
If you’ve ever struggled with setting up pipelines for extracting, transforming, and loading data (so-called ETL jobs), managing different databases, and scheduling workflows – know that there’s an easier way to automate these data engineering tasks.
In this tutorial, you’ll learn how to build a no-code n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
Table of contents
The data pipeline
The workflow with Python
The workflow with no code
1. Starting the workflow
2. Collecting tweets
3. Inserting tweets into MongoDB
4. Analysing the sentiment of tweets
5. Processing sentiment analysis
6. Inserting tweets values into Postgres
7. Filtering positive and negative tweets
8. Sending positive tweets to Slack
9. Ignoring negative tweets
What's next?
The data pipeline
A few months ago, I completed a Data Science bootcamp, where one week was all about data engineering, ETL pipelines, and workflow automation. The project for that week was to create a database of tweets that use the hashtag #OnThisDay, along with their sentiment score, and post tweets in a Slack channel to inform members about historical events that happened on that day. This pipeline had to be done with Docker Compose and included six steps:
- Collect tweets with the hashtag #OnThisDay
- Store the collected tweets in a MongoDB database
- Extract tweets from the database
- Process the tweets (clean the text, analyse sentiment)
- Load the cleaned tweets and their sentiment score in a Postgres database
- Extract and post tweets with positive sentiment in a Slack channel
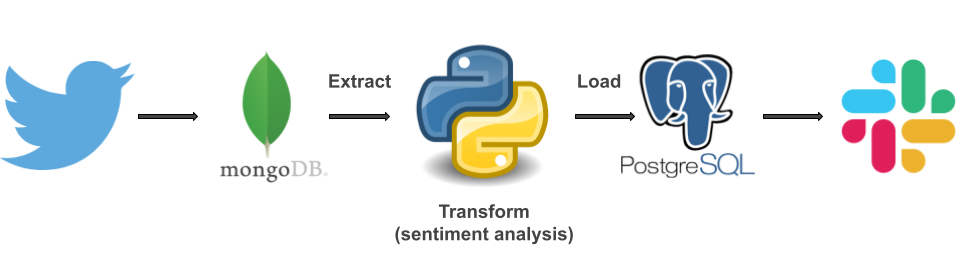
The workflow with Python
This is a fun project that offers lots of learning opportunities about different topics: APIs, text processing with Natural Language Processing libraries, both relational and non-relational databases, social media and communication apps, as well as workflow orchestration.
If you're wondering, like I did, why we had to use two different databases, the answer is simple: for the sake of learning more. Postgres and MongoDB represent not only different database providers, but different kinds of database structures – relational (SQL) vs non-relational (NoSQL) – and it’s useful to be familiar with both.
Though our use case is just for fun, this pipeline can support most common data engineering tasks (e.g. aggregating data from multiple sources, setting up and managing the data flow across databases, developing and maintaining data pipelines).
I was really excited, though also a bit overwhelmed by all the things I had to set up for this project. In total, I spent five days learning the tools, debugging, and building this pipeline with Python (including libraries like Tweepy, TextBlob, VADER, and SQLAlchemy), Postgres, MongoDB, Docker, and Airflow (most frustrating part...). If you’re interested to see how I did this, you can check out the project on GitHub and read this blog post.
But in this article, I’ll show you an easier way to achieve the same result in as much as an hour – with a no-code workflow in n8n!
The workflow with no code
Since I started using n8n, I’ve been looking for use cases for various data science tasks, starting with my existing projects. When I realised that all the apps and services that I used in my tweets pipeline are available as n8n nodes, I decided to replicate the project as an n8n workflow with nine nodes:
- Cron node to schedule the workflow
- Twitter node to collect the tweets
- MongoDB to store the tweets
- Google Cloud Natural Language to analyse the sentiment of the tweets
- Set to extract the sentiment values
- Postgres to store the tweets and their sentiment
- IF to filter positive and negative tweets
- Slack to post tweets into a channel
- NoOp to ignore negative tweets
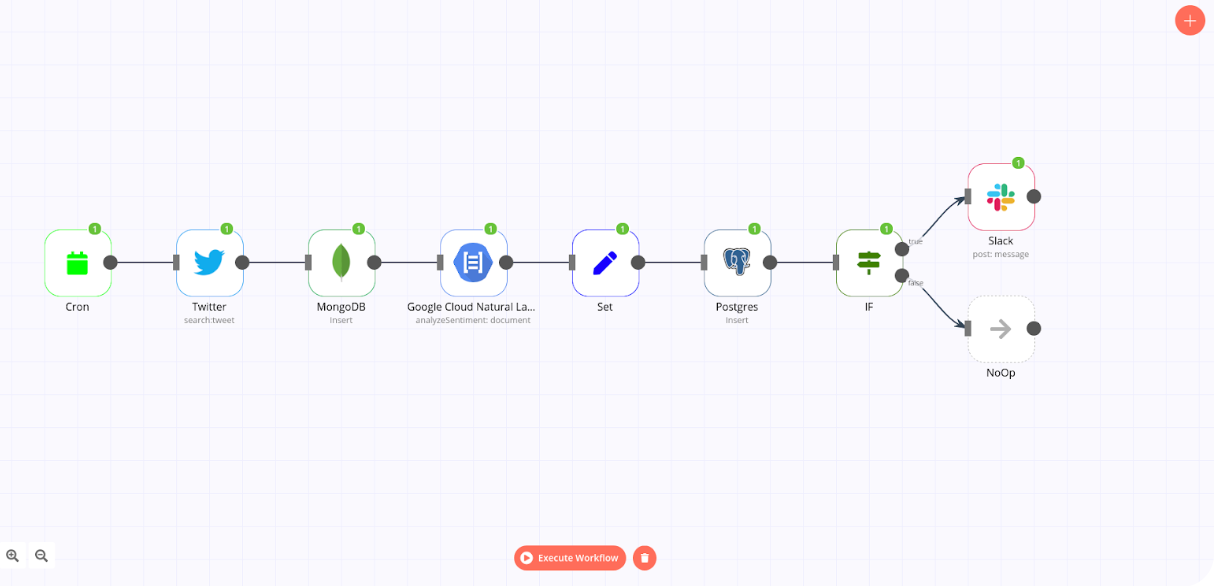
In this article, I’ll show you how to set up this workflow node by node. If this is your first n8n workflow, have a look at our quickstart guide to learn how to set up n8n and how to navigate the Editor UI. It’s also helpful to have at least basic knowledge of databases and SQL.
Once you have your n8n Editor UI open, there are two ways to follow this tutorial: either copy the workflow from here into your Editor UI and deactivate the nodes, so that you can execute and test each node separately, or add the nodes one at a time.
1. Starting the workflow
We will begin with the end in mind: We know that we want this whole workflow to run every day, so first we need to set up the Cron node to trigger our workflow every day at 06:00.
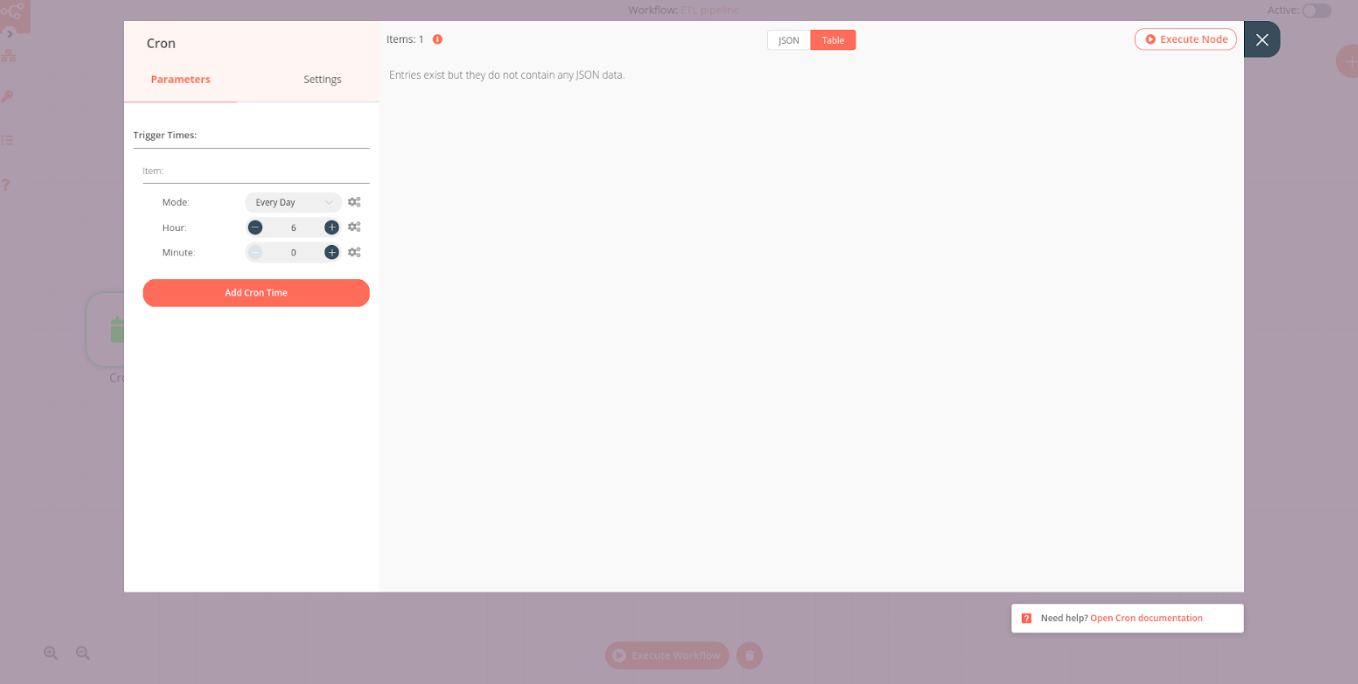
The Cron node makes it very easy to schedule and trigger workflows, compared to setting up scheduling and triggers in Airflow, and this saved me so much time and nerves!
2. Collecting tweets
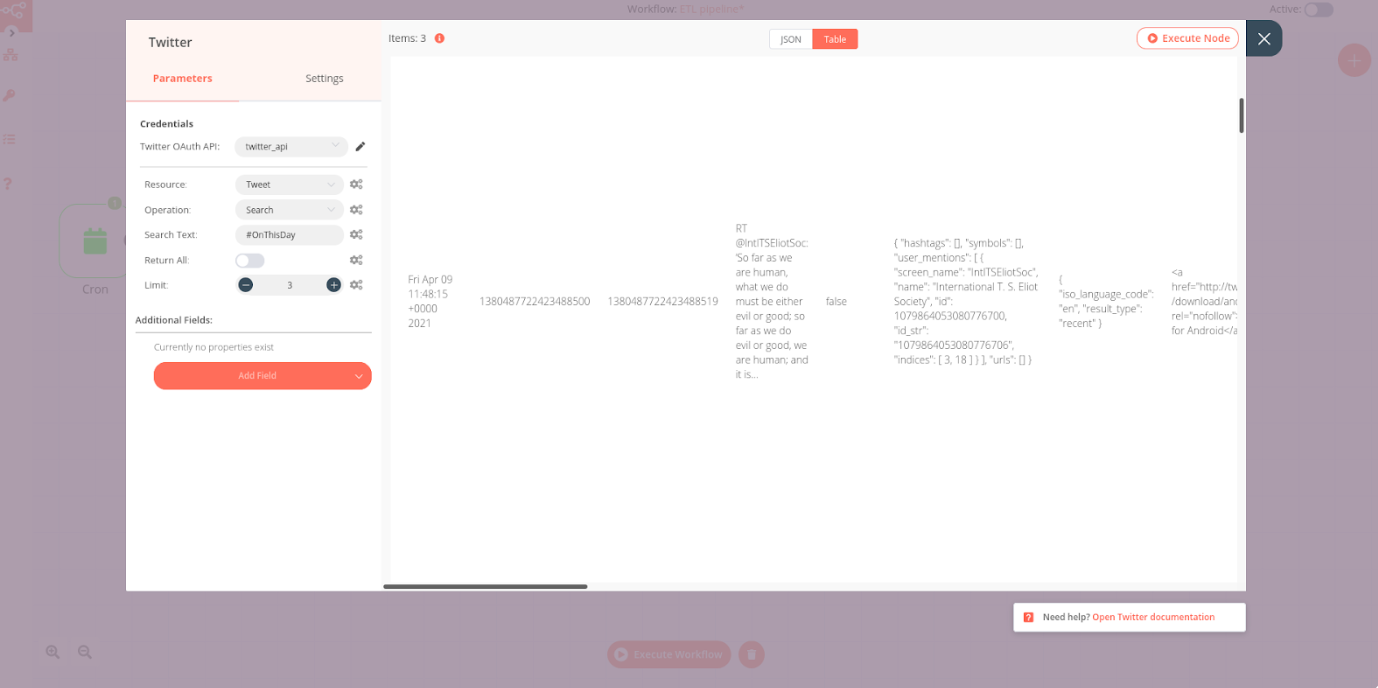
Next, we are going to collect tweets with the hashtag #OnThisDay. To do this, first you need to create a Twitter Developer account and register an app. Follow the instructions in our reference docs to learn how to set up your Twitter app and get the necessary credentials (Consumer Key and Consumer Secret). Once you have your credentials, copy and paste them in the Credentials field of the Twitter node. Next, set the parameters:
- Operation: Search
- Search Text: #OnThisDay
- Limit: 3. This last step is not mandatory, but I recommend limiting the number of collected tweets at least for testing the workflow, to ensure that you don’t reach the query rate limit of the Twitter API and Google Cloud Natural Language.
3. Inserting tweets into MongoDB
Now that we collected some tweets, we need to store them into a database. MongoDB is a non-relational database (NoSQL) that stores data in JSON-like documents. Since our tweets are returned in JSON format, MongoDB is the ideal database to store them in and the MongoDB node allows us to connect to the database. Before configuring the node, you need to create a MongoDB instance, set up a cluster, create a database and a collection within it.
- Create a MongoDB account
- Set up a cluster: cloud.mongodb.com > Clusters > Create New Cluster
- Create a database: Cluster > Collections > Create Database
- Create a collection: Cluster > Collections > Database > Create Collection
- Create a field: Collection > Insert document > Type the field “text” below “_id”
- Allow access to the database: Project > Security > Network Access > IP Access List > Add your IP address.
- Connect to the database from your terminal:
mongo "mongodb+srv://<YourClusterName>.mongodb.net/<YourDatabaseName>" --username <YourUsername>
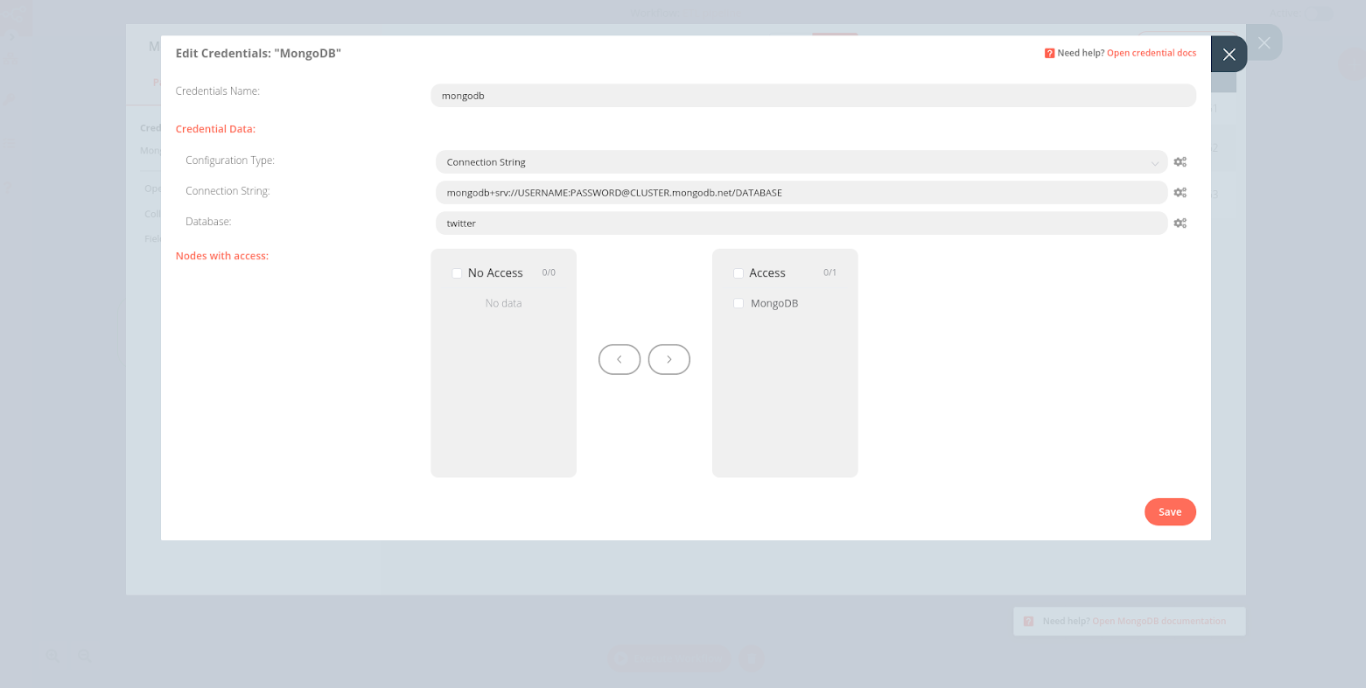
If you need more detailed information or other set up options, refer to the MongoDB documentation. Now that we have a MongoDB collection up and running, we can set up the MongoDB node for our workflow. Set up:
- Connection String: mongodb+srv://<YourClusterName>.mongodb.net/<YourDatabaseName>
- Database: <YourDatabaseName>
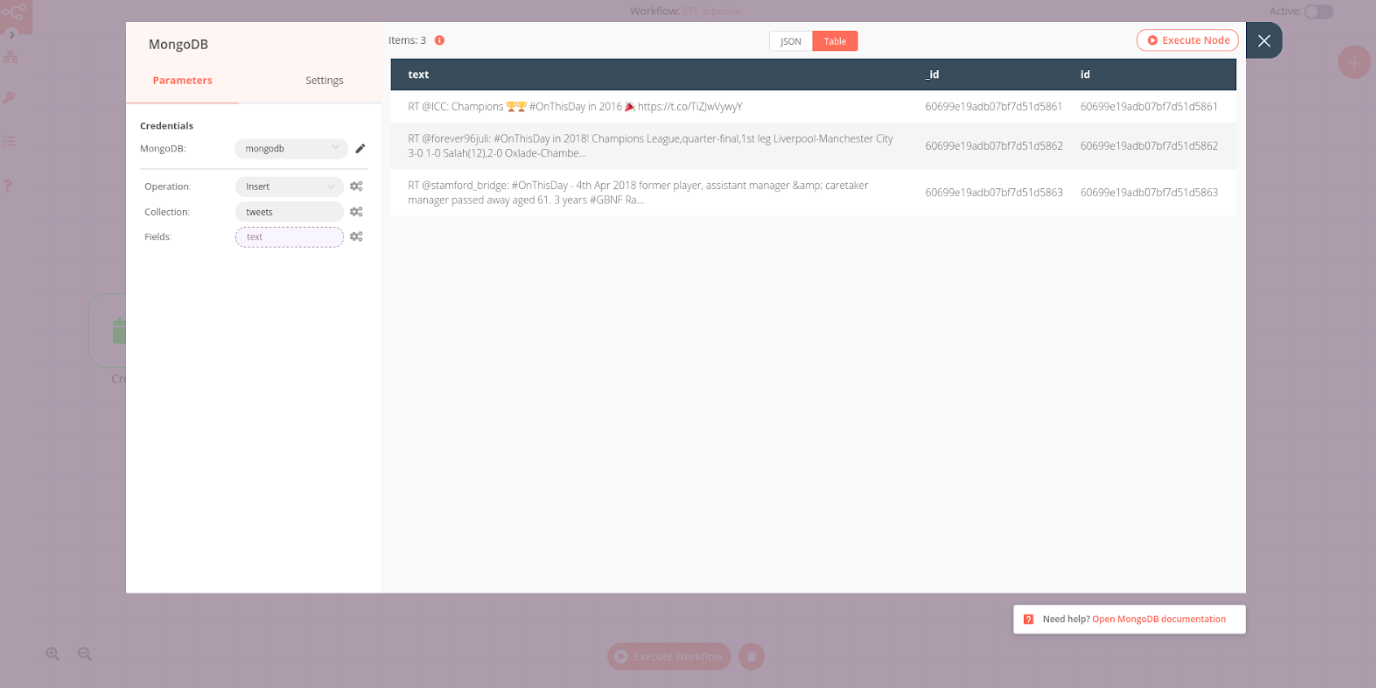
Next, configure the node parameters to insert the collected tweets into the collection:
- Operation: Insert
- Collection: <YourCollectionName>
- Fields: text
4. Analysing the sentiment of tweets
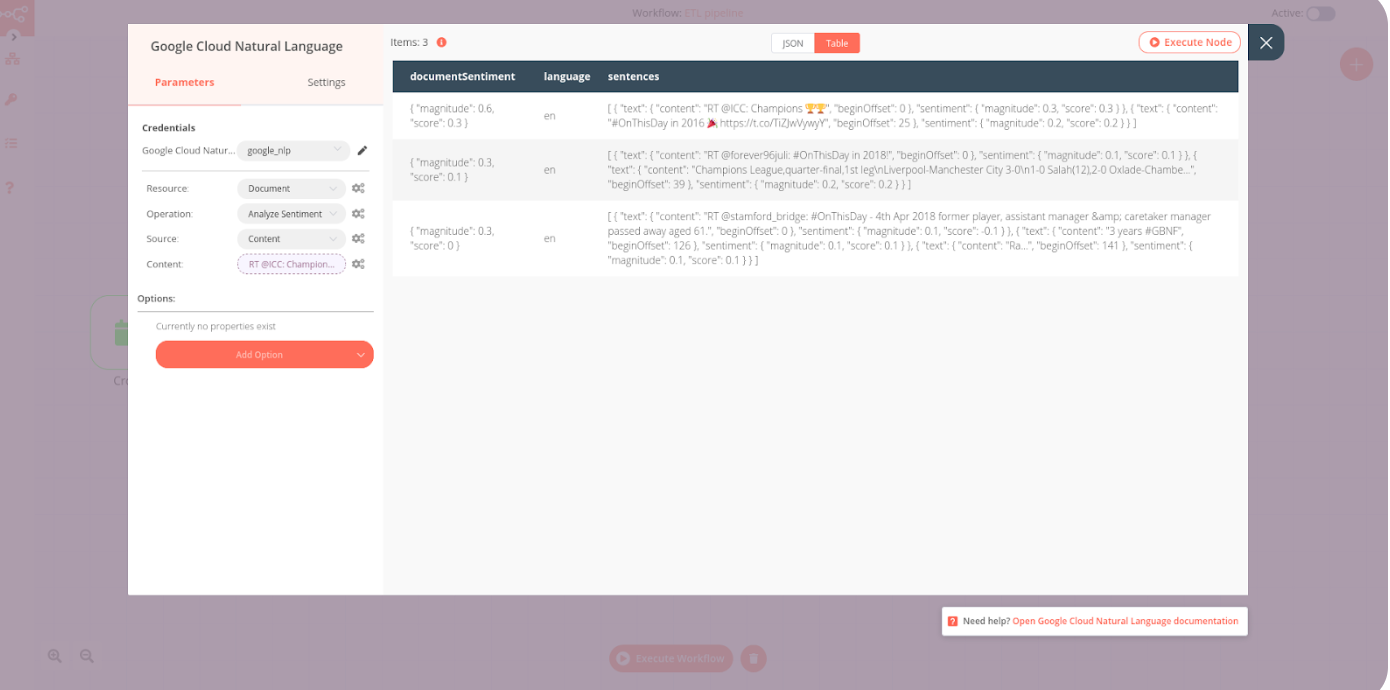
Here comes my personal favourite part of this workflow: analysing the sentiment of tweets, i.e. the feeling associated with the entire text or entities in the text. For this, we use the Google Cloud Natural Language node, which analyses a text and returns two numerical values:
- score: Sentiment score between -1.0 (negative sentiment) and 1.0 (positive sentiment).
- magnitude: A non-negative number in the [0, +inf) range, which represents the absolute magnitude of sentiment regardless of score (positive or negative).
Both results are returned as documentSentiment in JSON format:
{
"magnitude": number,
"score": number
}Before configuring the node, you have to sign up on the Google Cloud Platform to enable the API and get the necessary credentials (Client ID and Client Secret). Follow the instructions in our reference docs to set up your account and the node credentials.
Once that’s done, add an expression to the parameter Content by clicking on the gear icon and selecting Current Node > Input Data > text.
As a side note, here it was interesting to see how differently Google Cloud Natural Language and the VADER and TextBlob libraries evaluated the sentiment of text:
5. Processing sentiment analysis
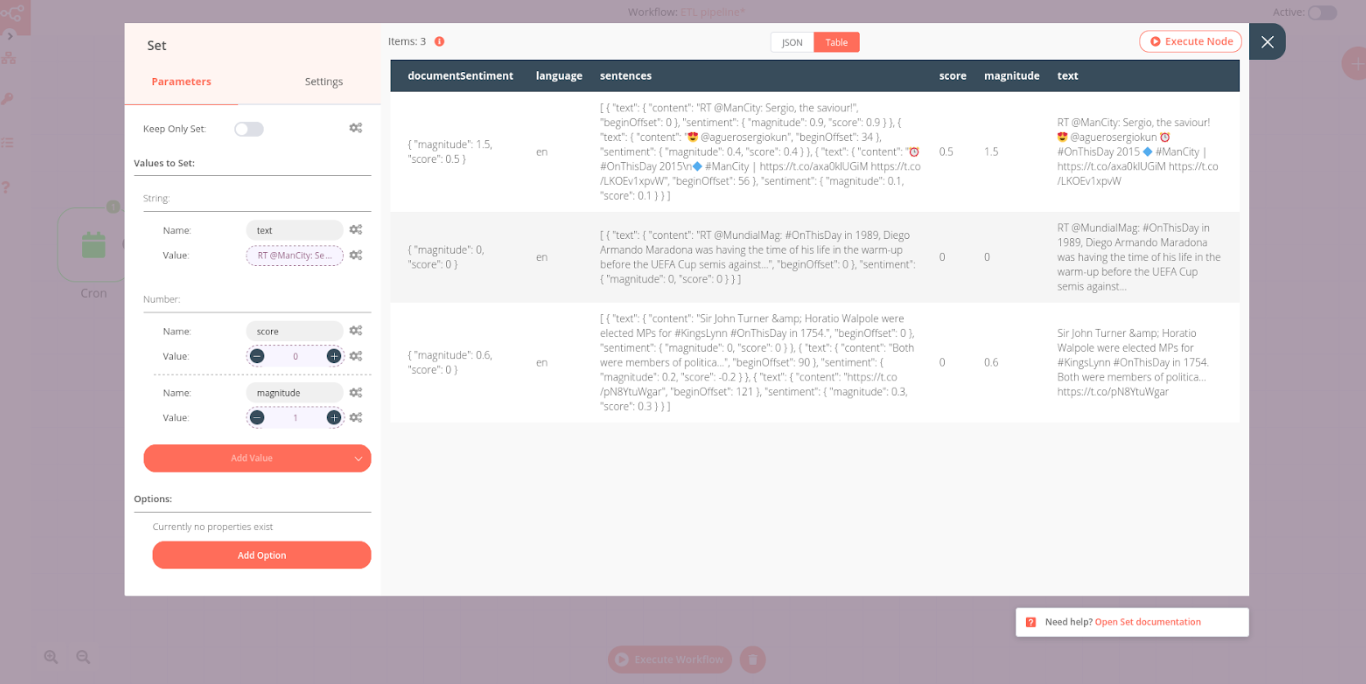
Now that we have sentiment scores for each tweet, we want to insert the text, sentiment score, and magnitude of the tweets into a new Postgres database. Since the magnitude sentiment score and the magnitude are included in the documentSentiment, we need to extract them in order to insert the values in two separate columns in Postgres.
For this, we use the Set node, which allows us to set new values based on the data we already have. In the node parameters, set three values:
- Score (number): Current Node > Input Data > JSON > documentSentiment > score
- Magnitude (number): Current Node > Input Data > JSON > documentSentiment > score
- Text (string): Current Node > Input Data > JSON > sentences > [Item: 0] > text > content
6. Inserting tweets values into Postgres
Next, we want to insert the newly set data values into a Postgres database. First, you need to install Postgres, then create a database and a table for tweets. The process is quite similar to the MongoDB setup and you can do this from your terminal:
- Connect to Postgres:
psql
- Create a database:
createdb twitter
- Go into the created database:
psql twitter
- Create columns in the database. The columns have to be named like the values defined in the Set node, in order to be matched.
CREATE TABLE tweets (text varchar(280), score numeric(4,3), magnitude numeric(4,3));
Now we can go ahead and configure the Postgres node. Fill in the name of your database, username, and password in the Credential Data fields, then configure the node parameters:
- Operation: Insert
- Table: tweets
- Columns: text, score, magnitude
- Return Fields: *
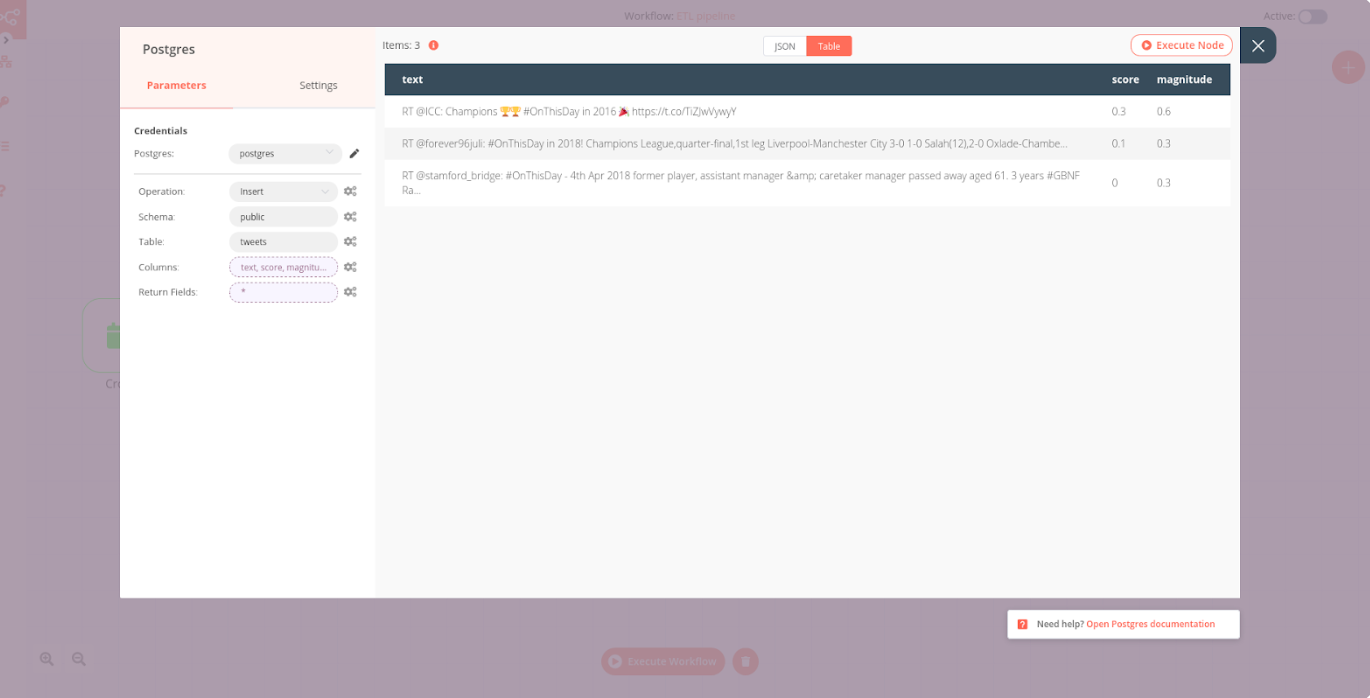
After executing the node, you can check if the tweets have been inserted in the table by running SELECT * FROM tweets; in the terminal.
7. Filtering positive and negative tweets
Here comes another fun part related to sentiment analysis: filtering negative tweets. For this, we use the IF node, which allows us to split the workflow conditionally based on comparison operations. We define positive tweets as those with a sentiment score above 0. To configure the IF node with this condition, configure the parameters:
- Value 1: Current Node > Input Data > JSON > score
- Operation: Larger
- Value 2: 0
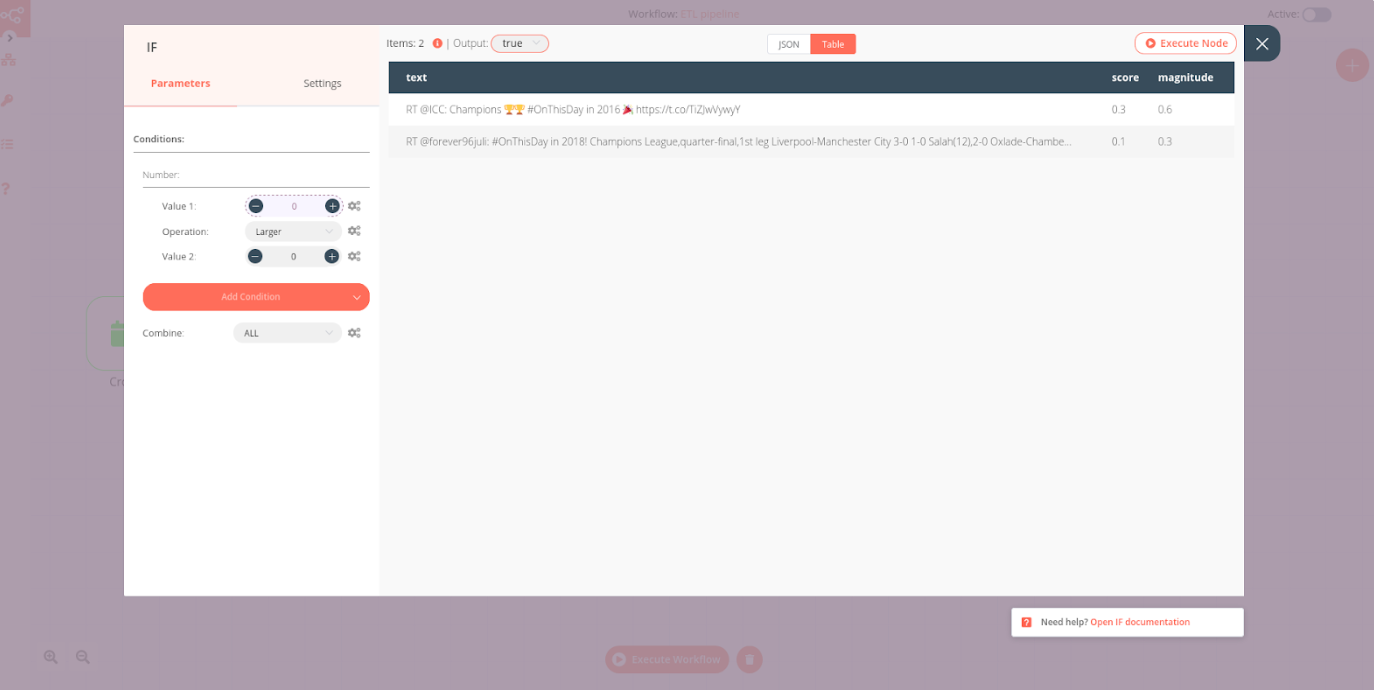
This condition determines the data flow to the following connection: if the sentiment score is greater than 0, the tweet will be sent to Slack, otherwise it will just be kept stored in the database.
8. Sending positive tweets to Slack
The way to send tweets from a database to a Slack channel is via a Slackbot, which you have to create from your Slack account. Follow the instructions on Slack and in our reference docs to learn how to create your Slackbot and get the necessary credentials (Access Token).
Once you have the Slack node credentials set up, configure the parameters:
- Resource: Message
- Operation: Post
- Channel: <YourSlackChannelName>
- Text: 🐦 NEW TWEET with sentiment score {{$json["score"]}} and magnitude {{$json["magnitude"]}} ⬇️
{{$json["text"]}}
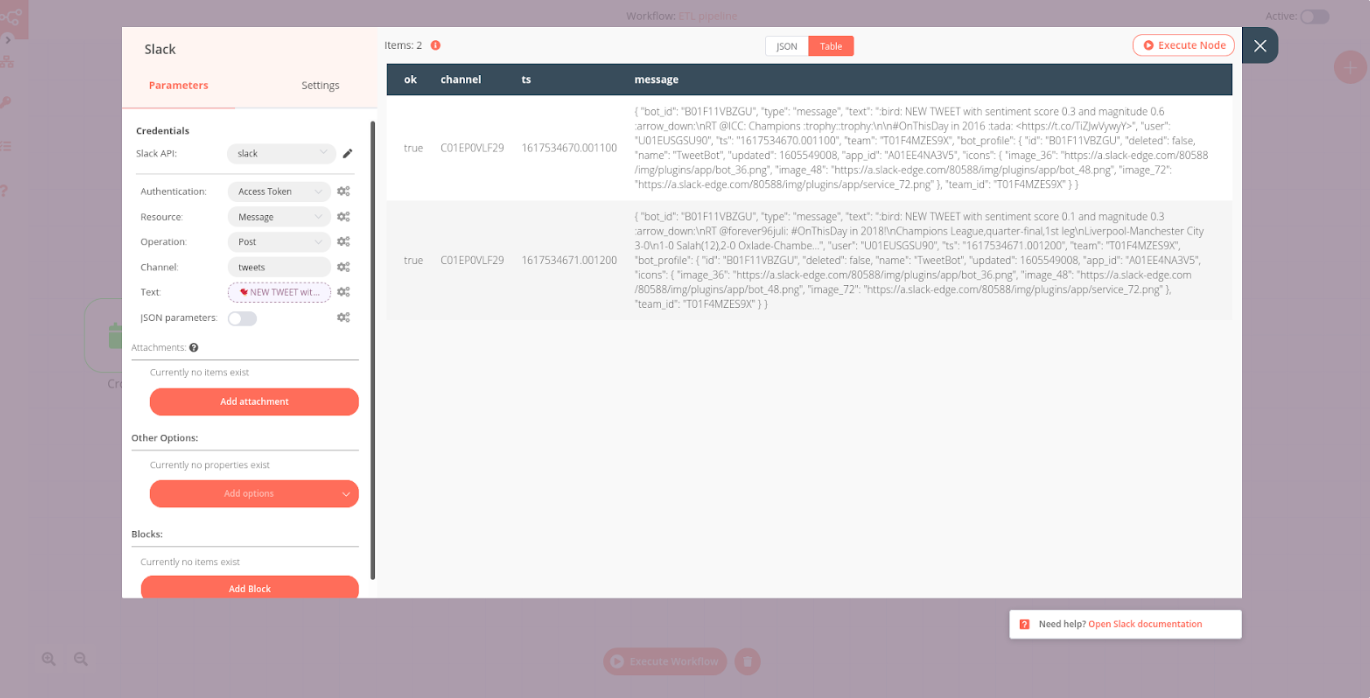
After executing the node, check your Slack channel for a new tweet:
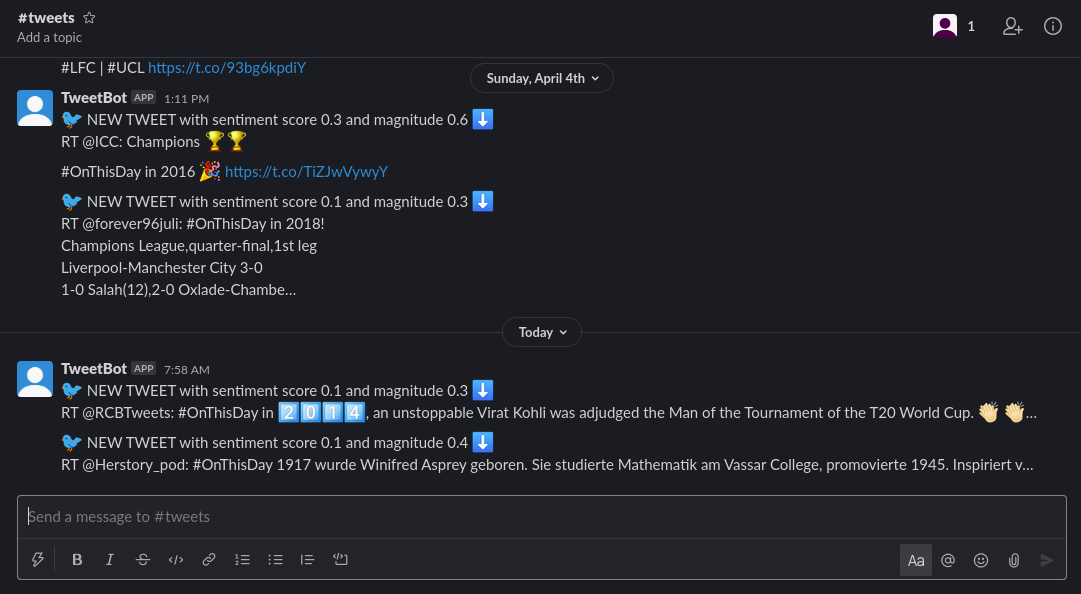
9. Ignoring negative tweets
The last node in this workflow is the NoOp node, which is used when we don't want to perform any operations. The purpose of this node is to make the workflow easier to read and understand where the data flow stops. Though this node is not necessary for our workflow, I included it to mark visually the false condition and make it clear that the workflow can be extended in this direction.
Finally, execute the whole workflow and activate it, so that it runs as scheduled. Also, check your MongoDB collection and Postgres database to make sure that the tweets have been inserted properly.
What's next?
Congrats – you now have an automated workflow that informs you every day about positive historical events that happened on that day! As usual, you can tweak and extend this workflow, for example by keeping track of whether a tweet has been processed already, adding an action for the condition when the IF node is false, or cleaning the text of the collected tweets to check whether it influences the sentiment score.
Of course, you can also build other ETL pipelines for various business use cases, such as product feedback at scale, Jira ticket automation based on customer sentiment, or regular database querying for reporting.
Start automating!
The best part is, you can start automating for free with n8n. The easiest way to get started is to sign up for a free n8n cloud trial. Thanks to n8n’s fair-code license, you can also self-host n8n for free.
Did you find this tutorial helpful? Feel free to share it on Twitter 🐦 and discuss it in the community forum 🧡 To get our latest content about automation, subscribe to our blog by adding your email address in the form below!