with a simple strategy, and move forward as your needs grow. If you’re looking for a system that scales with you, try n8n.
n8n sits at the orchestration layer. Routing logic isn’t buried in custom code; it’s a visual, version-controlled workflow. The Model Selector node and native integrations across providers like OpenAI and Anthropic let you define which model handles different request types — without a deployment cycle.
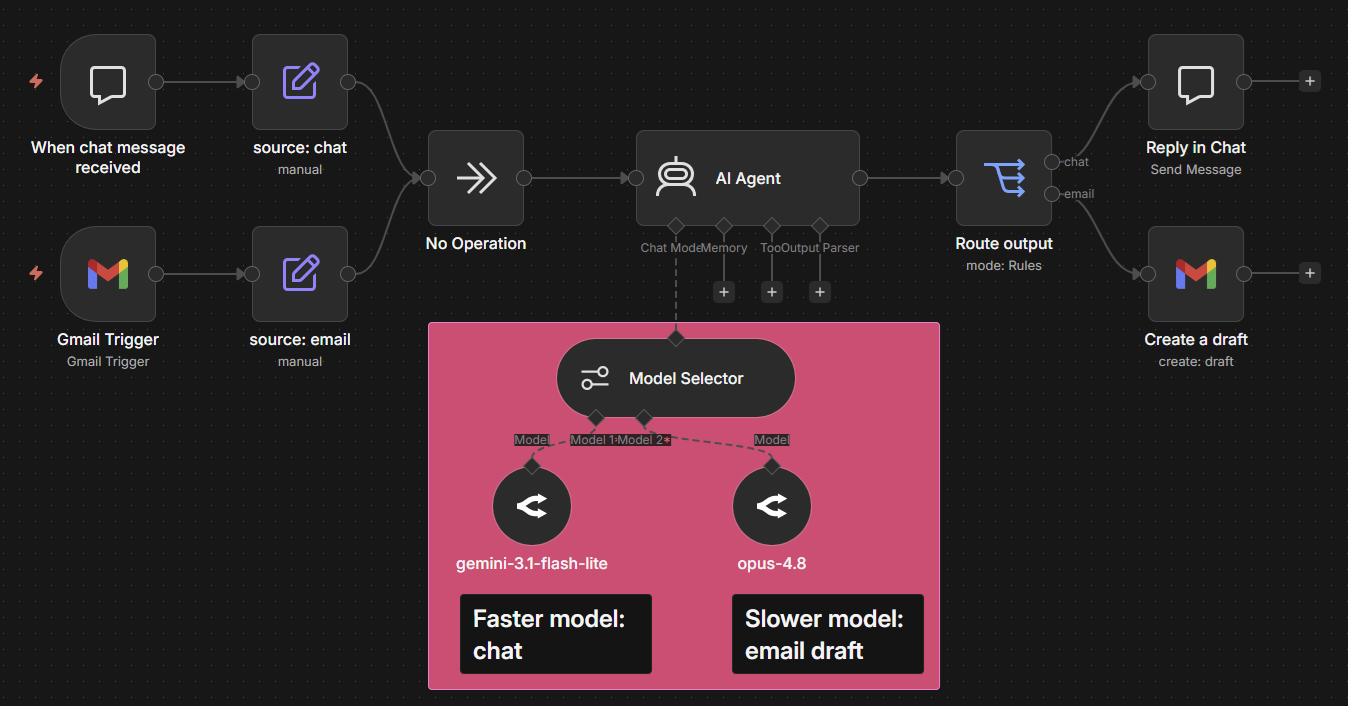
An AI Agent node with tool-calling let you manage the conditional logic that routing depends on. When the routing classifier drifts, execution history shows you exactly where the decision went wrong. When the routing architecture needs to evolve — because it will — n8n makes that change a workflow edit, not a rewrite.
Check out the Agent Decisioner workflow from the gallery, featuring over 9,000+ n8n templates, to see how you can process dynamic, smooth responses for any query with n8n.