In development, an AI agent calling an external API feels effortless. But in production, it’s more of a liability. Leaving error handling for LLM tool calls entirely to the model itself guarantees automated pipelines will break the moment a connected service drops or misbehaves.
This guide maps out a multi-layered defense strategy, including failure types, retry and fallback strategies, and model-level error reasoning. These architectural blueprints will show you how to build resilient, production-ready agents.
Classifying tool failures: What to retry vs. what to escalate
Conflating retryable and non-retryable tool failures is one of the fastest ways to break production agents. When a tool call fails, the system has to determine the cause instead of blindly submitting the request or throwing a generic exception.
This operational logic requires dividing recovery responsibilities between two layers: the orchestration layer and the LLM itself. The orchestration layer owns silent, infrastructure-level retries for transient issues. The model owns reasoning-based recovery when an application-level problem requires a pivot in the agent's behavior.
Production failure categories
Cleanly separating these systemic blocks requires looking at production failures through four distinct categories and mapping each to its proper recovery layer.
Transport and network failures
Dropped TCP connections, temporary DNS resolution timeouts, and standard HTTP “503 Service Unavailable” responses are examples of infrastructure-level disruptions. These issues are entirely transient and external to the application logic. So the orchestration layer should intercept them and handle recovery silently through network-level retries. The underlying LLM shouldn’t know a transport error occurred.
External service errors
This category covers instances where the downstream API is reachable but rejects the request. This is due to upstream operational constraints, such as hitting a rate limit (429 Too Many Requests) or experiencing an internal platform crash (500 Internal Server Error). The orchestration layer owns this recovery process. It needs to inspect the response headers, extract throttling instructions, and delay execution accordingly before attempting a retry.
Input validation failures
These failures happen when an upstream service or database rejects a tool call because of a schema mismatch, missing required parameter, or invalid data format (400 Bad Request). Because the payload itself is structurally incorrect, the orchestration layer can’t repair it. The model must read the error, adjust its reasoning, and produce a corrected request. This keeps the workflow stable because the agent fixes the root cause instead of repeating the same invalid call.
Logic errors and unexpected output format
This category includes situations where the downstream tool executes successfully at the network layer but returns an application-specific error. Examples include a database query returning zero records or an API yielding an unparseable, malformed JSON string. The model layer owns recovery here. The agent must ingest this unexpected output to reason through the operational failure. From there, it dynamically decides its next step, whether that means altering its execution path, swapping to a backup fallback tool, or escalating the issue directly to a human.
System-level retry mechanics
For transient transport and external service errors, the orchestration layer has to enforce a structured retry mechanism to prevent overwhelming downstream APIs. The production standard relies on exponential backoff combined with full jitter. This ensures retry attempts are progressively spaced out and mathematically randomized to avoid a "thundering herd" problem. The system should also actively parse standard Retry-After headers sent by throttled endpoints, overriding default intervals to stay compliant with third-party rate limits.
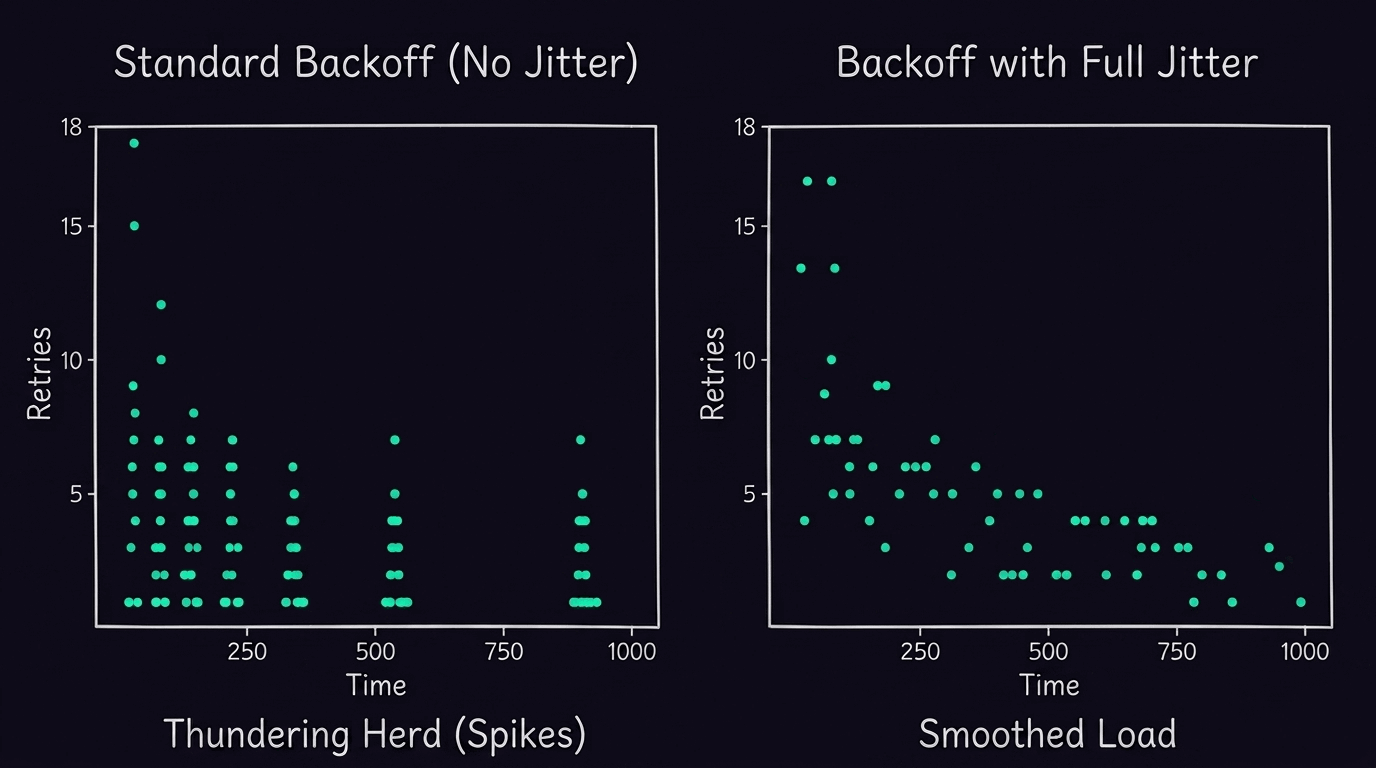
Resilience patterns for tool calling failures in production
When automated system-level retries fail to resolve an issue, your production stack needs a defined fallback path to prevent the entire run from crashing. Some failures require the orchestration layer to route around a dead service. Other structural failures require the model to actively reason through the problem and adapt. Rather than treating these layers as opposing design methodologies, production-grade agent architectures deploy them them next to each other.
Structured error messages as tool results
When an external tool throws an exception, developers are often tempted to catch it, stop the execution string, and abandon further error handling. A more resilient pattern is to format that application error into a clean, structured string, pass it back as a tool result, and associate it with the original tool call id. By returning the raw exception context directly to the execution graph, you allow the model to read the error message as data and intelligently formulate its next step.
Handling schema mismatches and hallucinated tool names
Even with strict system prompts, an LLM will occasionally invoke a function name that doesn’t exist in its runtime definitions or emit a payload that violates JSON schema. This is a common hurdle when implementing LLM function calling, where a model struggles with structured constraints. If the framework passes this malformed call, it causes a crash. Instead, the orchestration layer should intercept the invalid call and inject a corrective feedback loop directly into the conversation history:
[LLM calls non-existent tool: "Fetch_User_Data_v2"]
↓
[Orchestration Layer catches error and appends system message]
"Error: Tool 'Fetch_User_Data_v2' does not exist. Available tools are: ['get_user_profile', 'update_user']."
↓
[LLM reads correction context, auto-corrects runtime logic, and invokes 'get_user_profile']
Bounding model recovery loops
Allowing an agent to inspect its own errors and retry tool execution is incredibly powerful. But without strict boundaries, it introduces a new risk. If an LLM encounters a persistent logic error, it can enter a loop, repeatedly calling the same broken tool and rapidly consuming your token budget.
To prevent these infinite execution loops, your orchestration layer needs to enforce a hard counter on model retries. The system should truncate the loop and raise an explicit system alert once a pre-defined threshold (typically three attempts) is exceeded.
Model and tool fallback chains
When a primary external system goes offline, a model shouldn't fail. You can design fallback chains at both the model layer and the tool layer to guarantee high availability. For example, if your premium foundational model experiences an outage or a severe rate limit mid-task, your orchestration canvas can swap the execution context to a secondary cloud provider or a local open-source alternative. Similarly, if your primary CRM tool call keeps failing, the pipeline can catch the failure and route the payload to a secondary backup database tool.
Graceful degradation
Not every tool failure needs to kill an active session. If an agent's primary task is to generate a comprehensive market report and its translation tool fails, the system should practice graceful degradation. The orchestration layer can catch the tool error, append a note stating that the translation module is temporarily unavailable, and instruct the model to output the final text in its native language. Delivering a partially completed, high-value asset is almost always preferable to returning a blank error page to an end user.
Circuit breakers
When an external dependency undergoes a prolonged outage, continuing to bombard it with automated retries wastes network infrastructure resources and subjects your system to long timeout delays. Implementing the circuit breaker pattern prevents this by tracking sequential failures across all active agent runs.
The circuit breaker operates as a distributed state machine directly inside your workflow layer, completely isolating broken dependencies until they’re confirmed healthy again. In code-first frameworks, setting this up requires building custom, stateful middleware or pulling in complex, dedicated infrastructure libraries. But with a visual automation platform, you can design and wire the entire state machine directly into the workflow layout without adding much infrastructure overhead
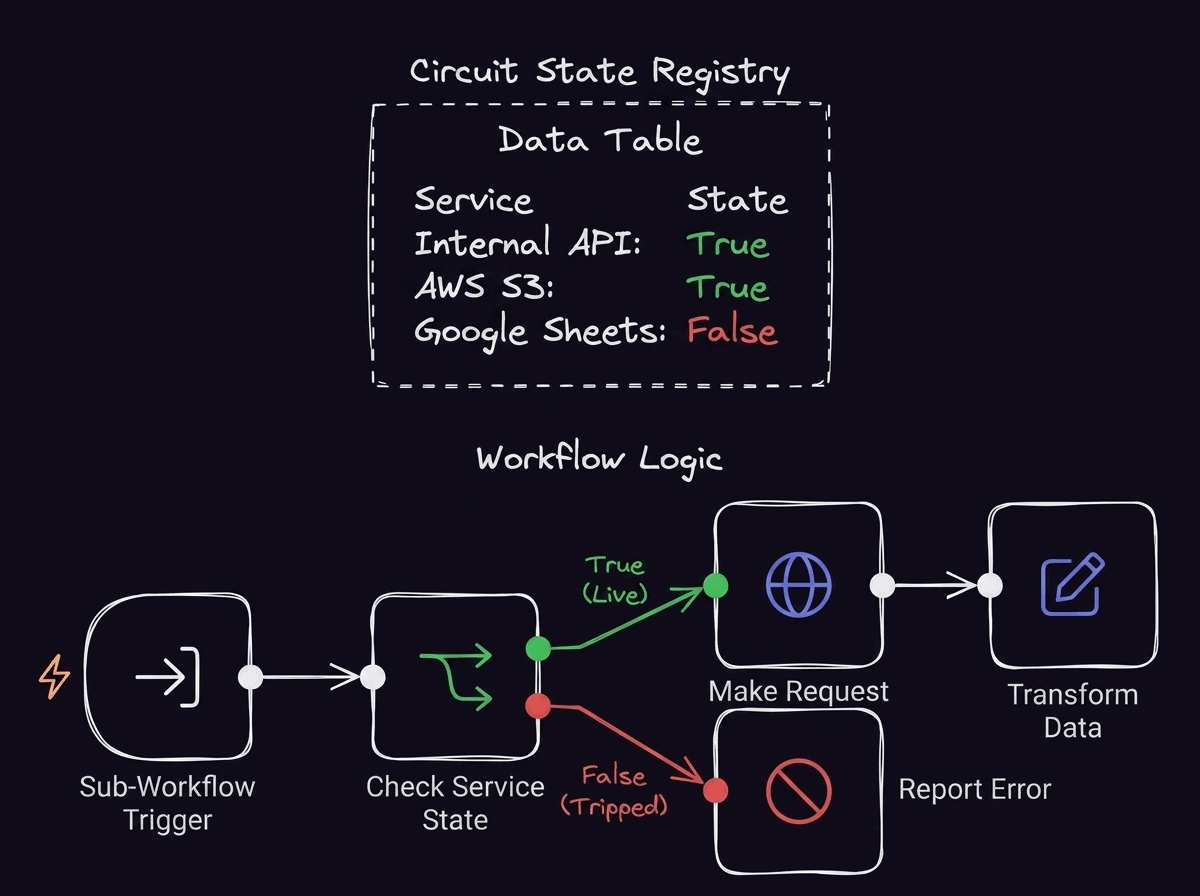
Implementing tool error handling in n8n
Troubleshooting an AI agent tool calling failure without LLM traces usually forces you to dig through mountains of messy terminal logs. n8n is a workflow automation platform that simplifies this cycle by bringing your execution data onto a visual canvas. The software surfaces in a single visual execution trace which LLM tool call failed, why, and what parameters the LLM attempted to pass. This provides production-grade reliability without heavy DevOps infrastructure.
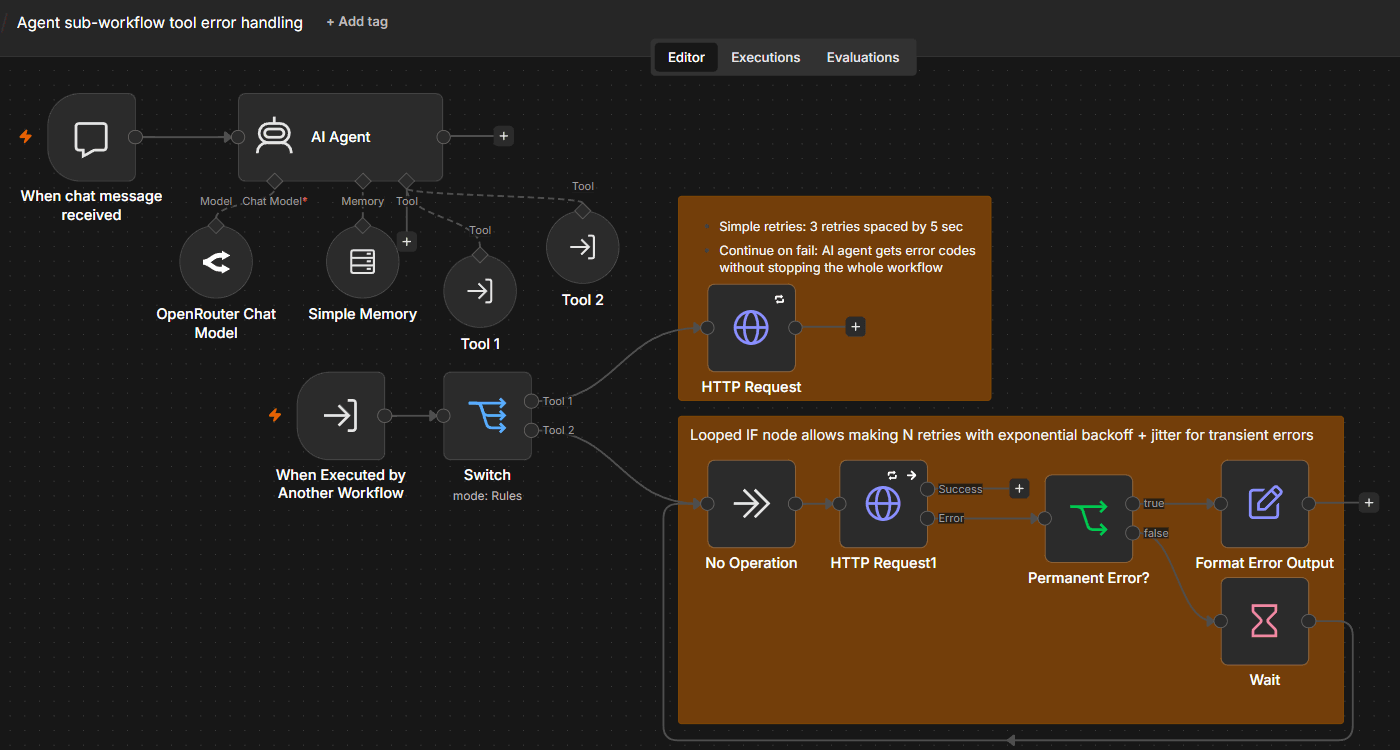
You can implement these resilient tool patterns natively on the canvas. Note, that a fully featured implementation will require wrapping AI Agent tools into sub-workflows. There are three core platform features to use:
- Node-level retry configuration: Toggle automatic retries directly inside any individual node's settings. You define the maximum attempts and wait times. n8n handles simple backoff mechanics for transient drops behind the scenes before an error ever reaches your active AI Agent node. For more advanced retry strategies, use the looped IF node with the upper limit of retries.
- Error workflows and conditional fallback routing: Route a node's explicit error path directly into downstream IF or Switch nodes. If a primary API tool fails, n8n captures the error payload and dynamically reroutes execution to a backup sub-workflow or a secondary tool, ensuring your core LLM tool calling mechanics remain uninterrupted.
- Observability for failed tool calls: Isolate bugs instantly via the visual execution trace panel, which maps out input parameters, raw JSON payloads, and HTTP status codes for each step. Note that while n8n exposes tool inputs and outputs, optimizing a function-calling LLM context or viewing full model-level hidden reasoning traces still require an external telemetry layer like LangSmith.
Start building resilient AI agents with n8n
Building reliable, production-grade agents requires a layered defense strategy that treats error management as an architectural pillar. By combining system-level retries for transient network drops with model-level feedback loops for logic failures, n8n ensures your workflows remain stable under real-world pressure.
With visual execution traces that show each step and reveal where a failure occurred, n8n removes guesswork and makes debugging straightforward. It also provides a clear path to production. Each workflow includes execution history, scheduling, and built-in agent error handling, so teams can move from prototype to stable deployment without extra infrastructure.
Explore n8n’s advanced AI Agent node to start building resilient automation pipelines without the heavy infrastructure code.