If you’ve worked with any Large Language Model (LLM) applications, you've likely struggled with the inherent challenges of these powerful systems. At their core, LLMs are prone to hallucinations (i.e., confident yet incorrect outputs) and suffer from knowledge cut-off dates, meaning they lack access to real-time or proprietary information unless explicitly provided. They can also produce inconsistent responses and often miss nuanced context, processing language based on learned patterns rather than true understanding.
To overcome these limitations, developers turned to Retrieval-Augmented Generation (RAG), a technique that connects LLMs to external data sources. This allows the model to fetch relevant, up-to-date information before formulating a response, dramatically improving accuracy. RAG was a significant step forward, but it's fundamentally a static, linear process: retrieve information, then generate an answer.
But what if the system could be more intelligent? What if it could autonomously decide the best way to find an answer, which tools to use, and even critique its own response for completeness? This is the promise of Agentic RAG, the next evolution of this framework. By integrating LLM-powered agents, we transform the simple RAG pipeline into a dynamic, intelligent workflow.
In this article, we'll explore what Agentic RAG is, how it moves beyond the limitations of its predecessor, and why it is set to redefine how we build sophisticated AI applications.
What is an agentic RAG?
At its core, Agentic RAG upgrades the standard retrieval framework by integrating LLM-powered agents to introduce autonomous decision-making. Instead of following a rigid set of instructions, the system can perceive its environment, make decisions, and execute actions to achieve a goal.
While this intelligence is applied across the entire workflow, the most fundamental shift occurs during indexing. In traditional RAG, indexing is a predefined and often manual process. With Agentic RAG, this becomes a dynamic and context-aware operation driven by the AI itself. An agent can autonomously decide not just what information to add to the vector store, but also how to do it most effectively.
For example, an agent can intelligently parse complex documents to extract richer, more useful metadata and also decide on the optimal chunking strategy for different types of content. This transforms indexing from a static setup task into an ongoing process of knowledge-building, laying the foundation for more accurate and relevant results down the line.
What is the difference between simple RAG and agentic RAG?
The primary difference between simple (or naive) RAG and Agentic RAG lies in their operational workflow and intelligence. While both aim to enhance Large Language Models (LLMs) with external data, their approaches and capabilities differ significantly. Simple RAG is a linear and static process, whereas Agentic RAG is dynamic, adaptive, and autonomous.
To better understand the key distinctions, here is a direct comparison:
| Feature | Simple RAG | Agentic RAG |
|---|---|---|
| Workflow | Fixed “retrieve then read” sequence |
Dynamic, multi-step process (query rewriting, multi-source retrieval, or skipping retrieval) |
| Decision-making | None; path is predetermined |
Agent makes decisions (routing, tool use, self-critique) |
| Data Sources & Tools | Single, unstructured knowledge base |
Multiple sources (vector stores, SQL, web APIs, etc.) |
| Adaptability | Rigid; same process for every query |
Adaptive; adjusts retrieval steps for complex, multi-hop queries |
In essence, while simple RAG provides an LLM with passive access to external knowledge, agentic RAG gives it an active framework for intelligent operation. This framework enables the system to solve complex problems by dynamically choosing tools and data sources. This intelligence also extends to the knowledge base itself; an agent can autonomously update and maintain its own information, deciding what to store and how to index it for optimal relevance and accuracy.
What is the structure of agentic RAG?
As we previously saw, agentic RAG fundamentally changes how a system stores, retrieves, and uses information. Instead of a rigid pipeline, it introduces a three-staged lifecycle where agents make decisions at every step to improve the quality and relevance of the final answer. Building such a system requires three key components:
Intelligent storage: deciding what and how to index
Before any information can be retrieved, it must be stored. In a traditional RAG system, this indexing process is static. An Agentic RAG system, however, turns this into an active, intelligent process.
An agent can analyze incoming data and decide if it should be indexed at all. More importantly, it decides the most effective way to store it. This includes performing high-precision parsing of complex documents, creating rich metadata for better filtering, choosing the optimal chunking strategy, and even selecting the most appropriate embedding model for the context of the data. This ensures the knowledge base is not just a passive repository but an optimized and strategically organized source of information.
Dynamic retrieval: using the right tool for the right data
When a user asks a question, an agentic system excels at finding the right information from the best possible source. It is not limited to searching a single vector store.
Using a component often called a Retriever Router, an LLM agent analyzes the incoming query and decides the best course of action. This might mean querying a SQL database, using a web search API, or searching internal product documentation. By being equipped with a variety of tools, the system can interact with multiple, diverse data sources, ensuring it can retrieve the most relevant context, no matter where it lives.
"You are a router. Your job is to select the best tool to answer the user's query. You have two tools:
1. SQL_database_tool: Use for questions about sales, revenue, or specific metrics.
2. document_vector_store_tool: Use for questions about company policies or general information."
Verified generation: composing and critiquing the answer
Once the information is retrieved, the process isn't over, using an Answer Critic function, the system checks if the retrieved information has correctly and completely answered the user's original question. If the answer is incomplete or incorrect, the critic can generate a new, more specific question to retrieve the missing information and trigger another round of retrieval. This iterative process of generating and critiquing ensures the final response is accurate and comprehensive before it is ever presented to the user.
"You are an Answer Critic. Evaluate if the GENERATED_ANSWER fully addresses the USER_QUERY. If it is incomplete, state what is missing and generate a new INTERNAL_QUERY to find the missing information."
3 agentic RAG use cases
Let's see how these principles work in practice through a few concrete examples. The following workflows illustrate how n8n's visual, node-based interface is perfectly suited for designing and orchestrating the complex, multi-step logic that Agentic RAG systems require.
Adaptive RAG (choosing the right retrieval strategy)
Not all questions are the same. Some ask for a simple fact, while others require a deep analysis. A simple RAG system treats them all identically, which can lead to poor results. This workflow demonstrates a more advanced, adaptive RAG by first analyzing the user's intent and then choosing the best retrieval strategy for that specific type of question.
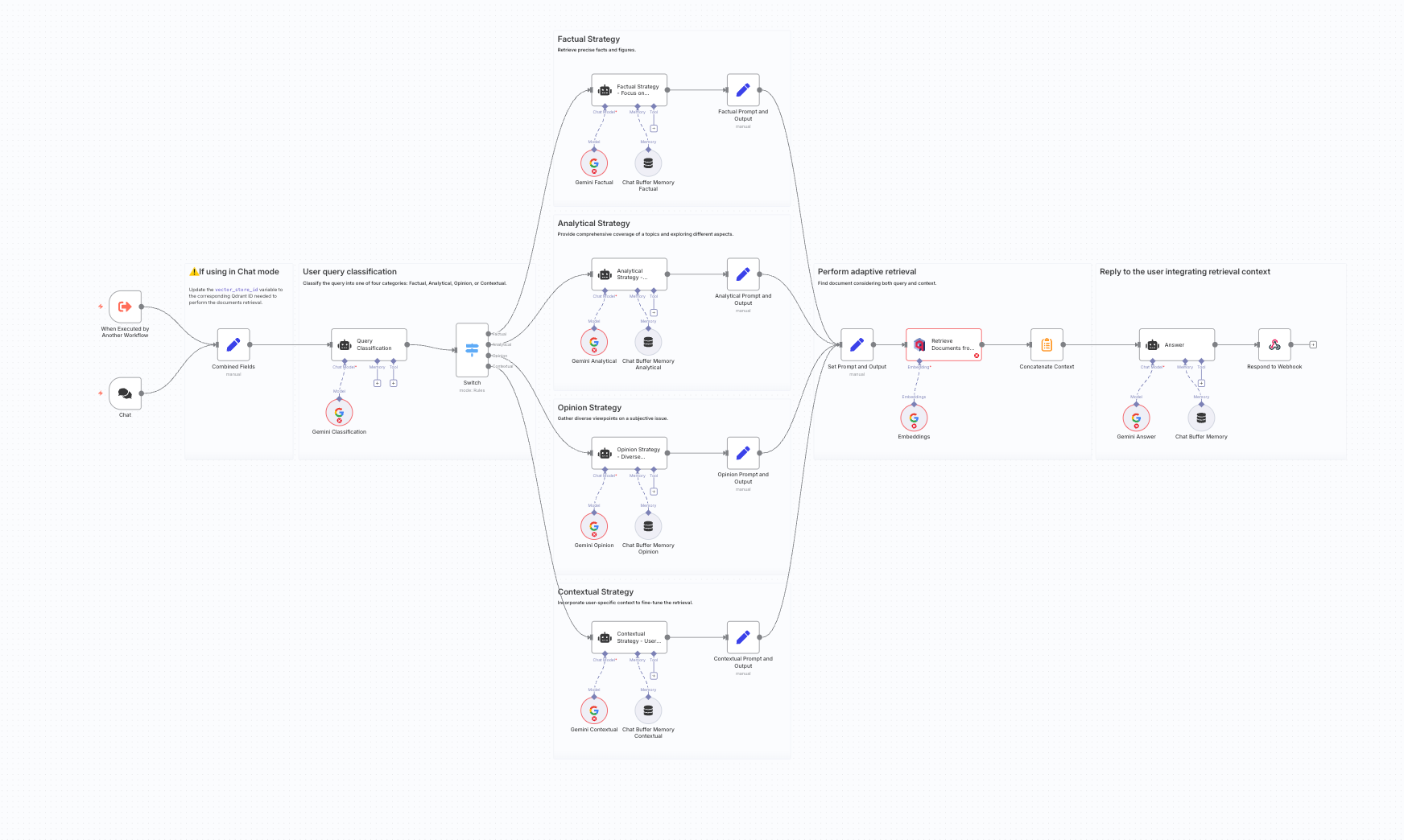
This workflow is built around a multi-stage process where agents make decisions to tailor the retrieval and generation process.
- Query classification: When a user submits a query, the first AI agent doesn't try to answer it. Its only job is to classify the user's intent into one of four categories: Factual, Analytical, Opinion, or Contextual.
- Strategic routing: A Switch node directs the flow to one of four distinct paths based on the classification. Each path is a specialized strategy for handling that type of query.
- Query adaptation: On each path, another AI agent adapts the original query to optimize it for retrieval.
- For factual queries, the agent rewrites the question to be more precise.
- For analytical queries, the agent breaks the question down into several sub-questions to ensure broad coverage.
- For opinion queries, the agent identifies different viewpoints to search for.
- Tailored retrieval and generation: The adapted query is used to retrieve relevant documents from a vector store. Finally, a concluding agent generates the answer using a system prompt specifically designed for the original query type (e.g., "be precise" for factual, "present diverse views" for opinion).
This workflow is a prime example of Agentic RAG because it moves beyond simply routing to different data sources and instead routes to different information retrieval strategies.
The initial classification agent acts as a sophisticated Retriever Router. It's making an autonomous decision about the user's intent, which dictates the entire subsequent workflow. A simple RAG system lacks this understanding and uses a one-size-fits-all approach.
The agents in each of the four paths actively transform the user's query. They aren't just passing it along, they are working to improve it based on the initial classification.
AI Agent with a dynamic knowledge source
This workflow demonstrates a core principle of Agentic RAG: dynamic source selection. Instead of relying on a single knowledge base, we'll build an AI agent that can intelligently choose between two different information sources: a static RAG database for foundational knowledge and a live search engine for current events.
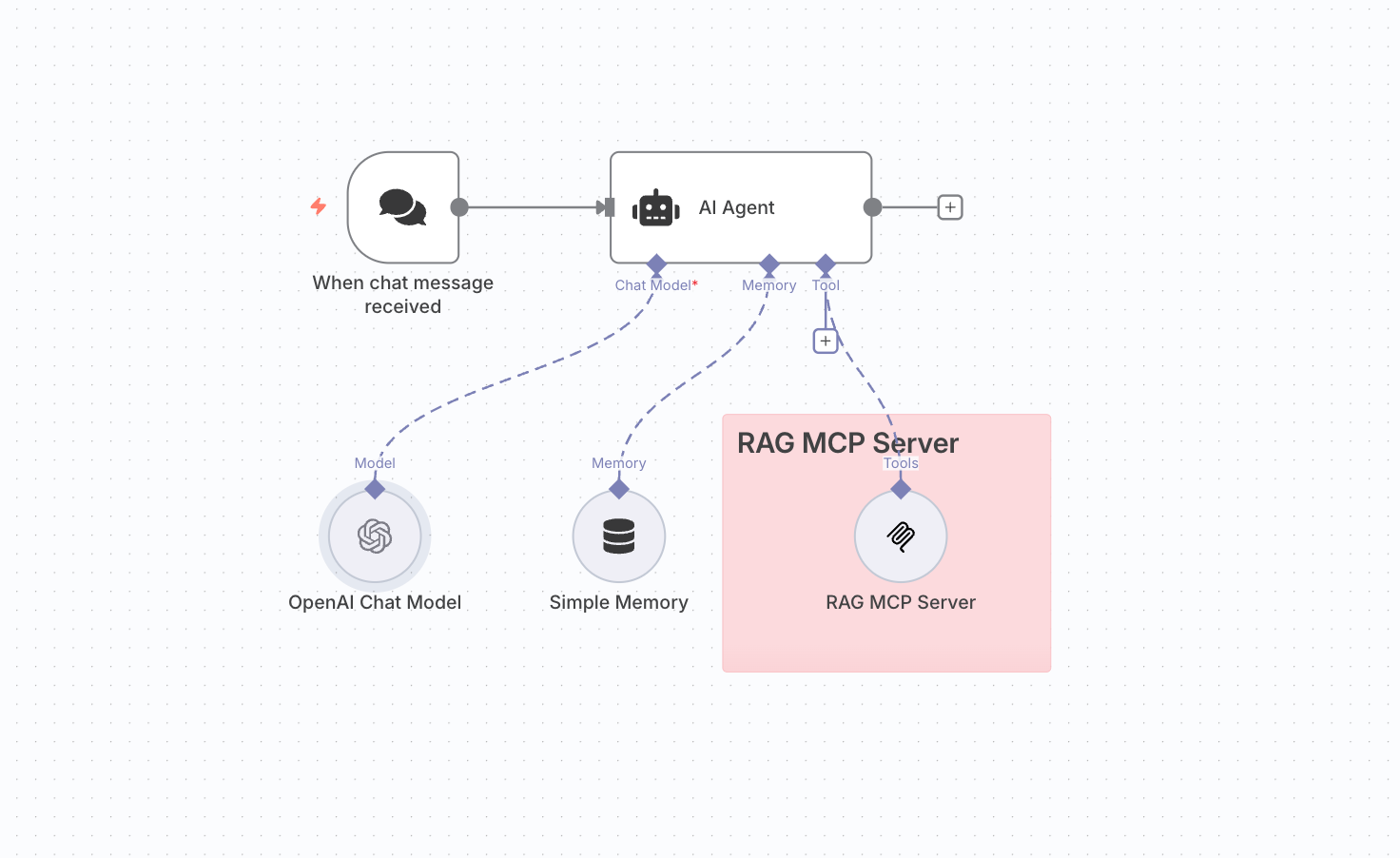
The main component of this workflow is the AI Agent node. This agent is connected to two distinct "tools" that it can use to answer questions:
- A RAG MCP server: This server is connected to a traditional RAG database containing specific, pre-loaded information (in this case, about the Model Context Protocol).
- A search engine MCP server: This server gives the agent the ability to perform real-time web searches, providing access to up-to-the-minute information.
Why is this considered "Agentic RAG"? This setup goes beyond simple RAG because the AI isn't just retrieving information; it's making a decision. When a user asks a question, the agent must first analyze the query and decide which tool is best suited to answer it.
This is the "Retriever Router" concept in action. The Model Context Protocol (MCP) acts as the communication layer that allows the agent to understand its available tools (the two servers) and choose one.
For example, if you ask, "What is Model Context Protocol?", the agent will recognize this as a foundational question and route it to the RAG MCP Server. However, if you ask, "Who won the Formula 1 race last weekend?", the agent understands this requires current information and will use the Search Engine MCP Server to find the answer.
This autonomous decision-making is what makes the workflow "agentic".
AI agent for tabular and unstructured data (SQL + GraphRAG)
This advanced workflow addresses one of the most significant challenges for traditional RAG systems: handling structured, tabular data from sources like Excel files or Google Sheets. While standard RAG excels at searching text, it often fails when asked to perform precise calculations or comparisons on relational data because the chunking process breaks the table's structure.
This system solves that problem by creating a hybrid agent that can choose between SQL queries for tabular data and GraphRAG for unstructured documents.
Check out the original YouTube video here:
The workflow is built around an intelligent data ingestion process that treats data differently based on its type. The process begins when a new file is added to a designated Google Drive folder. An initial step in the n8n workflow checks the file type to determine the correct processing path.
For tabular data (Excel/Sheets), the system executes a series of steps to properly structure it for querying:
- The file is downloaded and its contents are extracted.
- A code node then creates a new PostgreSQL table in a database like Supabase. It dynamically generates a database schema from the file's headers.
- Finally, it populates the new table with the data, handling various data types like text, numbers, and dates.
Unstructured data (PDFs, Word documents) are routed to the GraphRAG system for a more sophisticated ingestion process using a library called LightRAG. In short:
- Instead of simply chunking the text, an LLM first analyzes the document's content to identify key entities (like people, companies, or concepts) and the relationships that connect them.
- These extracted entities and relationships are then used to build a structured knowledge graph. This graph represents the core information from the document and is usually stored in a dedicated graph database.
Why is this considered "Agentic RAG"? The system doesn't just index all incoming data the same way. An agent makes a decision based on the file type, choosing a different, more effective storage strategy for tabular data (SQL database) versus unstructured documents (GraphRAG).
It also decides which knowledge source is appropriate, based on the user's question. If the query is best answered with tabular data, it generates an SQL query and uses the execute SQL query tool to get the answer directly from the database. If the question is about document content, it routes the query to the GraphRAG tool instead.
FAQs
What is the difference between self RAG and agentic RAG?
While both represent advancements over simple RAG, they focus on improving the process in different ways. The key difference is that Self-RAG builds decision-making into the Language Model itself, while Agentic RAG builds decision-making into the workflow around the model.
Self-RAG is a specific framework that fine-tunes a model to make its own retrieval decisions during generation. It uses special "reflection tokens" to internally decide if it needs to search for information, if the retrieved documents are relevant, and if its own answer is well-supported by the facts. It’s about giving the model the ability to self-correct and self-assess its own process.
Agentic RAG, as we've discussed, is a broader architectural pattern. It uses LLM-powered agents to manage an external workflow. This includes analyzing a user's intent to choose the right tool, adapting the query to a specific strategy, and critiquing the final answer.
What is the difference between graph RAG and agentic?
Agentic RAG is about the intelligence and autonomy of the system's decision-making and workflow execution. Graph RAG is about the structure and richness of the underlying knowledge base, using knowledge graphs to enable more precise, relational, and multi-hop information retrieval. An Agentic RAG system might incorporate a Graph RAG as one of its specialized "retriever agents" or tools for querying structured data, demonstrating how these variants can complement each other.
The key differentiator between traditional RAG and Graph RAG is the underlying database. Graph RAG tipically involves querying a graph database, for example Neo4j, ArangoDB etc. In contrast traditional RAG involves querying a vector database (vector stores), for example Pinecone, Qdrant, Milvus etc.
What is the difference between RAG and multi-model RAG?
Multi-model RAG is an approach where different, specialized AI models are used at various stages of the RAG pipeline to improve performance and handle complex tasks. This can involve several strategies:
Diverse LLM utilization: In complex applications, a "multi-LLM strategy" can be used to assign different Large Language Models (LLMs) to the jobs they perform best. This might involve specialized task-specific models like:
1. Named Entity Recognition (NER) models to extract specific entities for metadata filtering.
2. Hallucination-detection and moderation models to ensure the quality and safety of the final answer.
Agentic RAG is a great example of a multi-model approach. This setup uses multiple LLM agents that work together to solve a problem. These agents can have specific "profiles" (like a "coder" agent and a "tester" agent), coordinate their actions, and provide feedback to each other to tackle complex, multi-step tasks.
Wrap up
As we've covered, Agentic RAG is a big step up from traditional RAG systems. It moves away from the simple "retrieve-then-read" process and uses AI agents to create a smarter, more flexible workflow.
This shift means that agents make their own decisions at every step of the information lifecycle. In the storage phase, they can intelligently figure out how to index information, choosing the best chunking strategy or metadata to make the knowledge base more effective. During retrieval, they act as a smart router, choosing the best tool for a specific query, whether that's a vector database, a SQL database, or a live web search. Finally, in the generation phase, they don't just give an answer, they can also review their own work for accuracy, triggering more search rounds if the first answer isn't good enough.
As the n8n RAG workflow examples have shown, these capabilities are not just theories but are practical tools you can use today to build the next generation of powerful and trustworthy AI applications.
What’s next?
The next step is to move from theory to practice. Think about your own data and the challenges you face. Could an agent that chooses between a database and a web search improve your results? Could adapting the retrieval strategy based on a user's query provide more relevant answers?
Check out these step-by-step video guides on how to build Agentic RAG systems with n8n:
- I Built the ULTIMATE n8n RAG AI Agent Template
- Store All Data Types with Agentic RAG in n8n
- The ULTIMATE n8n Agentic RAG System (SQL + GraphRAG)
- Building with Reasoning LLMs | n8n Agentic RAG Demo + Template
For a deeper look into the fundamentals, explore this tutorial on building a custom knowledge RAG chatbot using n8n. You don't have to start from scratch, browse the pre-built AI workflows from the n8n community to use as a starting point for your own projects.