It’s not a secret that LLMs have attracted a lot of attention in the last two years. But let’s be honest: this happened for a good reason!
Today, LLMs are capable of processing vast codebases, supporting multi-language development, and even assisting in secure coding practices by identifying vulnerabilities and suggesting fixes.
For this reason, we classified the 20 best LLMs for coding to help you clarify the ideas around the best models, what they do, and why they’re interesting.
So, in this article, you’ll read the following:
- An overview of the current state of the LLMs landscape, with a bit of history;
- The 20 best LLMs for coding;
- n8n workflows that leverage AI and code to help you streamline your processes and how to set them up.
Whether you're an IT manager who wants to improve operations or a DevOps engineer who wants to automate complex workflows, this guide will teach you everything you need to know about leveraging LLMs for coding in your enterprise environment.
Let’s dive in!
LLMs for coding landscape

The image shows that LLMs for coding can be subdivided based on the license – open-source or commercial. Between these categories, the models can be:
- general-purpose (they manage text, code, images, and more),
- coding-specific (designed specifically for managing code),
- specific for research and fine-tuning,
- or designed for enterprises’ needs.
For the classification we made, we subdivided the LLMs into families based on who developed them. What’s interesting to note is that some families provide open-source models and others that have proprietary licenses, depending on particular needs.
Other families, instead, provide both general-purpose and coding-specific models (Ollama is an example).
This tells a lot about the state-of-the-art of the LLMs for coding: companies and teams are probably trying to strike a balance between democratizing and expanding the use of LLMs–thus, providing open-source models–and the need to have the right business model to continue developing the models–thus, providing models with proprietary license.
The 20 best LLMs for coding
Yes, we know: this landscape is vast. This is why we’ve prepared a list of the 20 best LLMs for coding to help you clarify contexts, use cases, and peculiarities of the current state-of-the-art models.
Let’s discover them!
The Claude 3 family
Best for: Generating new software architecture.

Claude 3, developed by Anthropic, is a family of three AI models. Each has different performance capabilities, allowing users to have the right balance of cost, speed, and intelligence.
This family of LLMs consists of:
- Claude Haiku: The fastest model that can execute lightweight actions, with industry-leading speed. Suitable for tasks that require speed but are also cost-effective is, however, the least performing among the family.
- Claude Sonnet: Provides the best combination of performance and speed for efficient, high-throughput tasks. It is the middle-of-the-road model among the three and it’s more inclined to serve enterprise tasks like data processing, quality control, and product recommendations.
- Claude Opus: Is the highest-performing model, and can handle complex analysis, longer tasks with many steps, and higher-order math and coding tasks. It outperforms Sonnet and Haiku on many evaluation benchmarks for AI systems.
License:
Proprietary/Commercial
Key features for coding:
The Claude 3 family is a general-purpose LLM family, so is suitable for coding tasks, among others. They can work with a wide variety of programming languages and frameworks–but they are particularly proficient with Python and JavaScript/TypeScript.
Also, the Opus model excels in complex reasoning and advanced cognitive processing, making it suitable for generating new, high-level software architectures.
The GPT family
Best for: Refactoring and modifying specific parts of a program.

The GPT family–which stands for “Generative Pre-trained Transformers”–is a family of LLMs based on the transformer deep learning architecture introduced by OpenAI.
Among the different products and models released by OpenAI, ChatGPT is certainly the most famous. Its latest versions are currently based on the following models:
- GPT-3.5 Turbo: This general-purpose model can understand and generate natural language or code and has been optimized for chatting by using the Chat Completions API.
- GPT-4o/mini/audio/realtime: This sub-family of models is versatile and highly intelligent. The GPT-4o, for example, accepts both text and image inputs, and produces text outputs. Its ‘mini’ version is fast and ideal for fine-tuning. The ‘Realtime’ and ‘Audio’ versions, instead, respond to audio and text inputs in real time and accept audio inputs and outputs, respectively.
- GPT-o1/mini: This series of models is trained with reinforcement learning to perform complex reasoning. In particular, the o1 models’ reasoning is designed to solve hard problems across domains; the o1-mini, instead, provides a fast and affordable reasoning model for specialized tasks.
License:
Proprietary/Commercial
Key features for coding:
The GPT family is a general-purpose LLM family, but it is also suitable for coding tasks and for a wide variety of programming languages and frameworks.
Its coding features that are particularly loved by developers are:
- API: You can access OpenAI models via API calls. This allows you to leverage its LLMs via your preferred programming language, allowing you to prompt its models by using the APIs. This helps you integrate the power of AI into your coding projects.
- Canvas: The GPT-4o provides Canvas. With Canvas you can highlight specific sections to indicate exactly what you want ChatGPT to focus on. This means, for example, that you can directly edit a portion of code you highlighted without asking ChatGPT to recreate it all or avoiding copy-paste it into the editor.
Codex
Best for: Coding in Python.

OpenAI Codex–the model that powers GitHub Copilot–is an advanced AI system designed to translate natural language into code, enhancing the programming experience by allowing users to interact with software through everyday language. As a descendant of GPT-3, Codex has been trained on a vast dataset that includes both natural language and billions of lines of publicly available source code, notably from GitHub repositories. This training enables Codex to proficiently understand and generate code in over a dozen programming languages.
Codex excels at breaking down complex problems into simpler components and mapping these components to existing code libraries or functions, which is often considered one of the more tedious aspects of programming. By automating this process, Codex lowers the barrier to entry for new programmers and enhances productivity for experienced developers.
License:
Proprietary/Commercial.
Key features for coding:
Codex is specifically fine-tuned for programming tasks, making it particularly suitable at understanding and generating code.
What makes it particularly stand out is its 14KB memory capacity for Python code. This allows it to consider more contextual information when generating code, leading to more accurate Pythonic outputs.
The LLaMA family
Best for: Long contexts handling.
The LLaMA (Large Language Model Meta AI) family is a series of advanced models developed by Meta. They are designed for natural language processing (NLP) tasks such as text generation, summarization, coding, reasoning, and more.
While LLaMA 3.x models are not specifically optimized for coding tasks–but can handle them due to their general training–the model specifically designed for coding purposes is Code LLaMA.
License:
Open-source (community license: free for research and commercial use but the training datasets are not publicly available).
Key features for coding:
Code LLaMA is the best choice of the family for coding tasks, as it is fine-tuned for programming. It offers advanced features like long context handling and support for multiple programming languages.
CodeLLaMA is itself a family of models and it is subdivided into:
- Base model: General-purpose coding model.
- Python-specific model: Fine-tuned for Python tasks.
- Instruct model: Optimized for instruction-following tasks, making it better at understanding and responding to natural language prompts about code.
Note that all these models can be downloaded from the Ollama library, available both for Python and Javascript.
Mistral AI
Best for: Generating code suggestions.

Mistral is a pre-trained, general-purpose, model developed by Mistral AI. Currently, their latest model is Mistral 7B which has been pre-trained with 7 billion parameters.
One of the standout features of Mistral 7B is its open-weight nature, meaning the model weights are freely available to the public. This openness has made it a popular choice among researchers, developers, and organizations looking to integrate advanced AI capabilities into their workflows without the constraints of proprietary systems.
License:
Open-weight model (the model weights are freely available for download and use under the Apache 2.0 license).
Key features for coding:
Despite being a general-purpose model, Mistral 7 B approaches the performance of specialized models like Code Llama 7 B in code-related tasks. Thanks to advanced attention mechanisms like Grouped-Query Attention (GQA) and Sliding Window Attention (SWA), which enhance its efficiency and ability to handle longer sequences, Mistral 7B has fewer parameters but is still able to perform as well as GQA and SWA.
This can be of particular interest to developers, as Mistral 7B also provides public APIs. Thus, it can be integrated into development tools like IDEs, enabling real-time code suggestions and improvements. It also supports fine-tuning for specific tasks, making it adaptable to various coding needs.
Palm 2
Best for: Coding into specialized programming languages.

PaLM 2 (Pathways Language Model 2) is a state-of-the-art large language model developed by Google, designed to advance natural language understanding and generation.
One of the standout features of PaLM 2 is its enhanced multilingual proficiency. It supports over 100 languages and demonstrates a deep understanding of cultural nuances, idiomatic expressions, and context-specific meanings. This makes it particularly effective for translation, cross-lingual tasks, and global applications.
License:
Proprietary/Commercial
Key features for coding:
As a general model, PaLM is also suitable for coding purposes, supporting a wide range of programming languages, including Python, JavaScript, Go, and more.
As it has been trained on a vast dataset, it can also generate code in specialized languages like Prolog, Fortran, and Verilog.
The Gemini family
Best for: Integrating into the Google ecosystem.

The Gemini family, developed by Google DeepMind, represents a diverse range of capabilities tailored to various use cases, from high-performance reasoning to efficient on-device tasks.
Currently, there are the following models in this family:
- Gemini 2.0 Flash Experimental: The latest and most advanced model in the lineup. This experimental model introduces multimodal capabilities, including native image generation, text-to-speech, and real-time interaction through the Multimodal Live API.
- Gemini 1.0 Ultra and Gemini 1.5 Pro: The earlier models in the Gemini family that cater to more established use cases. Gemini 1.0 Ultra is the largest model in the family, designed for highly complex tasks like advanced coding, mathematical reasoning, and multimodal problem-solving. Gemini 1.5 Pro strikes a balance between performance and versatility, offering a 2 million token context window and the ability to process large-scale data, such as hours of audio or thousands of lines of code.
- Gemini 1.0 Pro and Gemini 1.0 Nano: These are for more lightweight and specialized applications. Gemini 1.0 Pro, though set to be deprecated in the first months of 2025, focuses on natural language tasks, multi-turn conversations, and code generation, serving as a foundational model for text-based applications. On the other hand, Gemini 1.0 Nano is optimized for on-device tasks, offering efficient performance for mobile and embedded systems.
License:
Proprietary/Commercial
Key features for coding:
Among all the models, Gemini 2.0 Flash Experimental and Gemini 1.5 Pro excel in coding tasks. In particular, they can process extensive codebases, with context windows of up to 2 million tokens. This allows them to handle large-scale projects, such as analyzing thousands of lines of code or managing complex multi-file systems.
Finally, Gemini models can be integrated into Google's ecosystem, such as Google Cloud's Vertex AI, where developers can access its coding capabilities through the Gemini Developer APIs. This makes it easy to incorporate its features into development pipelines and workflows.
CodeBERT
Best for: Clone detection.

CodeBERT, developed by Microsoft, is a pre-trained model designed for programming and natural languages. It is part of a series of models designed to improve code understanding and generation tasks.
CodeBERT is a multi-programming-lingual model trained on natural language (NL) and programming language (PL) pairs across six programming languages: Python, Java, JavaScript, PHP, Ruby, and Go. The model is particularly useful for tasks such as code search, code documentation generation, and embedding generation for NL-PL pairs.
License:
Open source (MIT License).
Key features for coding:
CodeBERT is built on the Hugging Face Transformers framework, making it easy to load and use pre-trained models. Developers can integrate it into their workflows with minimal effort using familiar tools like AutoTokenizer and AutoModel.
As is it pre-trained on natural language and programming language pairs across six popular programming languages (Python, Java, JavaScript, PHP, Ruby, and Go), this makes this model particularly specialized in those programming languages.
Also, CodeBERT generates embeddings for both code and natural language, enabling tasks like code search, where developers can search for code snippets using natural language queries. It even supports semantic understanding of code, making it useful for tasks like code classification, clone detection, and bug detection.
The Command family
Best for: Real-time applications.

The Command family of models by Cohere is a suite of high-performance, scalable language models designed to deliver strong accuracy and efficiency. These models are tailored for enterprise use, enabling businesses to transition seamlessly from proof-of-concept stages to production-grade applications.
By balancing efficiency and accuracy, these models are ideal for businesses looking to integrate AI into their workflows for tasks like content generation, document analysis, and large-scale data processing.
License:
Proprietary/Commercial.
Key features for coding:
Command models are optimized for tool use, meaning they can interact with external tools like APIs, databases, or search engines to enhance their functionality.
With a context window of up to 128K tokens (in models like Command R7B), these models can process and understand large codebases, making them suitable for complex coding tasks. Also, Models like Command R7B are optimized for high throughput and low latency, making them ideal for real-time.
The Falcon family
Best for: Deployment on low-resource devices.

The Falcon LLM models, developed by the Technology Innovation Institute (TII) in Abu Dhabi, represent a cutting-edge suite of open-source large language models (LLMs) designed to democratize access to advanced AI.
This ecosystem currently includes the following models:
- Falcon 3: Lightweight and resource-efficient model that can run on minimal infrastructure, including laptops, without sacrificing performance. It includes four scalable models optimized for multilingual and diverse applications.
- Falcon Mamba 7B: The first open-source State Space Language Model (SSLM), offering low memory costs and the ability to generate long text blocks efficiently. It outperforms traditional transformer models like Meta’s Llama 3.1 8B and Mistral 7B.
- Falcon 2: A multilingual and multimodal model with vision-to-language capabilities. It outperforms Meta’s Llama 3 8B and rivals Google’s Gemma 7B, with plans to incorporate "Mixture of Experts" (MoE) for enhanced performance.
- Falcon 40B: A 40-billion-parameter model trained on one trillion tokens, designed for both research and commercial use. It was the first open-source large language model released with weights under the permissive Apache 2.0 license.
- Falcon 180B: A 180-billion-parameter model trained on 3.5 trillion tokens, ranking as one of the most powerful open-source LLMs globally. It is available for research and commercial use under a royalty-free license.
License:
All Falcon models are open source, but Falcon 180B has additional licensing conditions for specific use cases, particularly for shared hosting services.
Key features for coding:
Falcon models are built on a transformer-based causal decoder architecture, which is well-suited for coding tasks, but they are general-purpose models.
However, the best LLM for coding in this family is Falcon 3 as it offers quantized versions, making it efficient for deployment on low-resource devices, which can be useful for lightweight coding tools.
The Stability family
Best for: Filling code in the middle of tasks (FIM).

Stability AI's language models, branded under the "Stable LM" series, are designed for a wide range of applications, from multilingual communication to specialized tasks like coding and instruction-following. In addition to general-purpose LLMs, Stability AI offers specialized models like Stable Code 3B and Stable Code Instruct 3B, which are optimized for software development tasks such as code generation and completion.
Here’s how this family of LLMs is composed:
- Stable LM 2 12B: A 12-billion-parameter multilingual model trained in English, Spanish, German, Italian, French, Portuguese, and Dutch, available in both base and instruction-tuned versions for versatile applications.
- Stable LM 2 1.6B: A smaller, 1.6-billion-parameter multilingual model offering state-of-the-art performance in multiple languages, designed for lightweight and efficient deployment.
- Stable Code 3B: A 3-billion-parameter model optimized for accurate and responsive code completion, comparable to larger models like CodeLLaMA 7B but more efficient.
- Stable LM Zephyr 3B: A lightweight 3-billion-parameter chat model fine-tuned for instruction-following and Q&A tasks, offering responsive and user-friendly interactions.
- Japanese Stable LM: A specialized model trained exclusively in Japanese, achieving top performance on various Japanese language benchmarks.
- Japanese Stable LM 2 1.6B: A 1.6-billion-parameter Japanese language model available in both base and instruction-tuned versions, tailored for diverse Japanese language tasks.
- Stable Beluga: A powerful LLM with exceptional reasoning abilities, suitable for tasks like copywriting, answering scientific questions, and generating creative ideas.
- Stable Code Instruct 3B: An instruction-tuned version of Stable Code 3B, capable of handling code generation, math, and other software development tasks with natural language prompts.
License:
The base Stable LM models, such as Stable LM 2 12B and Stable LM 2 1.6B, are open source and can be freely used, modified, and adapted for various purposes.
Fine-tuned models, such as Stable LM 2 12B (Instruction-Tuned) or Stable Beluga, trained on datasets like Alpaca or GPT4All, are released under proprietary licenses.
Key features for coding:
Among all the stability models, the best coding LLM is Stable Code 3B. In particular, it stands out for its ability to perform FIM (Fill-in-the-Middle) tasks. This ability allows this model to generate code that fills in a missing section in the middle of an existing code snippet. This is different from traditional code completion, which typically involves generating code at the end of a snippet.
Starcoder
Best for: Inferencing AI models.

StarCoder is a language model (LM) developed by the BigCode project, designed to handle both source code and natural language text. It has been trained on a diverse dataset that includes over 80 programming languages, as well as text from GitHub issues, commits, and notebooks and this makes it particularly adept at tasks like code generation.
The model is accessible through the Hugging Face Transformers library, enabling developers to integrate it into their workflows for coding assistance and generation. The model has been fine-tuned to function as a coding assistant, with a specific focus on enhancing its ability to follow instructions and align its outputs with human needs. This fine-tuning process leverages high-quality datasets, such as Q&A pairs from Stack Exchange, and employs tools like Hugging Face's PEFT and bits and bytes for efficient training.
License:
Open source (Apache-2.0).
Key features for coding:
Developers can fine-tune StarCoder on specific datasets or tasks to improve its performance in niche areas, such as domain-specific programming or unique coding styles. This flexibility allows organizations to adapt the model to their specific needs.
Furthermore, it supports efficient inference through optimizations like FP16, BF16, and 8-bit precision, which reduce memory requirements while maintaining performance. This makes it accessible for use on consumer-grade GPUs or even CPUs, depending on the task and model size.
The XGen family
Best for: Analyzing large code bases.

The XGen family of models, developed by Salesforce AI Research, represents a series of open-source large language models designed for long-sequence modeling. The flagship model, XGen-7B, is trained to handle input sequences of up to 8000 tokens, making it particularly suitable for tasks requiring extended context. Tis family includes three variants:
- XGen-7B-4K-Base supporting 4K sequence length.
- XGen-7B-8K-Base supporting 8K sequence length.
- XGen-7B-8K-Inst fine-tuned for instruction-based tasks and intended for research purposes.
These models are designed as auto-regressive samplers, enabling developers to generate text by providing a prompt and sampling from the model's output. The implementation is straightforward, utilizing the HuggingFace Transformers library for loading the models and tokenizers.
License:
Open source (Apache-2.0).
Key features for coding:
While primarily designed for long-sequence natural language processing tasks, the XGen models are also suitable for coding-related applications.
For example, with the support for up to 8000 tokens, the XGen-7B-8K-Base model can process and generate code that spans long files or complex scripts. This feature makes it the best LLM for coding from its family when you have to manage tasks like analyzing large codebases.
The Pythia family
Best for: Learning how LLM models learn and process information.

The Pythia LLM family, developed by EleutherAI, is a suite of autoregressive transformer models designed to facilitate research in interpretability, learning dynamics, and ethical AI practices. The project uniquely emphasizes transparency and reproducibility, offering public access to all models, data, and code.
This suite of LLMs includes eight model sizes, ranging from 14 million to 12 billion parameters, trained on approximately 300 billion tokens. A standout feature of Pythia is its 154 checkpoints saved throughout training, enabling researchers to study the learning dynamics of LLMs in unprecedented detail. All models were trained on the same dataset, "The Pile," in the same order, ensuring consistency and enabling causal interventions in the training process.
License:
Open source (Apache 2.0).
Key features for coding:
Pythia models are a general-purpose LLM family. However, its 154 training checkpoints make it particularly interesting for coding. These checkpoints are available for each model, so developers can fine-tune Pythia models for specific coding datasets or tasks, such as improving performance in a particular programming language or domain.
This particular design enables researchers to study how the models learn and process information, which can be applied to understanding how the models handle coding tasks, such as syntax generation or error detection.
The WizardLM family
Best for: Debugging code.

WizardLM is a family of LLMs designed to follow complex instructions that excels in various tasks, including natural language processing, code generation, and mathematical reasoning. Built upon the Evol-Instruct framework, WizardLM leverages a method to automatically generate diverse and challenging open-domain instructions using LLMs instead of human input. This approach enhances the model's ability to handle a wide range of skills and difficulty levels, making it a versatile tool for both academic and practical applications.
The project includes several specialized models, such as WizardCoder for coding tasks and WizardMath for mathematical reasoning, each fine-tuned to achieve state-of-the-art performance in its respective domain.
License:
While the WizardLM project provides access to many of its model weights and resources for academic and research purposes, not all WizardLM models are fully open-source.
Key features for coding:
Among the family models, the best coding LLM is the WizardCoder series, as it is designed to excel in coding-related tasks.
In particular, the WizardCoder models are optimized for multi-turn interactions, allowing them to engage in iterative problem-solving and debugging processes. This feature is useful for developers who need step-by-step assistance or clarification during coding tasks.
The Vicuna family
Best for: Understanding and managing multi-file projects.

The Vicuna family models, by the LMSYS, are a general-purpose chat assistant built on the foundation of Llama and Llama 2 architectures. The model is offered in three sizes: 7 billion, 13 billion, and 33 billion parameters, catering to varying computational needs and performance requirements.
These models are designed to handle a wide range of general-purpose chat tasks, making them versatile tools for applications like customer support, personal assistance, and educational purposes.
License:
Open-weight models (the models are built on top of the LLaMA and LLaMA 2 architectures, which are themselves released under a non-commercial license. So, their weights are publicly available for download and use but their usage is subject to the licensing terms of the underlying LLaMA and LLaMA 2 models).
Key features for coding:
The Vicuna models are general-purpose conversational models, but they exhibit features that make them useful for coding-related tasks.
In particular, Vicuna excels in multi-turn conversations, which is advantageous for iterative coding tasks, so developers can engage in back-and-forth discussions with the model to refine code, troubleshoot errors, or explore alternative solutions. Also, the v1.5-16k variant of supports a context size of up to 16,000 tokens: this extended context length makes this the best LLM for coding from its family in the particular case where coding tasks involve analyzing or generating large codebases and understanding multi-file projects.
The SQLcoder family
Best for: Working with SQL queries.
SQLCoder, developed by Defog, is a specialized code completion model fine-tuned on the StarCoder base model, designed specifically for SQL generation tasks. It is optimized to convert natural language questions into SQL queries, making it particularly useful for database-related tasks.
The model is designed to handle complex SQL query generation by adhering to specific rules, such as using table aliases to avoid ambiguity and casting numerators as floats when creating ratios. It is capable of processing detailed database schemas and generating accurate SQL queries tailored to the schema's structure and it comes in two sizes: a 7B parameter version (4.1GB) and the full 15B parameter version (9.0GB), with the latter requiring at least 16GB of RAM for optimal performance.
License:
Open source (Apache-2.0).
Key coding features:
SQLCoder is fine-tuned specifically for SQL-related tasks, enabling it to convert natural language questions into accurate SQL queries. It is trained on a diverse dataset of SQL examples, allowing it to excel at simple and complex queries across various database schemas.
Also, as the models are open-source, developers can use, modify, and fine-tune them for specific use cases.
The Jamba family
Best for: REST APIs interaction.

The Jamba family, developed by AI21 Labs, represents a significant innovation in AI architecture that combines the strengths of Transformer and Mamba Structured State Space models. This hybrid architecture, known as the SSM-Transformer, addresses key limitations of traditional Transformer models, such as their large memory footprint and inefficiency with long contexts.
These models excel in handling extensive context windows, offering an industry-leading 256K token context length, which is particularly beneficial for tasks like document summarization, retrieval-augmented generation (RAG), and complex reasoning. This family currently includes two models–Jamba 1.5 Mini and Jamba 1.5 Large–both optimized for speed, quality, and resource efficiency.
License:
Open-source (Apache 2.0).
Key features for coding:
The Jamba family is a general-purpose one but offers interesting coding-related features.
For example, they support structured JSON output and function calls, which are essential for coding tasks. This allows developers to generate well-structured code snippets, API responses, or data outputs that can be directly integrated into applications. The ability to handle function calls also makes it easier to automate workflows and interact with APIs programmatically.
The Qwen family
Best for: Enhancing coding workflows.

The Qwen family, developed by the Alibaba Group's Qwen Team, represents a cutting-edge initiative aimed at advancing AI’s capabilities across various domains, including mathematical reasoning, coding, and multimodal understanding. The models are designed to address key challenges in AI, such as improving reasoning reliability and extending context length for better comprehension.
Here’s the current model's composition:
- Qwen2.5-Turbo: Supports an extended context length of up to 1 million tokens, enabling the processing of vast amounts of information in a single session.
- Qwen2.5-Coder Series: Open-source coding models with state-of-the-art coding capabilities, strong general reasoning, and mathematical skills.
- QVQ (Qwen Vision-Question): Combines language and vision to enhance cognitive capabilities, mimicking human perception and reasoning.
- QwQ (Qwen with Questions): A philosophically inspired model that emphasizes curiosity and deep reasoning across diverse domains.
License:
Many of the Qwen models, such as Qwen2.5 and its variants (e.g., Qwen2.5-Coder and Qwen2.5-Math), are open source under the Apache 2.0 license. However, exceptions include the 3B and 72B variants, which are not open-source.
Additionally, flagship models like Qwen-Plus and Qwen-Turbo are not open source but are available through APIs provided by Alibaba Cloud's Model Studio.
Key features for coding:
The Qwen family is a general-purpose one, and while they can all handle coding tasks, the best coding LLM of the group is the Qwen2.5-Coder series, as it is designed for coding.
These models are compatible with popular IDEs and can handle extensive context lengths. They also excel in generating structured outputs like JSON and enhancing its utility in coding workflows.
The CodeT5 family
Best for: Deployment as AI-powered coding assistants.

The CodeT5 family, developed by Salesforce Research, consists of two large language models designed for code understanding and generation. They have been widely recognized in the research community, with their papers being accepted at prestigious conferences like EMNLP and NeurIPS.
Here’s its current composition:
- CodeT5 model, introduced in 2021, is an identifier-aware, unified pre-trained encoder-decoder model. It was designed to handle tasks such as text-to-code generation, code autocompletion, and code summarization.
- CodeT5+ in May 2023, which represents an evolution of the original model. CodeT5+ introduces improvements in both architecture and performance, making it more effective for complex code understanding and generation tasks. The model is part of a broader effort to create open, large-scale LLMs for code, and it has been accompanied by research papers and resources to support its adoption. CodeT5+ is designed to be accessible to the developer community, with checkpoints available on platforms like Hugging Face for easy integration into workflows.
License:
Open-source (BSD-3-Clause license).
Key features for coding:
As these LLMs specialize in coding tasks, they’re your best option for custom deployment to use them as coding assistant.
Create LLM-powered workflows with n8n
So far, we reviewed the 20 best LLMs for coding.
It's important to understand that LLMs operate in isolation, without the workflow orchestration needed to make their outputs immediately actionable.
Here’s where n8n comes in!
n8n provides workflow integration: developers can use AI tools that don’t just generate code but also integrate with existing tools, and processes.
As a low-code solution specifically developed for automating workflows by using its UI, you can use its prebuilt nodes as they are, but also customize some of them by using code, if you need it.
Here are the interesting nodes in this scenario:
- The Code node: This allows you to write custom code in Python and Javascript and run it as a step in your workflows, allowing you to customize them.
- The HTTP request node: This allows you to make HTTP requests to query data from any service with REST APIs.
- The AI Agent node: This is an autonomous AI agent node that gives you six LangChain agent options, receives data, makes decisions, and acts to achieve specific goals.
- The AI coding with GPT node: This allows you to leverage AI-generated code while building automation workflows.
The AI coding with GPT node is currently in beta. It’s only available to cloud users and only supports JavaScript.
So, you can use n8n to move beyond standalone AI use cases to create scalable, end-to-end automation that delivers real business impact.
Let’s see some practical examples!
How to use LLMs for coding with n8n: Streamline code reviews

Let’s be honest: code reviews take time, especially if you’re working in a large enterprise and need to interact with different teams.
Also, sometimes, you may just need a “second opinion” to ensure that you gave your peers the right advice when reviewing their code.
So, fear no more: n8n is here to help you with that! We created a template useful for every engineer who wants to automate their code reviews in GitLab or (just get a 2nd opinion on their PRs). When set up, this workflow automatically reviews your changes in a Gitlab PR using AI: it’s triggered when you comment to a Gitlab PR, makes its analysis with ChatGPT, and replies to the discussion.
How to use LLMs for coding with n8n: Write SQL queries based on database schema

SQL queries: cross and delight of every engineer! Well, sometimes more a cross than a delight, isn’t it? We know it, and this is why we created a workflow that generates SQL queries prompting ChatGPT that are tailored to the database schema.
In this workflow, the AI agent accesses only the database schema, not the actual data. This allows the agent to generate SQL queries based on the structure of tables and their relationships, without having to access the actual data, thus providing a secure process.
How to use LLMs for coding with n8n: Create a chat assistant with Postgres memory
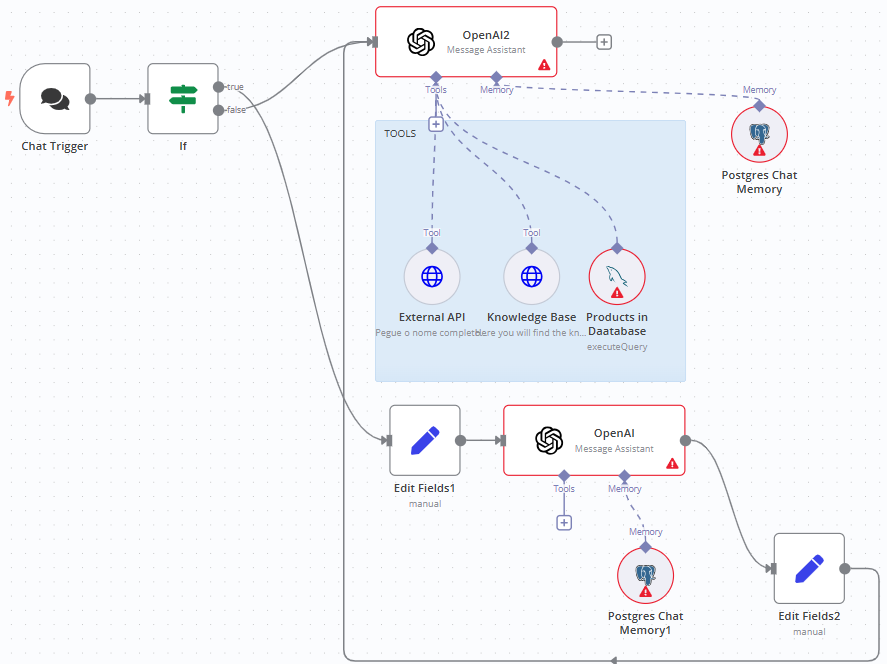
This workflow is an intelligent chatbot–that uses the OpenAI node–integrated with a backend that supports WhatsApp Business, and it’s designed to handle various use cases such as sales and customer support.
It also uses the Postgres Chat Memory for storing chat history and the HTTP nodes for connecting to anything that may be of help to your customers, like a knowledge base of your online shop. This powers up the interaction with the OpenAI node so that users receive contextualized responses.
If you are not a master in writing SQL queries, you can modify this workflow by using the schema we've described in the previous workflow that generates SQL queries based on the database schema.
How to use LLMs for coding with n8n: Automate chart generation

Often, when you query a database the output you need is a chart. However, this process often requires interacting with different software and it might be annoying, particularly if what you need is a chart for a prototype.
Wouldn’t it be thrilling if you could have an automated process that queries a database and provides a chart, but only if you actually need it? Yes, this is a workflow we created for you!
This workflow provides data visualization to a native SQL Agent, fostering data analysis and data visualization. It does so by connecting to a database and can query it and translate the response in a human format.
Wrap up
In this article, we’ve gone through an overview of the LLMs landscape and discovered the 20 best LLMs for coding.
However, while LLMs excel at different tasks – like writing code – they operate in isolation, leaving users to figure out integration and execution.
This is where n8n comes into the game: it bridges this gap by allowing you to embed LLM capabilities into dynamic, multi-step workflows.
What’s next?
Expand your knowledge on AI, automation, and workflow optimization with these in-depth resources:
- The Best 11 Open-Source LLM Applications – Discover these top 11 open-source LLMs and build advanced AI workflows with n8n LangChain integration.
- Top AI Tools for Business – Discover essential AI tools that can enhance efficiency and streamline operations.
- A Guide to AI Agents – Understand how AI agents work and how they can automate complex decision-making processes.
- AI Coding Assistants: Boost Developer Productivity – Explore how AI-powered coding assistants can speed up development and reduce errors.
- AI Integrations for Workflow Automation – Browse AI-powered integrations to enhance your automation workflows in n8n.
n8n also provides AI-powered workflows for all your needs that span from simple to very complicated. Give them a try: