What I assume for future is
- Websites → Agents
- Rest API → MCP
- Apps → Mini apps that run in Agents
- App Stores → MCP with built-in mini UI/UX that supports agents’ mini app SDK
A Reddit user envisioning how MCP will create web 4.0, colorized (2025)
Most no-code automation tools—including n8n—have naturally entered the AI agents market, which makes complete sense. However, since OpenAI's involvement sparked a significant uptick in adoption, MCP has been positioned as the superior approach to building AI agents.
MCP is a great initiative, but also immature and therefore prone to tantrums. Just look at the authorization and general security lacklustre of the protocol’s first iteration (Nov 2024 - Mar 2025). The immaturity of the protocol and really quick adoption by the market give us a patchy and inconsistent experience.
Here are some MCP conversations I expect in the near future:
- Security will become the responsibility of vendors
- Model supply chain security
- Cost management
- Backward compatibility shenanigans
- Orchestrating MCP agents
Let's now dive into each of these challenges and explore what they mean for teams considering MCP in production environments!
Security is the vendors' responsibility
Vendors are exposing their products to end-users by offering their own MCP servers. This means that users can interact with the product via the LLM. Whichever way you spin this, it is the vendor’s responsibility to enforce secure access from third parties to their product. In this case, security must be implemented at the server level.
So, do vendors now care about the MCP-level security? No! As the Equixly folks found:
- Command Injection Vulnerabilities: 43% of tested implementations contained command injection flaws
- Path Traversal/Arbitrary File Read: 22% allowed accessing files outside intended directories
- SSRF Vulnerabilities: 30% permitted unrestricted URL fetching
I make some points below about backward compatibility, which means that implementing security at the MCP server itself may require constant revisiting as the protocol evolves. One option is to implement security in a proxy layer, such as at an API gateway as suggested by the solo.io CTO, albeit the suggesting being obviously biased.
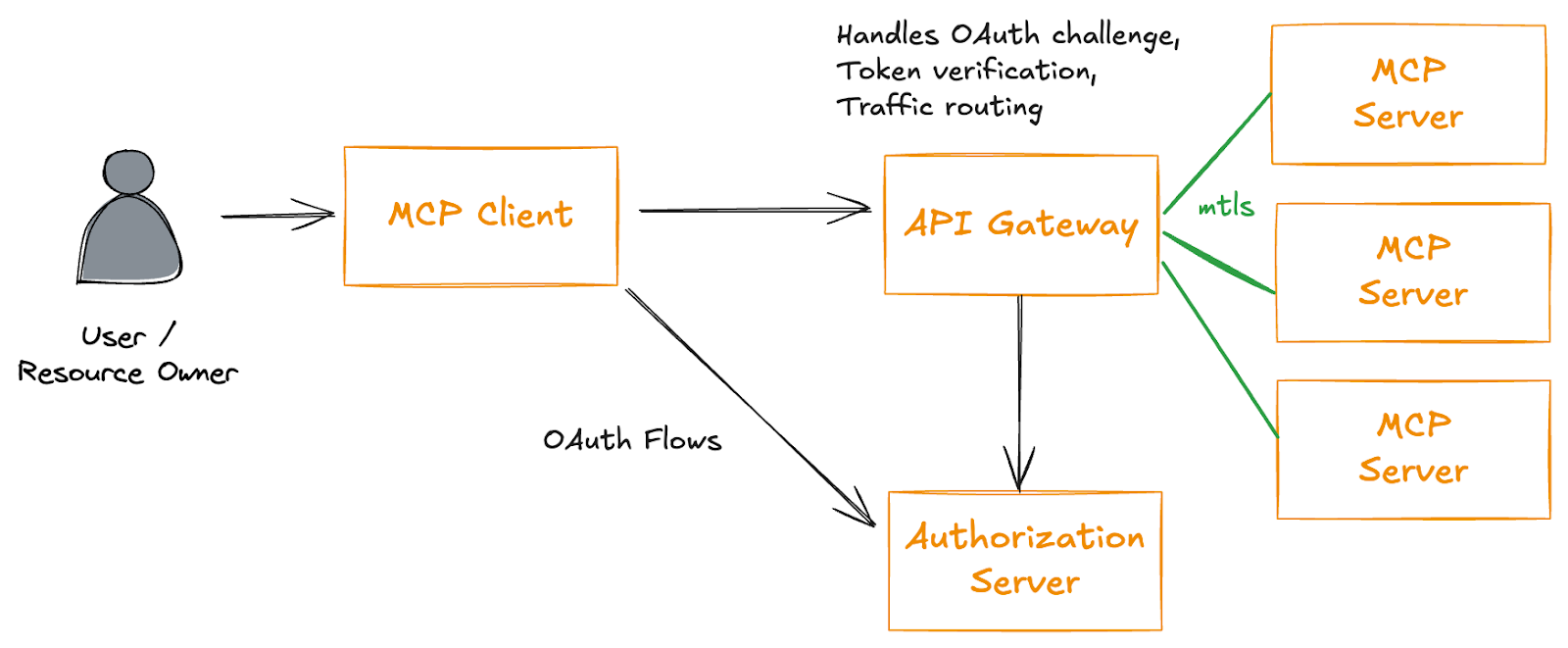
It’s quite funny to inject an API gateway in between MCP resources when the whole point was to not rely on APIs anymore!
What we expect:
Security enforcement may impede MCP ease of use so much to the point where it won’t be feasible to use it. If security policies restrict Agent workflows from doing their autonomous thing, then we may as well take the MCP servers down altogether.
Model supply chain security becomes increasingly important
Let’s assume you have a genuine, but compromised user. They would likely satisfy all the authentication and authorization conditions, but the model they use is contaminated. How to Backdoor Large Language Models shows an example of how a polluted model can include a malicious script.
If you remember the XZ Backdoor, a contributor built a trustworthy profile over two years, and then gradually implemented the backdoor in the XZ Utils tool. This may very well happen with open source LLMs.
What we expect:
We expect formal enforcement of approved models when accessing MCP servers. Other approaches may implement some detection algorithms for the responses submitted by the model.
Cost management
Tokens dictate how the bill for GenAI APIs is calculated. So we’ve got two opportunities for the agent to eat up your costs:
- The Agent is terribly inefficient at writing a single and effective request, especially for reasoning models.
- Pulling large amounts of data eats up context.
The diagram below is a great representation of the first point.
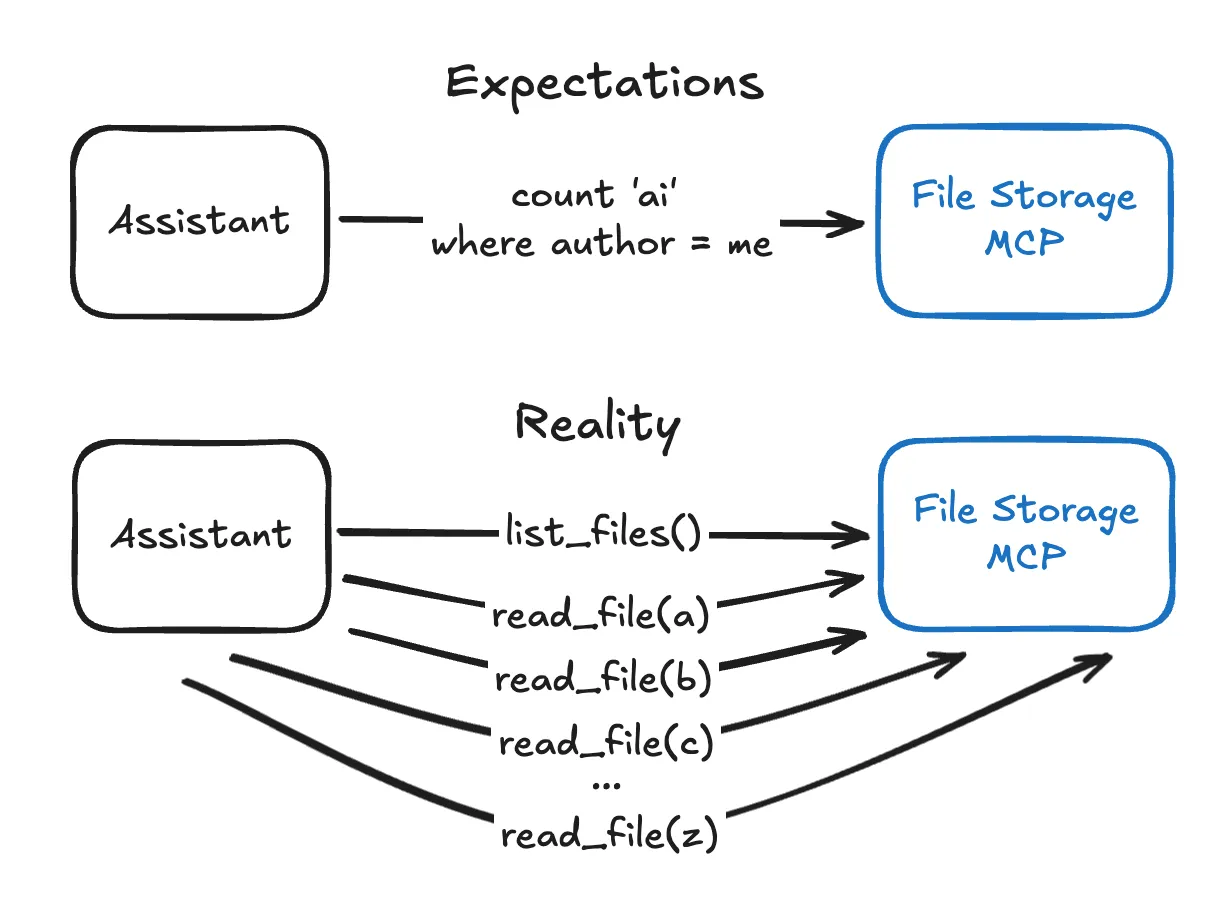
To manage cost, you should optimize the API for use with MCP. This article does a great job of explaining how to do that. I’m not an API engineer (and I don’t know how to code), so I’m being transparent and saying that I asked Claude to rewrite the examples using generic terminology rather than the article’s Theme Park API.
- Pre-process and structure API data to better fit model queries: Instead of exposing raw or deeply nested data, restructure and simplify the API responses to make it easier for an LLM to extract relevant information quickly. Flattening or inverting the data hierarchy reduces the token count and parsing complexity during inference.
- Filter data as close to the source as possible to minimize payload size: Instead of returning large datasets and letting the LLM sift through them, implement API methods that allow precise filtering based on input parameters, returning only the minimum necessary information for the task at hand.
- Remove redundant or overly broad endpoints to guide the LLM toward optimized interactions: Prune or disable generic API methods that return bulk or unfiltered data, even if they seem convenient. This prevents the LLM from making inefficient calls that inflate token usage and ensures that it consistently uses the most efficient pathways you’ve designed.
What we expect:
For MCP to be financially feasible, all server providers need to optimize their API usage. All-in-all, MCP is still an API wrapper.
High adoption and backward compatibility shenanigans
With everybody jumping on the bandwagon while the protocol is in its infancy, I expect the following:
- A whole lot of real-world edge cases and vulnerabilities
- A whole lot of discussions about improvements and developments
- A whole lot of rip-and-replace feature releases
Expect constant and consistent management of your MCP infrastructure.
For example, replacing HTTP+SSE with new "Streamable HTTP" transport introduces the Streamable HTTP transport for MCP, addressing key limitations of the current HTTP+SSE transport. This approach is stated to have backwards compatibility. But to maintain backward compatibility with the deprecated HTTP+SSE transport, clients and servers may take the following measures:
Servers supporting legacy clients:
- Continue hosting the old transport's SSE and POST endpoints alongside the new "MCP endpoint" defined for the Streamable HTTP transport.
- Alternatively, merge the old POST endpoint with the new MCP endpoint, though this may introduce unnecessary complexity.
Clients supporting legacy servers:
- Accept user-provided MCP server URLs, which may point to servers using either the old or new transport.
- Attempt to send a POST InitializeRequest to the server URL, including the Accept header.
What we expect:
MCP requires ongoing management, not just for handling security, but to handle the infrastructure itself. This will require dedicated processes, workflows, and perhaps an AI Infrastructure Ops.
Orchestrating MCP agents
MCPs are great for single-platform queries such as extracting video transcriptions, but they break down for complex, multi-source AI workflows. You can only use one MCP at a time, meaning LLMs struggle to combine multiple data sources. The guys at suada.ai hit this exact issue when trying to pull data from multiple sources at once, where MCP didn’t allow them to reliably query Slack, Linear, Notion together. So they built a custom solution that lets AI reason across multiple integrations dynamically.
I’ve spent a good few hundred hours evaluating what makes a good AI agent, and multi-agent, architectures and orchestrator agents were some high-ticket items.
n8n and their counterparts have a good opportunity here to handle multiple agents, MCP calls, and data sources.
What we expect:
MCP by itself does not make an Agent. You need additional logic to handle complex tasks suited for multi-agent use cases.
Future of MCP
The likelihood of the current MCP incarnation being used in production in two years is very low.
MCP is setting an expectation for end-user experience, namely, how well and easily the LLM can interact with third-party services. I expect that the industry will take all the lessons learned from the MCP exercise and provide a more secure and API-based alternative.
A likely candidate to do that will be Google, considering their pedigree of defining protocols such as gRPC and QUIC. Google’s A2A work, which is positioned to be complementary to MCP, is already more secure. Adding MCP-like capabilities in A2A is to be expected.