Evaluations for LLMs are the equivalent of performance monitoring for enterprise IT systems. While the applications may work without them, they will not be suitable for production deployments.
In this article, we’ll describe today’s most common LLM evaluation methods to help you bring your AI implementations to an enterprise-grade standard.
We'll also show how n8n's native evaluation capabilities make it easy to implement these methods directly in your workflows.
Matching evaluation methods to the LLM’s purpose
Evaluations tell us whether an LLM output is suitable for its intended purpose. As such, the most important aspect to determine before exploring the evaluation options is the LLM’s intended purpose.
Some of those include:
- Providing a chat interface to consumers
- Writing code
- Using the LLM as a natural language interface for a software product
- Automating internal processes using AI Agents
- Generating descriptions for retail products
- Summarizing unstructured email data into a spreadsheet
You most likely have an intuitive understanding that somebody using LLMs to write code is interested in a valid JSON output, while those who want to generate descriptions are not. To help, we have collated a range of evaluation methods available today either via open source or commercial products. This document is not a tutorial on how to use evaluations, but rather would help you understand the types of evaluations available today which can best serve your use case.
We can categorize evaluations into four broad categories:
The first is Matches and similarity, which is particularly useful when you already have a ground truth answer and are interested in the LLM reproducing it to some degree of fidelity.
The second is about Code Evaluations. While the most obvious use case for this is code generation, it is also important for instances where the LLM is used as a natural language interface. Imagine a SaaS HR product that has an LLM-based virtual assistant. To interact with the product, the LLM would write a database query, generate a script or call the product’s API to execute an action, which would be subject to the code evaluations.
The third option is LLM-as-judge, which, despite being somewhat recursive, is also flexible, highly configurable, and easy to automate. I have my doubts about judge LLMs, as they are just as reliable as the LLMs themselves. You can also imagine scenarios where you implement LLMs to judge the judge LLMs, ad infinitum. So, there must be some deterministic component as part of the LLM-as-Judge approach.
Lastly, Safety evaluations are the basis of guardrails, and measure whether the LLM output is toxic or contains sensitive information.
In addition to evaluating the LLM output, scoring the LLM’s context, especially with respect to context supplied via RAG, is highly important, and we explore this more in our blog post on Evaluations for Retrieval Augmented Generation (RAG) systems.
Matches and similarity
In this section, we talk about two types of evaluations. Matches and similarity, which we’ve grouped together because they often require ground truth, i.e. a pre-determined source of truth. These may be technical docs, contracts, laws, medical documents, etc.
Matches can either be exact, where the output is exactly equal to the target; or they can be based on regex, checking that the specified regular expression can be found in the output.
Matches are important for use cases such as re-generating content verbatim from technical documentation. Imagine a user asking an LLM assistant “how to open a support ticket”. An exact match would recreate the same content from the technical documentation page, while a regex-based match would tolerate some additional content from the LLM, like your typical “Sure! Here is how to open a support ticket”.
Going from matches to similarity, it’s important to note the Levenshtein Similarity Ratio, which measures string similarity. It’s the difference between two strings as the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one string into the other.
Similarity is more complex but also more useful. Semantic similarity embeds words into vectors to compare them in a numerical 0-1 value, where words that are similar score higher, and words that are not score lower. As such, we can measure how similar an LLM output is to an original source based on what the content means.
Code evaluations
Compared to normal text, code also has a functional component. Evaluating code generated by an LLM means to determine whether the code 1) runs, and 2) runs as intended. As discussed earlier, I also want to expand this area to also include natural language interfaces that generate code to interact with a software product.
- JSON validity - Check that the output is valid JSON by first ensuring the output is JSON, and then checking the schema conforms to a structure.
- Functional correctness evaluates the accuracy of NL-to-code generation tasks when the LLMs is tasked with generating code for a specific task in natural language. In this context, functional correctness evaluation is used to assess whether the generated code produces the desired output for a given input. Natural-language prompts can be paired with a suite of unit tests to check semantic behavior covering correct outputs, edge cases, control-flow handling, API usage, etc.
- Syntax correctness: This metric measures whether the generated code conforms to the syntax rules of the programming language being used. This metric can be evaluated using a set of rules that check for common syntax errors. Some examples of common syntax errors are missing semicolons, incorrect variable names, or incorrect function calls.
- Format check evaluates whether generated is using good formatting practices, such as indentation, line breaks, and whitespace.
LLM-as-judge
Independent LLMs can be used to evaluate whether responses are satisfactory. Some examples of evaluations that can be run by judge LLMs include helpfulness, correctness, query equivalence, and factuality.
Helpfulness evaluates whether an LLM's output is relevant to the original query. It uses a combination of embedding similarity and LLM evaluation to determine relevance. It uses an LLM to generate potential questions that the output could be answering, then compares these questions with the original query using embedding similarity, and lastly calculates a relevance score based on the similarity scores.
Correctness evaluates whether the AI's response is faithful to the provided context, checking for hallucinations or unsupported claims. It does so by analyzing the relationship between the provided context and the AI's response, identifying claims in the response that are not supported by the context.
SQL Query Equivalence checks if the SQL query is equivalent to a reference one by using an LLM to infer if it would generate the same results given the table schemas.
Factuality evaluates the factual consistency between an LLM output and a reference answer. OpenAI's evals are used by multiple providers to determine if the output is factually consistent with the reference. The factuality checker compares outputs based on the following:
- Output is a subset of the reference and is fully consistent
- Output is a superset of the reference and is fully consistent
- Output contains all the same details as the reference
- Output and reference disagree
- Output and reference differ, but differences don't matter for factuality
In n8n, LLM-as-judge evaluations are included in the built-in helpfulness and correctness metrics. Users can also create a custom metric and include an LLM as Judge in a sub-workflow that generates scores on outputs and passes them back as metrics.
Safety
Safety evaluations check whether the LLM response contains personal identifiable information, prompt injection attempts, or toxic content. These are particularly important when exposing the LLM application to consumers or other external use cases.
- PII Detection finds and sanitizes personally identifiable information in text, including phone numbers, email addresses, and social security numbers. It allows customization of the detection threshold and the specific types of PII to check.
- Prompt Injection and Jailbreak Detection identifies attempts made by users to jailbreak the system and produce unintended output. attempts in the input.
- Content Safety detects potentially unsafe content in text, including hate speech, self-harm, sexual content, and violence.
Metric-based evaluations in n8n
In n8n, evaluations are a native part of workflows and can be used to understand the LLM’s behavior against a test dataset. Metric-based evaluations can assign one or more scores to each test run, which can be compared to previous runs to see how the metrics change and drill down into the reasons for those changes.
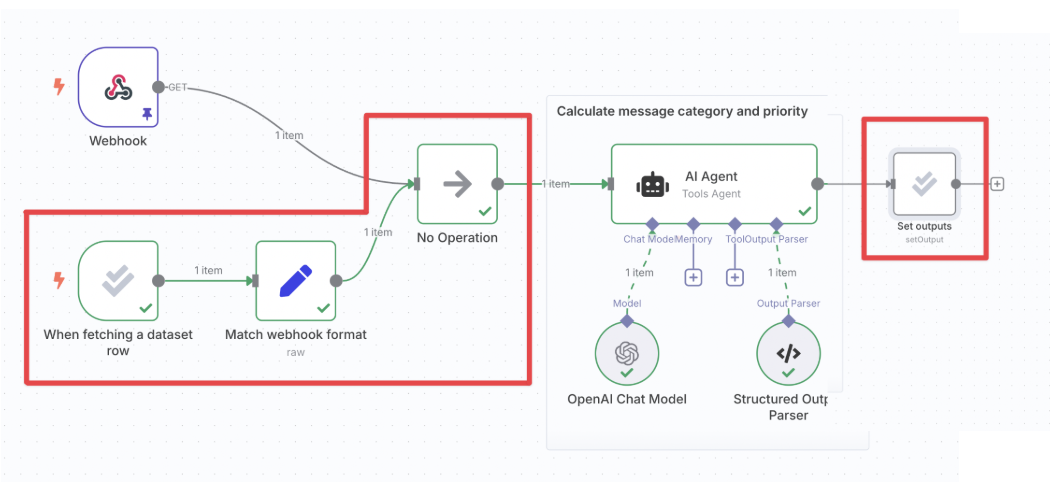
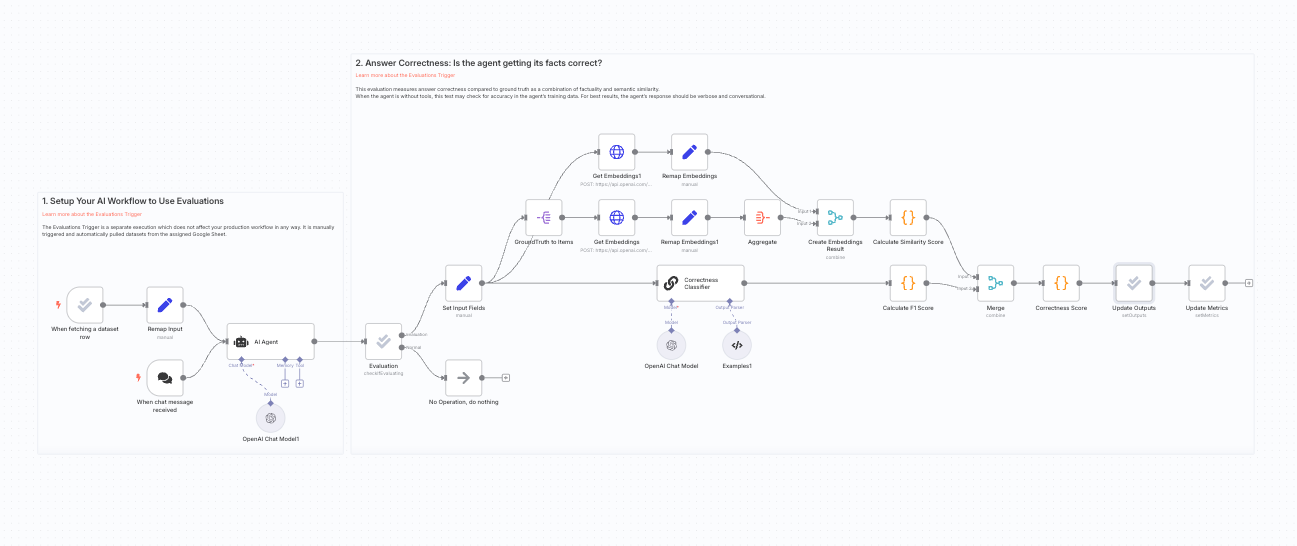
Evaluations are simply implemented in workflows with the Evaluations Trigger. It acts as a separate execution that does not affect your production workflow in any way. It is manually triggered and automatically pulls datasets from the assigned Google Sheet. Lastly, you need to populate the output column(s) of your dataset when the evaluation runs by inserting the 'Set outputs' action of the evaluation node and wiring it up to your workflow after it has produced the outputs you're evaluating.
n8n supports both deterministic and LLM-based evaluations and can measure whether the output's meaning is consistent with a reference output, if it exactly matches the expected output, whether the answer addresses the question, tools used, and determine how close the output is to a reference output. Users can also create custom metrics.
Here’s a workflow example of an LLM-based evaluation, where the workflow collects the agent's response and the documents retrieved, and then uses an LLM to assess if the former is based on the latter. A high score indicates LLM adherence and alignment whereas a low score could signal inadequate prompt or model hallucination.
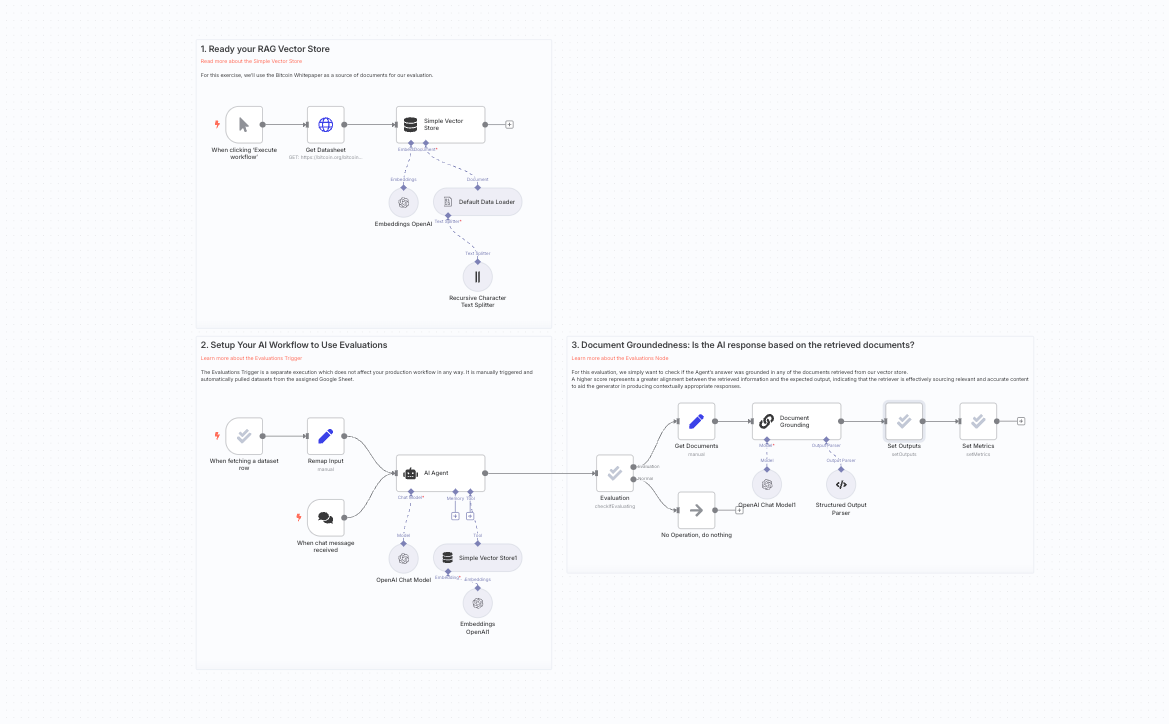
Another workflow example uses the RAGAS methodology, which is useful when the agent's response is allowed to be more verbose and conversational. The agent's response is classified in three buckets: True Positive (in answer and ground truth), False Positive (in answer but not ground truth) and False Negative (not in answer but in ground truth).A high score indicates the agent is accurate whereas a low score could indicate the agent has incorrect training data or is not providing a comprehensive enough answer.
Wrap up
Implementing evaluations as part of your AI workflows can help bring your automation logic to an enterprise-grade level. The built-in metrics within n8n give you all the tools to test the performance of your AI models without the need for external libraries or applications. Learn more about metric-based evaluations here.