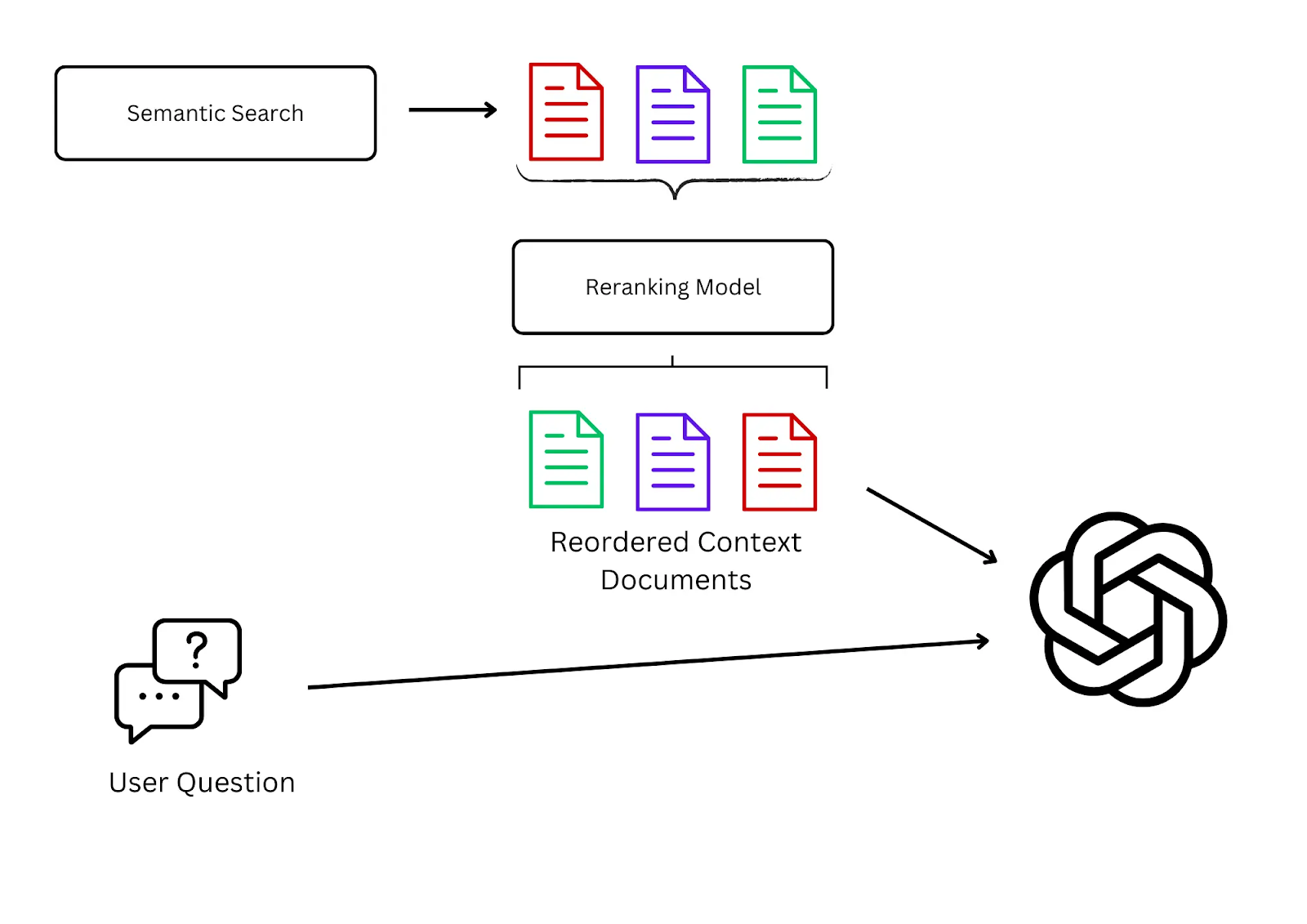
In a Retrieval-Augmented Generation (RAG) pipeline, a retriever fetches a set of candidate documents using a coarse filter via a vector similarity search. When these documents are retrieved, they are not ordered, so a less relevant document may be used before a more relevant one.
This is where we apply reranking models, which offer a second pass at the retrieval process to sort the retrieved text by semantic relevance with respect to the user’s query.
You can get an intuitive understanding of rerankers by thinking of search engines. When searching for something on Google, we expect that the most relevant results will be displayed on the first page. As we go through the following pages, the relevance of the results with respect to the query would decrease.
How rerankers improve retrieval quality
The reranker can significantly improve the search quality because it operates at a sub-document and sub-query level. It uses a more precise model, such as a transformer that jointly reads the query and the document to scrutinize the candidate texts.
The reranking process is straightforward:
- Retrieve: First, a search system uses vector embeddings to find a broad set of potentially relevant documents based on the user's query.
- Analyze: Then, the reranker takes these results and analyzes their semantic content considering the nuances of how the query terms interact with the document content.
- Reorder: Lastly, the model reorders the search results, placing the ones it deems most relevant at the top, based on this deeper analysis.
The AI ecosystem offers a range of open-source and commercial tools that can help improve RAG pipelines using rerankers. In the following section, we will present some options for deploying rerankers, followed by open-source and commercial tools.
How to deploy rerankers
Rerankers are standalone models that must be run independently. You can either choose to deploy and run the model directly or consume it in an as-a-service fashion. As such, you have three options:
- An -aaS delivery via an API
- A cloud-hosted option, or
- A self-hosted option for local deployments.
Option 1: as-a-Service (aaS)
The API model is perhaps the most straightforward approach to implementing rerankers. These are available from commercial solutions such as Cohere and Jina. This method allows developers to integrate reranking capabilities into their RAG pipelines with minimal infrastructure overhead. The commercial solutions expose API endpoints where users submit a query along with a list of retrieved documents, and the service returns these documents reordered from most to least semantically relevant. The underlying architecture typically processes user input by chunking documents and computing relevance scores for each segment, with the final document score determined by the highest-scoring chunk.
Option 2: Cloud-hosted deployments
Cloud-hosted deployment involves deploying reranker models through major cloud providers' AI platforms, combining the robustness and scalability of cloud infrastructure with the performance of commercial reranking models. This deployment method is particularly beneficial for organizations that require consistent performance, automatic scaling, and integration with existing cloud-based data pipelines. While not as convenient as the API option, hosting the model in your cloud minimizes dependency on the third-party vendor and can deliver on any security mandates, compliance certifications, and service level agreements.
Option 3: Self-hosted deployments
Self-hosted deployments allow enterprises to run reranker models within their own infrastructure, such that no data has to be processed by a third party. It also offers flexibility to customize deployment configurations, optimize for specific hardware, and integrate with existing enterprise systems. While this approach requires more technical expertise and infrastructure management, it delivers the benefits of real-time reranking with minimal latency while maintaining full control over data privacy and security protocols.
Open source reranking tools
Some of the most notable open source tools for reranking include the following:
ColBERT is a fast and accurate retrieval model, enabling scalable BERT-based search over large text collections in tens of milliseconds. It relies on fine-grained contextual late interaction, encoding each passage into a matrix of token-level embeddings. At search time, it embeds every query into another matrix and efficiently finds passages that contextually match the query using scalable vector-similarity (MaxSim) operators.
FlashRank uses Pairwise or Listwise rerankers. It’s a Python library that adds re-ranking to your existing search & retrieval pipelines.
RankZephyr is an open-source large language model (LLM) for listwise zero-shot reranking. It’s built on the 7-billion parameter Zephyr-β model (based on Mistral), and uses instruction fine-tuning to distill reranking capabilities from both RankGPT-3.5 and RankGPT-4 without requiring human-annotated query-passage relevance pairs.
Commercial reranking providers
Some examples of commercial rerankers include Cohere and Jina.
Cohere's reranker model employs cross-attention mechanisms for fine-grained ranking, enabling direct query-document comparison that significantly improves result quality for complex and under-specified queries. The model offers multilingual capabilities, supporting over 100 languages and delivering accurate retrieval across language boundaries from international and multilingual datasets. It can handle complex enterprise data formats, ranking multi-aspect and semi-structured documents—including emails, tables, JSON, and code—with the same precision as traditional long-form text. The solution is designed for enterprise deployment flexibility, offering private deployment options in virtual private clouds or on-premises environments for maximum data privacy and security control, while also being available through Cohere's platform and trusted cloud providers.
Jina Reranker offers comprehensive multilingual retrieval capabilities across over 100 languages, enabling effective document retrieval regardless of the query language used. The model features specialized function-calling support and advanced code search capabilities, allowing it to rank code snippets and function signatures based on natural language queries, making it particularly well-suited for Agentic RAG applications. Additionally, Jina Reranker v2 provides robust tabular and structured data support, effectively ranking the most relevant tables based on natural language queries and helping to sort different table schemas to identify the most appropriate one before SQL query generation, making it a versatile solution for enterprise environments with diverse data formats and multilingual requirements.
How reranking works
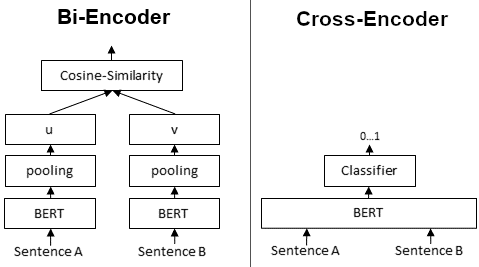
Bi-encoders and cross-encoders are two architectures used in natural language processing (NLP) for tasks like text similarity, retrieval, or ranking. Cross-Encoders can be used whenever you have a pre-defined set of sentence pairs you want to score. For example, you have 100 sentence pairs and you want to get similarity scores for these 100 pairs.
Bi-Encoders are used whenever you need a sentence embedding in a vector space for efficient comparison. Applications are for example, Information Retrieval / Semantic Search or Clustering.
Cross-Encoder achieve higher performance than Bi-Encoders, however, they do not scale well for large datasets. Clustering 10,000 sentences with CrossEncoders would require computing similarity scores for about 50 million sentence combinations, which takes about 65 hours. With a Bi-Encoder, you compute the embedding for each sentence, which takes only 5 seconds.
You can combine Cross- and Bi-Encoders. For example, you can use an efficient Bi-Encoder to retrieve the top-100 most similar sentences for a query, then a Cross-Encoder to re-rank these 100 hits by computing the score for every (query, hit) combination.
LLM-based reranking
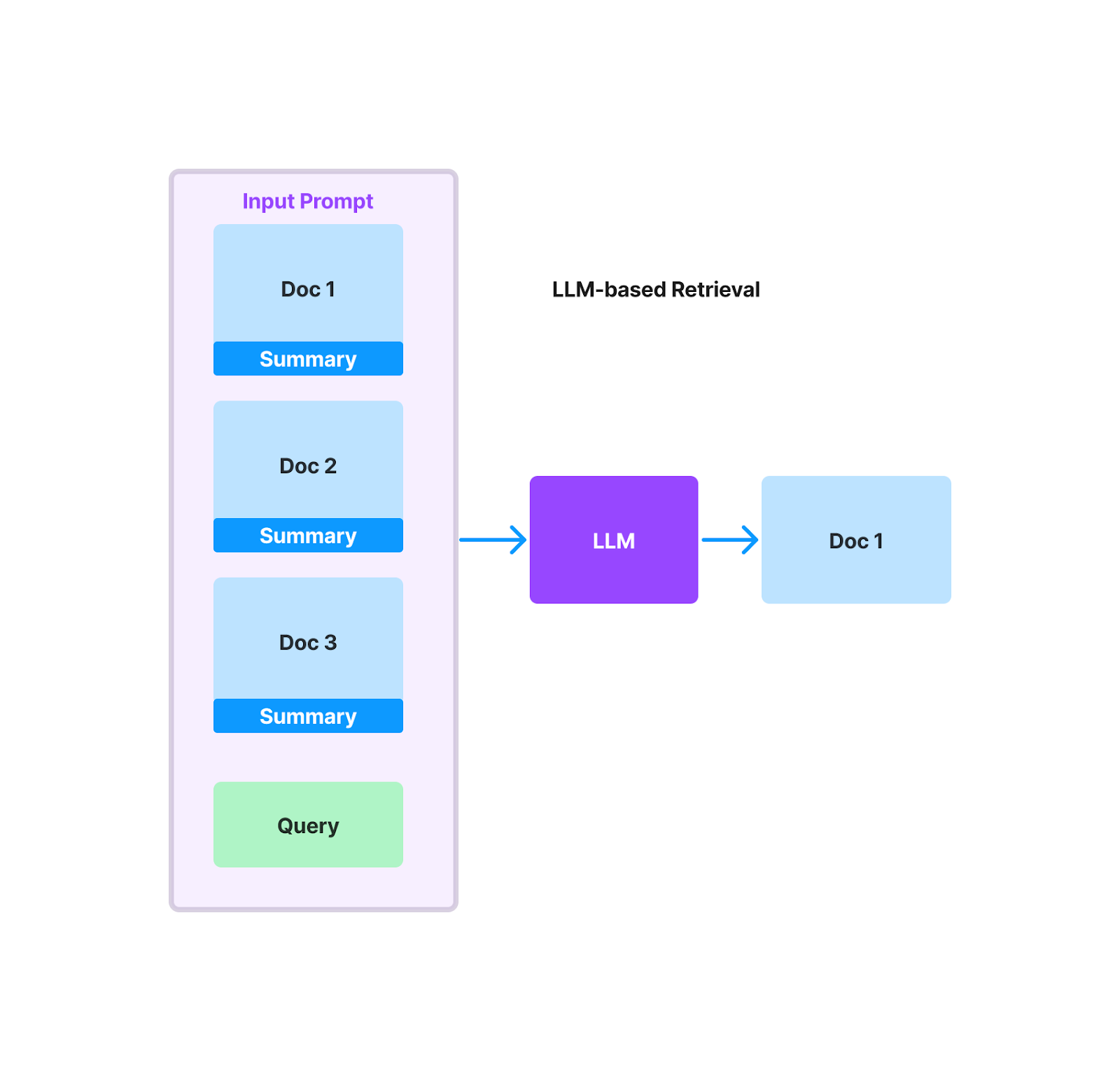
Just as when evaluating RAG, you can use an LLM to rerank retrieved documents. LLM-powered retrieval can return more relevant documents than embedding-based retrieval, with the tradeoff being much higher latency and cost. At a high-level, this approach uses the LLM to decide which documents and chunks are relevant to the given query. The input prompt would consist of a set of candidate documents, and the LLM is tasked with selecting the relevant set of documents as well as scoring their relevance with an internal metric.
If you are using LlamaInde, the LLMRerank is a module baked framework as part of the NodePostprocessor abstraction.
Reranking in n8n
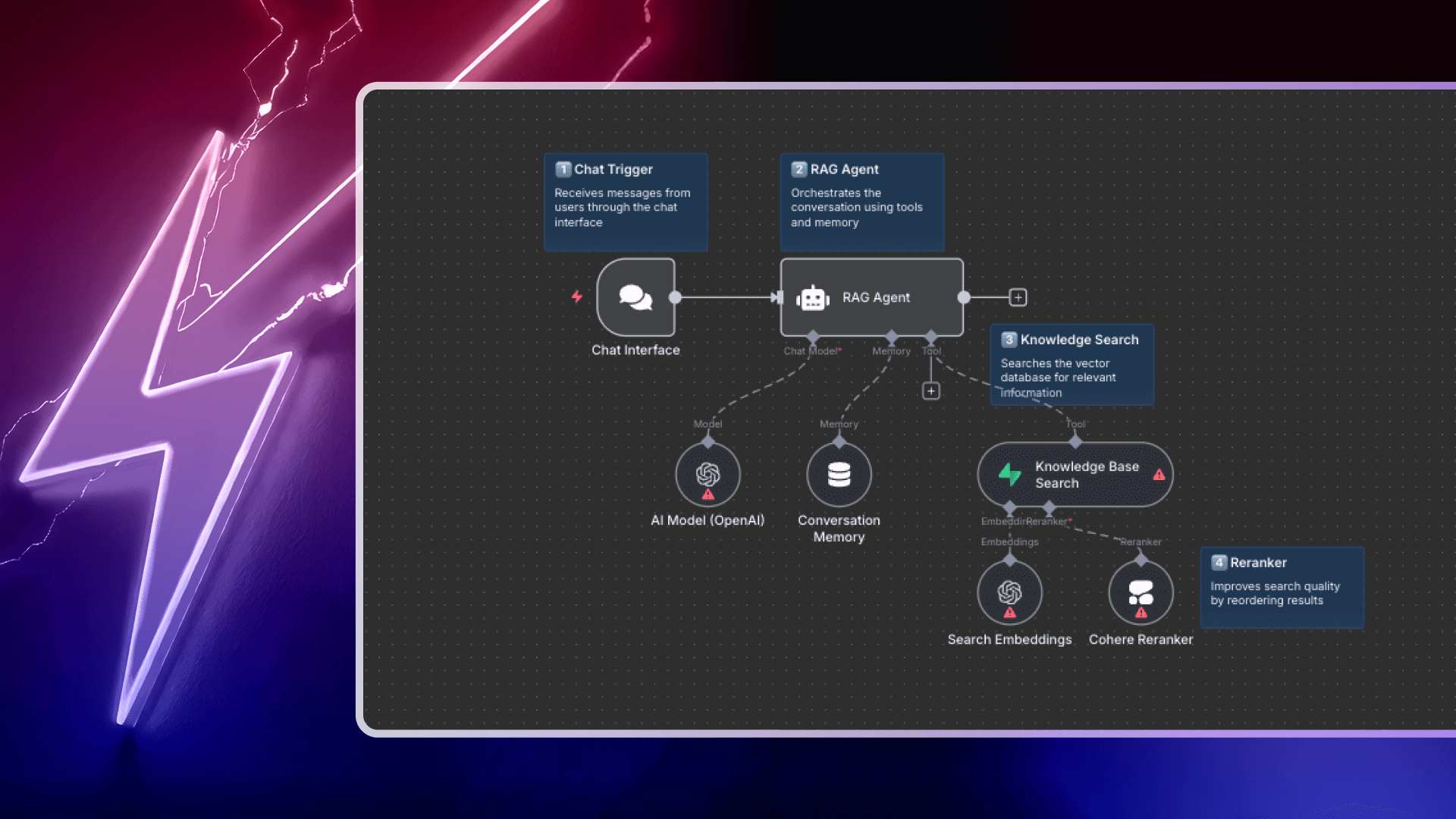
You can easily implement reranking in n8n using the Reranker Cohere node. It allows users to rerank the resulting chunks from a vector store. You can connect this node to a vector store. The reranker reorders the list of documents retrieved from a vector store for a given query in order of descending relevance.
This Intelligent AI chatbot with RAG and Cohere Reranker workflow template creates an intelligent AI assistant that combines RAG with Cohere's reranking technology to ensure the most relevant information is prioritized.