Ever wondered just how hard you can push n8n before it starts waving the white flag? We pushed n8n to the limits, with impressive results.
When you’re running mission-critical workflows, you need to know your limits. So we recently put different n8n deployments through their paces – simulating heavy traffic and maxing out resources to see which setups come out on top.
Whether you're running a side hustle or managing engineering for a multi-national organization, stress testing goes a long way to preventing downtime, bottlenecks, and broken promises. This benchmark blog and video will show you exactly how far n8n can go, and where it starts to fall apart!
A Workout for your Workflow
We stress tested n8n across two AWS instance types – C5.large and C5.4xlarge – using both n8n’s Single and Queue modes (multi-threaded, queue-based architecture). We used K6 for load testing, Beszel for live resource monitoring, and n8n’s own benchmarking workflows to automatically trigger each stress test scenario.
This workflow used a spreadsheet to iterate through different virtual user (VUs) levels, running each test and recording the results as it went. Once the data was logged, we turned it into a graph that revealed key performance indicators. Plus, in real-time we could see how well the system performed under varying loads – how fast it responded, how reliably it executed, and where it started to crack.
Here’s how we set it up:
The C5.large AWS instance comprised:
- 1 vCPUs
- 2 Threads
- 4 GB RAM
- 10 Gbps bandwidth
When we scaled up to the C5.4xlarge, we added 16 vCPUs + 32 GB RAM.
We ran three critical benchmarking scenarios:
- Single Webhook: one flow triggered repeatedly
- Multi Webhook: 10 workflows triggered in parallel
- Binary Data: large file uploads and processing
Each test scaled from 3 to 200 virtual users to measure:
- Requests per second
- Average response time
- Failure rate under load
If you’re keen to set up your own stress testing, we’ve included all the tools you need to get started at the end of this blog, including the n8n Benchmark Scripts.
Single Webhook
We started small with a single webhook. This mimicked sending a web hook request to an n8n server and sending a response back that we received that webhook call. This was just one workflow, and one endpoint, gradually ramping up traffic to see how far a single n8n instance can be pushed.
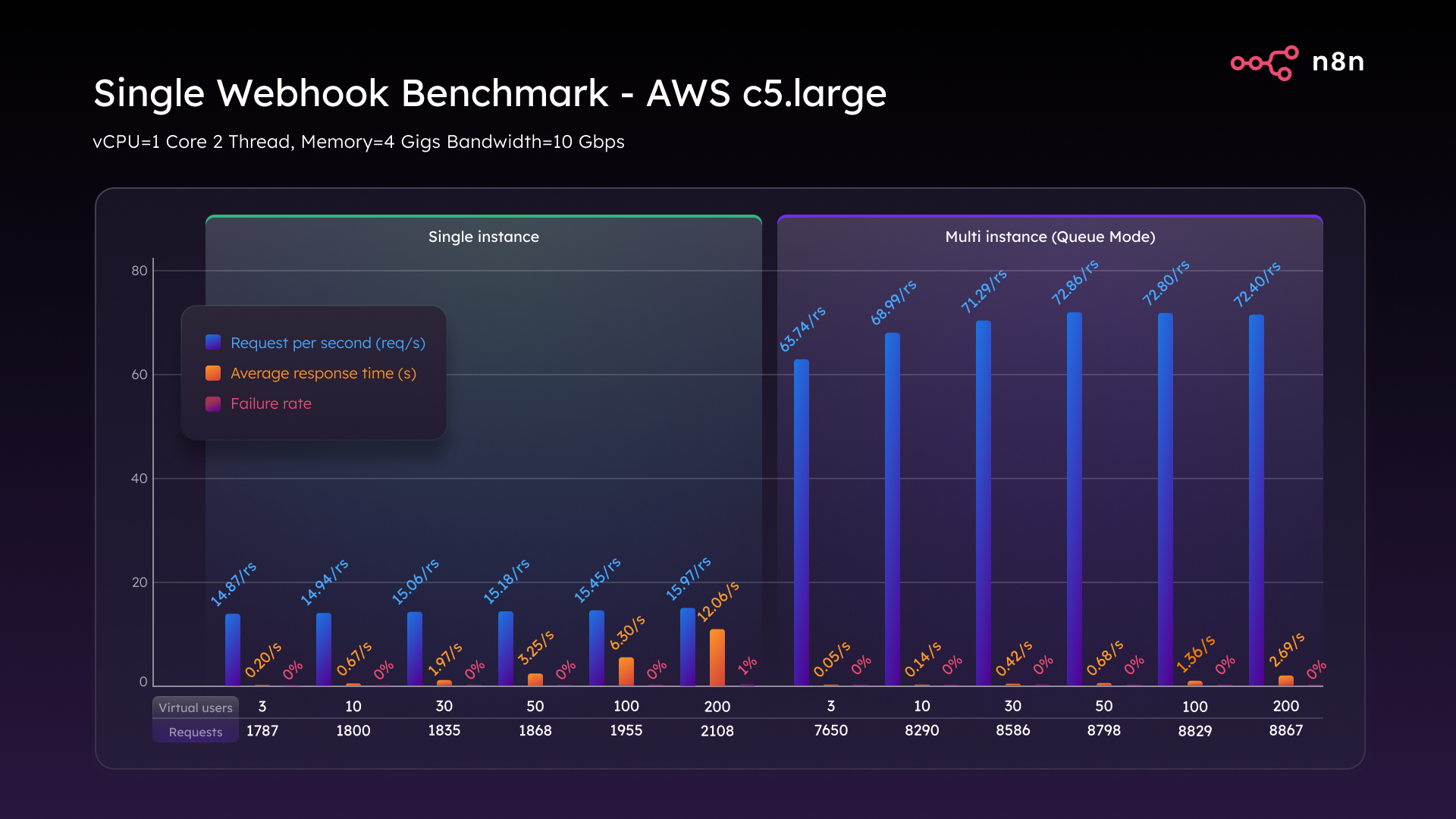
Using a C5.large AWS instance the n8n Single mode deployment handled the pressure surprisingly well, as you can see from the comparison table below. While this instance held up to 100 VUs, once we reached 200 VUs we hit the ceiling for what a single-threaded setup can manage, with response times up to 12 seconds and a 1% failure rate.
When we enabled Queue mode, n8n’s more scalable architecture that decouples webhook intake from workflow execution, performance jumped to 72 requests per second, latency dropped under three seconds, and the system handled 200 virtual users with zero failures.
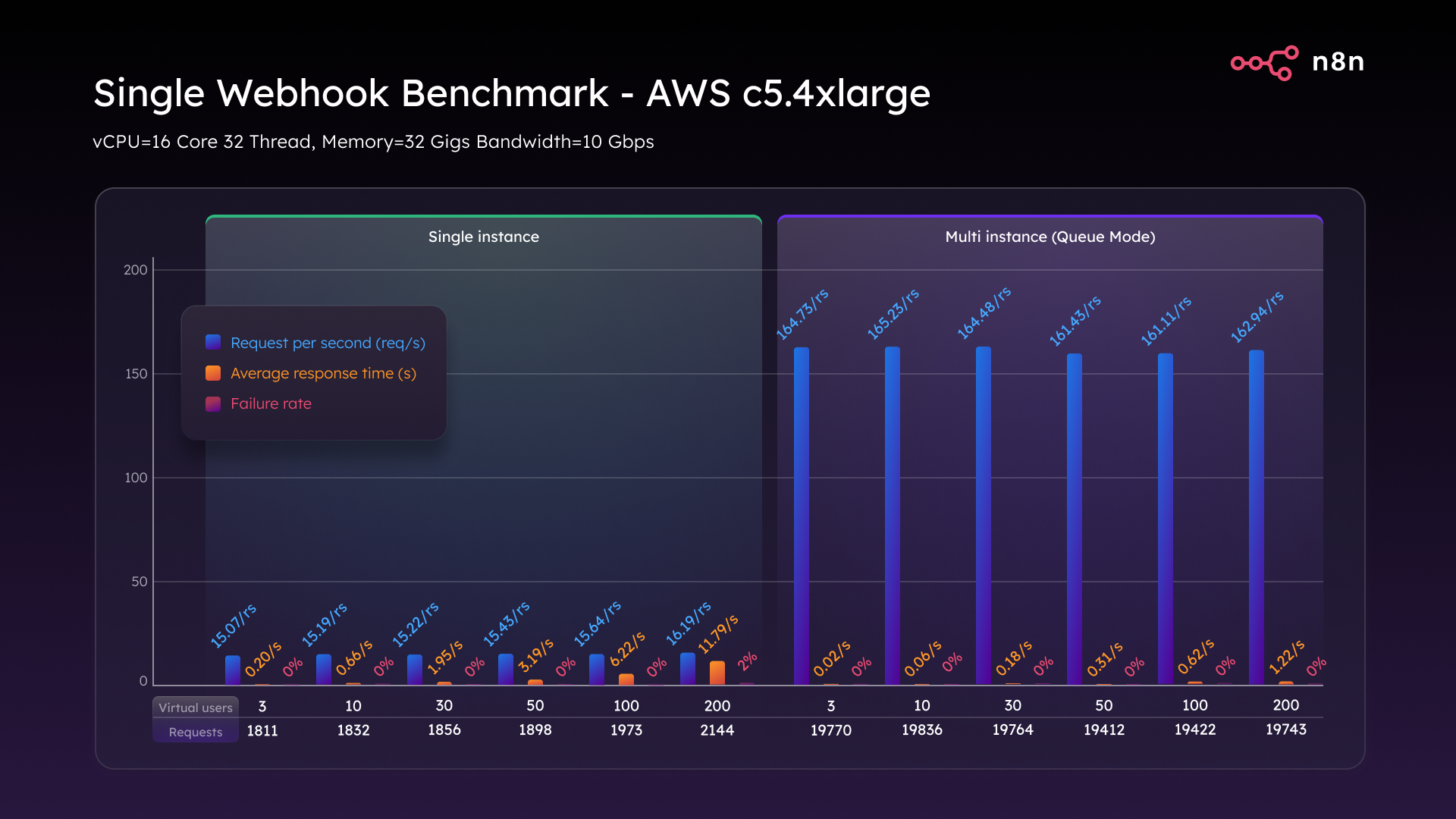
Scaling up to the C5.4xlarge (16 vCPUs, 32 GB RAM) we saw some impressive gains. In single mode, throughput rose slightly to 16.2 requests per second with modest latency improvements.
But it was Queue mode that really stole the show. We hit a consistent 162 requests per second and maintained that across a full 200 VU load, with latency under 1.2 seconds and zero failures. That’s a 10x throughput gain just by scaling vertically and choosing the right architecture.
Multiple Webhooks
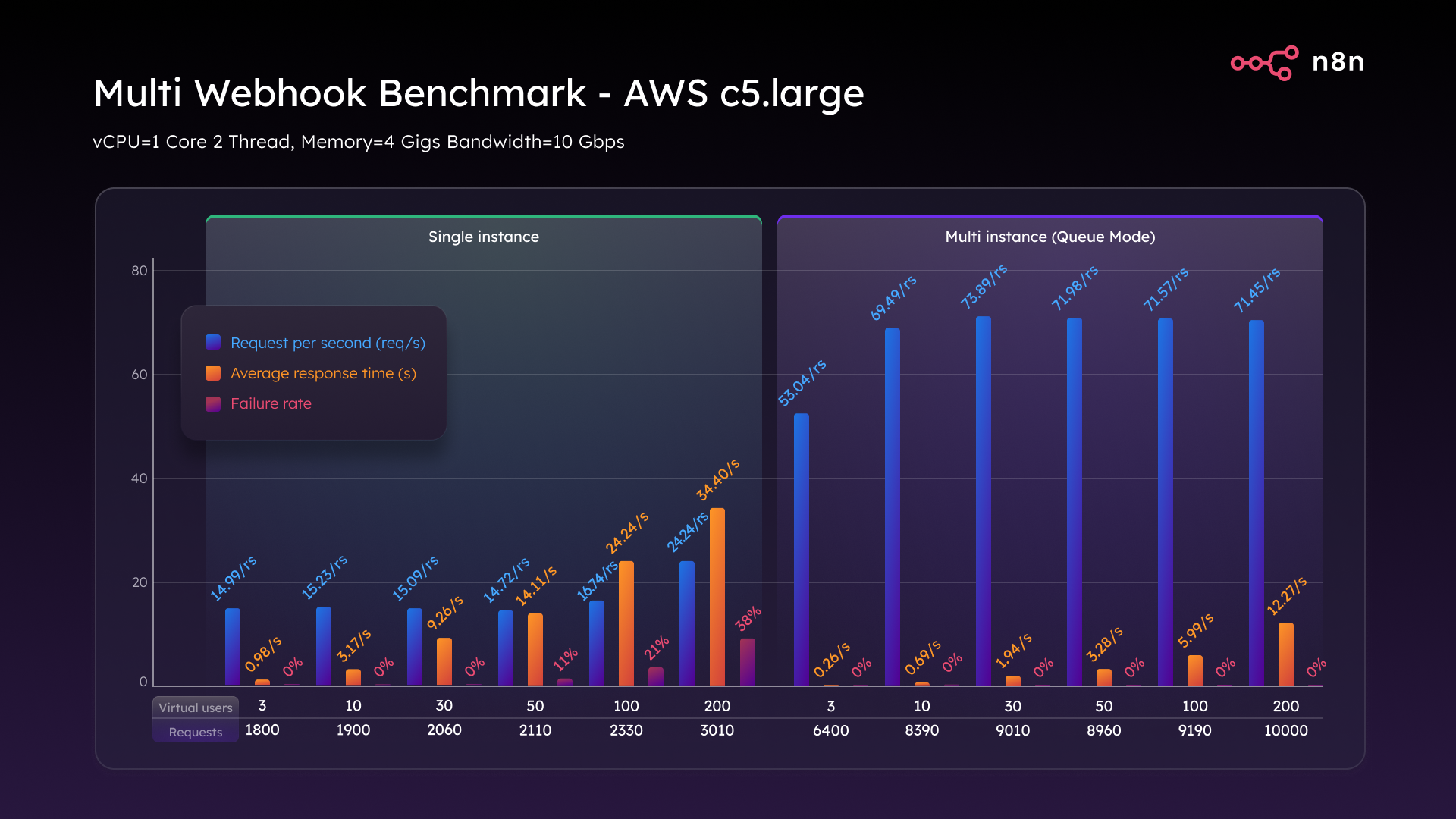
For the next test, we wanted to simulate enterprise-grade multitasking to better reflect real-world n8n deployments, so we set up 10 distinct workflows, each triggered by its own webhook.
On the C5.large in single mode, performance fell off quickly. At 50 VUs, response time spiked above 14 seconds with an 11% failure rate. At 100 VUs, latency reached 24 seconds with a 21% failure rate. And at 200 VUs, the failure rate hit 38% and response time stretched to 34 seconds – essentially a meltdown.
Switching to Queue mode changed the game. It sustained 74 requests per second consistently from three to 200 VUs, with latency within acceptable bounds, and a 0% failure rate. Same hardware, totally different outcome.
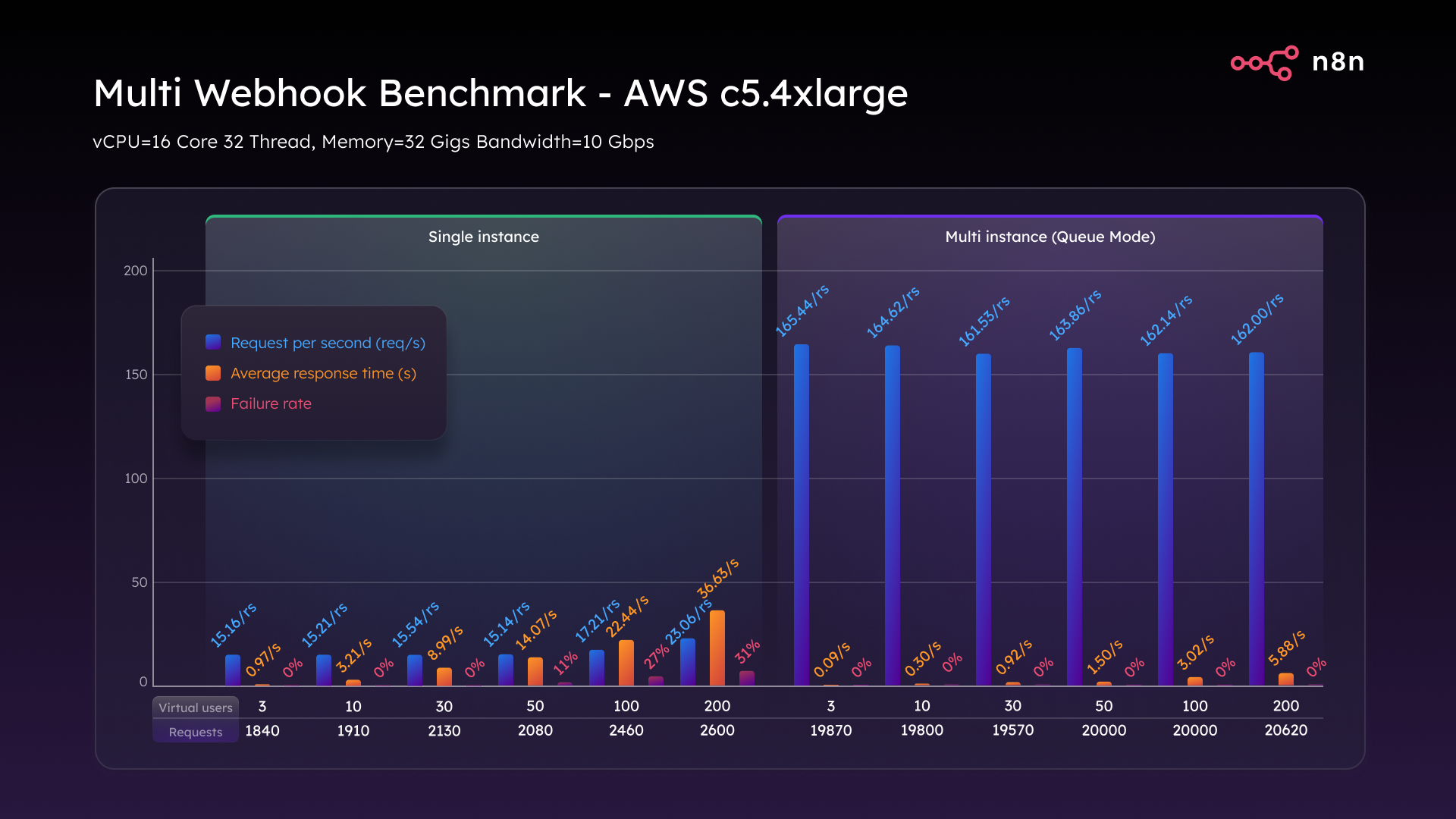
Once again, the C5.4xlarge took things to another level. In Single mode, it peaked at 23 requests per second with a 31% failure rate. But in Queue mode, we hit and maintained 162 requests per second across all loads, with zero failures. Even under max stress, latency stayed around 5.8 seconds. Multitasking at scale demands more muscle and Queue mode absolutely delivers.
Binary File Uploads
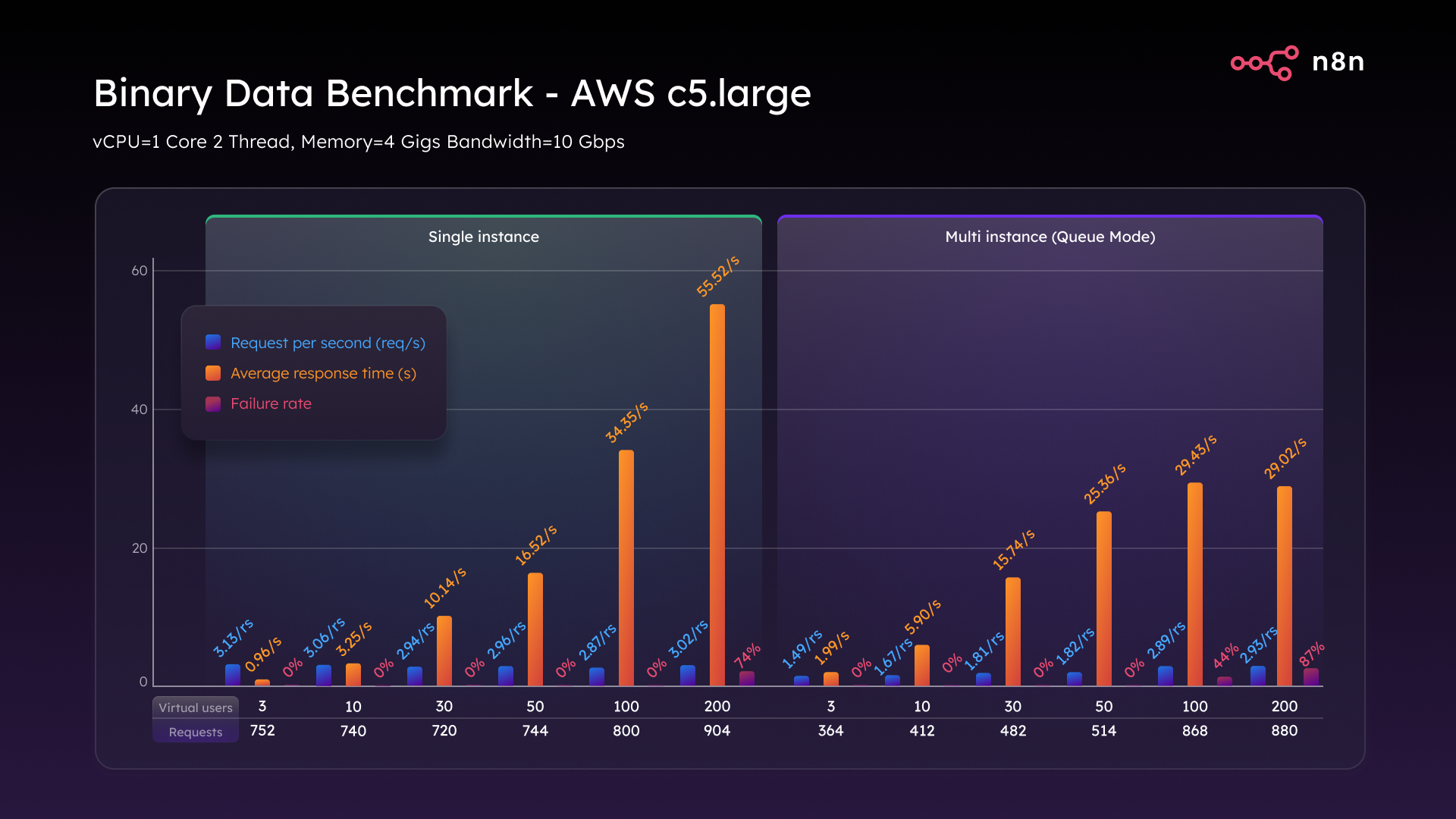
Finally, we wanted to test the most RAM-hungry and disk-heavy tasks we could, so we set up a binary data benchmark with workflows that deal with large file uploads like images, PDFs, and media.
On a C5.large in single mode, the cracks appeared early. At just three virtual users we managed only three requests per second. At 200 VUs, response times ballooned and 74% of requests failed. That’s not just a slowdown, that’s total operational failure.
Queue mode offered a little more resilience, delaying the breakdown. But by 200 VUs, it too collapsed with an 87% failure rate and incomplete payloads.
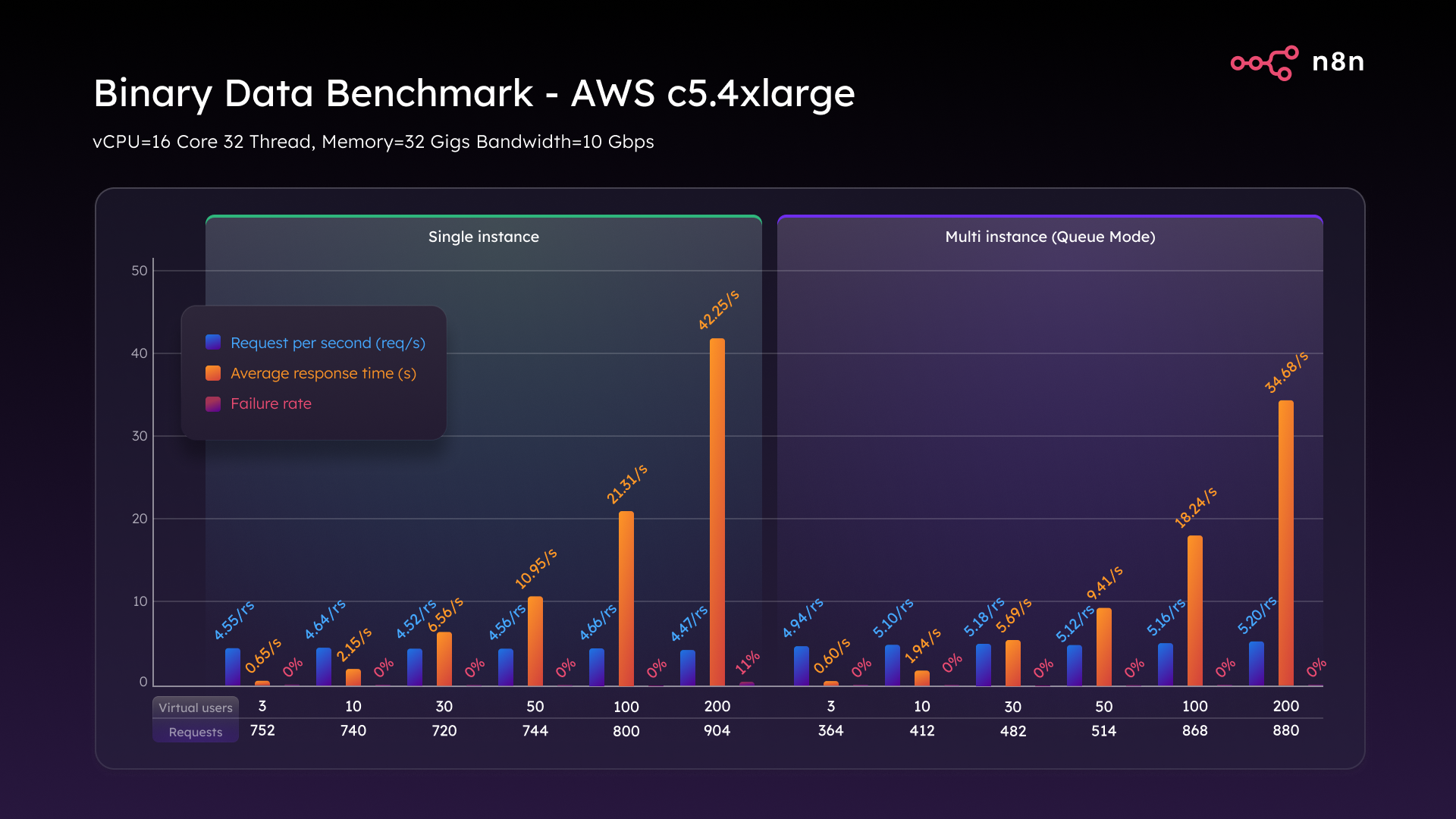
Then we turned to the C5.4xlarge. With this larger instance in single mode, we reached 4.6 requests per second, trimmed response time by a third, and reduced the failure rate from 74% to just 11%. Vastly improved, but not perfect.
Then in Queue mode, we peaked at 5.2 requests per second and, crucially, held a 0% failure rate across the entire test. Every large file was successfully received, processed, and responded to. This test made it clear – it’s not just about architecture. Binary-heavy workflows demand serious CPU, RAM, and disk throughput.
Key Takeaways
So what did all these tests tell us?
- Queue mode isn’t optional. It’s the first step toward real scalability. Even on entry-level hardware, it massively boosts performance with minimal setup.
- Hardware matters. Upgrading to a C5.4xlarge more than doubles throughput, cuts latency in half, and eliminates failure rates entirely.
- Binary data breaks everything—unless you’re prepared. You’ll need more RAM, faster disk, shared storage like S3, and parallel workers to manage it all.
If you’re building automation for internal teams, backend systems, or customer-facing apps, don’t wait for bottlenecks to force an upgrade. Plan for scale from the beginning. Use Queue mode to separate intake from processing, scale horizontally with workers for concurrent processing, and size your hardware to match your workload. Simple flows need less, but binary data and multitasking need more. n8n is built to scale, but like any engine, it needs the right fuel and the right track to reach full power.
Want to test your own setup?
- n8n Benchmarking Guide
- Queue Mode Setup
- Docker Installation Guide
- K6 Load Testing
- Beszel Monitoring
- n8n Benchmark Scripts on GitHub
And here's the full benchmarking video.