This article was written by Andrew Green, technical writer and industry analyst. We pay Andrew, but he refuses to write anything else but his own opinion.
The big boys entered the market, OpenClaw appropriated the MCP security strategy, and everyone started vibe coding but only if they already knew how to code.
It really feels like 2025 was the year of agents, mainly because the industry came to a consensus about how we expect an agent to behave. That and because we found we can bypass context window sizes by spawning sub-agents.
When we first wrote the Enterprise AI agent development tools, we focused a lot on the building blocks of writing agents, such as RAG, memory, tools, and evaluations. One year later, all these capabilities appear to have been commoditized to some degree. We now expect most vendors to allow customers to use a document as context and grounding, or to integrate with Promptfoo (now acquired by OpenAI) for evaluations.
Granted, there are some niche things, like reranking RAG documents based on semantic similarity, which are still differentiators. However, a lot of agent work today doesn’t even need RAG. Even things like web search, which you had to orchestrate explicitly, are now natively available with most vanilla LLM services like ChatGPT and Claude.
MCP had a meteoric rise and then fizzled out. I appreciated Anthropic’s attempts at adding security features such as auth around MCP, but then OpenClaw threw all of that out the window. OpenClaw is not in the cards for any sensible organization considering its tendency to delete data and expose ALL the vulnerabilities.
With this in mind, we need a rather drastic update on our framework for evaluating AI agent builders. So, I have a set of questions that I want to answer myself to understand how a 2026 version of the report will look.
- What got commoditized or natively implemented in vanilla models or LLM services?
- What stands from last year?
- What is still relevant from last year but underappreciated?
- What should change in our evaluation today?
- What did the vendors do over the past year?
- What about coding agents?
What got commoditized or natively implemented in vanilla models or LLM services?
Today, even basic LLM-as-a-service products come close to being agents. I mentioned web search above, but some of the others include:
- Claude’s and ChatGPT’s Projects, which allow users to upload docs, code, and files to create themed collections that can be referenced multiple times.
- Claude Connectors and ChatGPT apps, which connect to apps, files, and services. These connectors are built by third parties.
- Native Skills.md, which are glorified prompt templates, but they still replace some additional work that would have been required in agent builders last year.
- Honorable mentions to Claude Code and Codex which are not really part of the scope but need to be acknowledged
This means all these capabilities are now table stakes, and we expect every agent builder to have them.
What stands from last year?
The codability axis, which evaluates the capabilities available in a product that allow organizations to automate processes using large language models. Some evaluations points that will appear again will include the likes of:
- Routing and branching, which queries to the most appropriate specialized agent or process based on the content, intent, or requirements of the input.
- Parallelization, run multiple AI agents or processes simultaneously when their tasks are independent of each other
- Orchestrator-workers, in which a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results.
- Sequential Agents, where AI agents are designed to work in a specific order, where each agent performs its specialized task and passes the results to the next agent in the sequence.
- Multi-Agents, which can interact in a conversation thread while maintaining awareness of each other's responses and the overall conversation state.
What is still relevant from last year but underappreciated?
The deterministic component. It looks like those who want to automate processes using agents (including in difficult-to-automate and proprietary fields like enterprise networks where I do a lot of work) prefer nudging an agent 20 times to get a response they want instead of putting some work upfront in defining some deterministic logic.
I’ve also seen that the deterministic logic part is not that much focused on performing functions (e.g. normalizing data to a common schema) but rather in ensuring that agents go through a set of pre-defined processes when completing a task. For example, you want an AI agent in security operations to always check a URL or file hash in VirusTotal. You don’t want it to reason its way through checking them on the off chance that it might not.
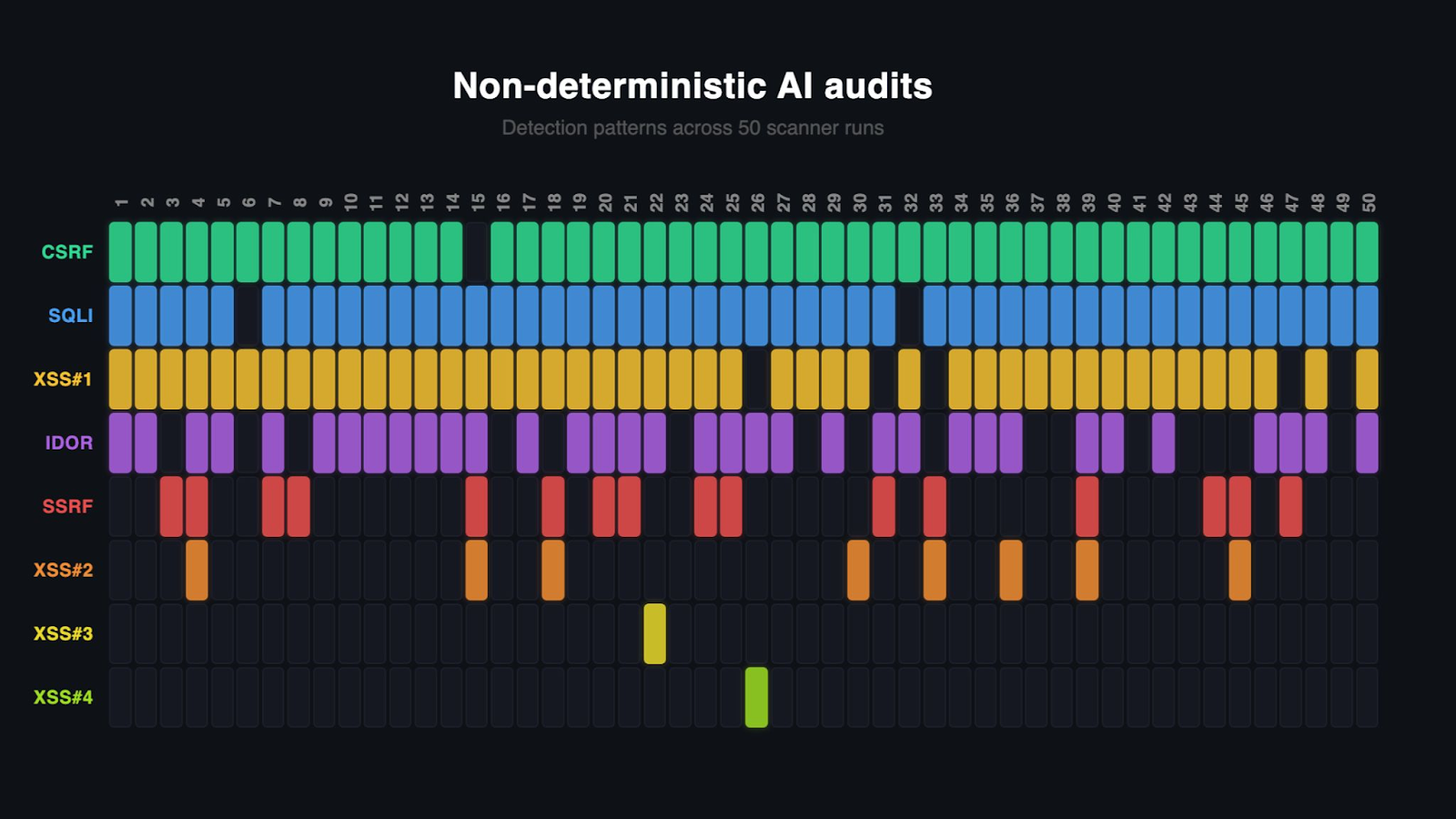
A good example below is of an AI agent running a security audit 50 times, mapping whether all vulnerabilities were detected.
In the screenshot below, you see my test with a purposely written vulnerable app that is run across 50 iterations of Claude Code’s /security-review command and then manually assessed. The app is byte-for-byte exactly the same across all runs. Sometimes all the bugs are identified and other times overlooked.
What should change in our evaluation today?
Last year, we evaluated codability vs integrability.
We’ll likely drop the whole integrability axis. Having a portfolio of pre-configured API integrations is great and tremendously useful, but seems to be underutilized in the context of AI agents. We will likely trim it down and roll it over into the codability axis. Some capabilities will surely be kept, such as writing custom integrations using no-code, or pushing/pulling data - via generic HTTP GET/POST/PUT requests. I’ll likely evaluate whether vendors can write integrations ad-hoc using LLMs using third party tools API reference docs.
We’ll also keep and refine triggers. If you look at OpenClaw, most of its autonomy and intelligence comes from the idea of a heartbeat. It’s a brand new term for a scheduled trigger, so it seems like the agent “remembers” to check your emails every few hours.
With the freed-up Y axis, the current draft plan is to evaluate enterprisiness, or enterprise-readiness. This is a catch-all term that defines how an LLM can be deployed and configured in a responsible way. This will make the difference between a crude personal agent that consumers or solopreneurs are using, and responsible deployments that are suitable for organizations that actually deal with customer data and such.
These will include observability, data loss prevention, transparency and verifiability, proxy-based filtering and firewalling, authentication and authorization, agent identity, lineage, role-based access controls, killswitches, rollback, agent code sandboxing, code execution, runtime reliability and hardening, LLM hosting, software supply chain integrity, policy definition, detection of out-of-policy activities error detection and handling.
Some changes to the codability axis will evaluate how agents can behave autonomously outside the pre-defined workflow, such as spinning up new sub-agents spontaneously to carry out tasks (and implicitly prevent any context drift issues). There is a lot of nuance for use cases like the one above. Consider a skills.md file for a main agent, which would have to be inherited and/or modified for newly spun up agents such that they have the right tools and permissions.
What did the vendors do over the past year?
As quickly as the space evolved, it is rather reassuring to see that most vendors are still in the market and are building more enterprise-grade functions. Without going into too much detail, some highlights for vendors previously included include:
- n8n raising series B and C, a total evaluation of $1bn and >180k github stars.
- Dify and Langflow both surpassing 100k Github stars, meaning the competition is fierce
- Flowise getting acquired by Workday. I’m curious to see how they integrated it in the portfolio.
- Stack AI getting some enterprise certs like SOC2 and ISO 27001
- Workato’s new “Light up your AI with Workato Enterprise MCP” tagline. I expect it will soon be replaced by “Workato Enterprise Skills.md”
Most big LLM providers have also entered the visual no-code agent development space. This includes Google Opal, OpenAI Agent Builder, Google ADK, and Microsoft Studio Copilot.
Speaking from observations over the past decade, large providers entering a market defined by start-ups will manifest in the following way:
- Native user bases will naturally gravitate to these products where use cases permit. I.e. someone with an OpenAI subscription that wants to build an AI agent using a low-code tool will first use OpenAI Agent Builder.
- In instances where the native features cannot meet the customers requirements, the users will evaluate the rest of the market.
- Start-ups and smaller players will have to out-innovate large providers. This is only the natural progression when you compare a lean organization that ships fast versus a big provider where a new feature has a much longer release time. Even the cool AI foundational model providers that ship relatively fast for their size are rather slow compared to startups.
- The big players entering the market will have already been out-performed in terms of featureset. The intent of the report is to validate this assumption, but I hope most readers will share the intuition that OpenAI Agent Builder is not as comprehensive in its ability to define agentic logic as tools that are purpose-built for this.
What about coding agents?
Coding agents are for coders. You may think that anyone can vibe code applications or such, but the reality is that no responsible non-developer knowledge worker working in an organization will write custom applications and have the expectations for them to be maintainable and reliable. Most of the software infrastructure for running these automation logic and associated applications will be handled by the tool itself.
We will therefore explore the angle of using LLM-generated code-based automation within a wider workflow, such as writing a data processing python script, but will not explicitly evaluate the ability to write applications using LLMs.
Call to Participate
I invite any vendors or users to chip in and critique the report prior to publishing. This report, as the one from last year, will be a paper-based analysis based on available technical documentation.
I therefore welcome corrections and first-hand experiences, regardless if they’re pro n8n or not! Please send me a message on LinkedIn.