In this article, we’ll learn how to integrate LlamaParse into n8n for automated invoice parsing and data extraction. Extracting data from PDF to Excel is the process of automatically pulling structured information like tables, line items, and invoice fields, from PDF documents and writing them into a spreadsheet.
If you’ve ever tried to automate document parsing for invoices, remittance notes, order forms or similar, you quickly realize that extracting table data from PDFs isn’t easy due to limitations with available parsing solutions. Third party professional OCR software technologies are expensive and slow whilst naive PDF-to-text converters lose all tabular structure making it near impossible to workaround for larger documents.
Enter LlamaParse, a new sophisticated document parsing service from LlamaIndex.ai. Parsing and understanding PDFs has become an increasingly popular problem space for Large Language Models (LLMs) and so LLamaParse was built for this very purpose. LlamaParse works by converting PDF tables to Markdown tables which are easier for LLMs to understand and thus allow LLMs to identify and extract table data more accurately.
Parsing and Extracting from Email Invoices
In this article, we’ll use the scenario where we receive PDF invoices by email which need to be reconciled by entering the details into a spreadsheet. We’ll use n8n to automate the entire process; from downloading the PDF attachment from the email, handing it off to LLamaParse for processing, using AI to extract the invoice data and finally writing it to our spreadsheet.
Prerequisites
- A cloud-hosted or self-hosted version of n8n.
Easiest way is to sign up for an n8n account at https://n8n.io. The workflow template in this article can be imported without having to rebuild the steps. - A LlamaIndex cloud account and API key.
You can get one by signing up for a free account at https://cloud.llamaIndex.ai - OpenAI account and API key.
You can find instructions here https://openai.com/blog/openai-api
Step 1: Setting up our LlamaParse Credentials in n8n
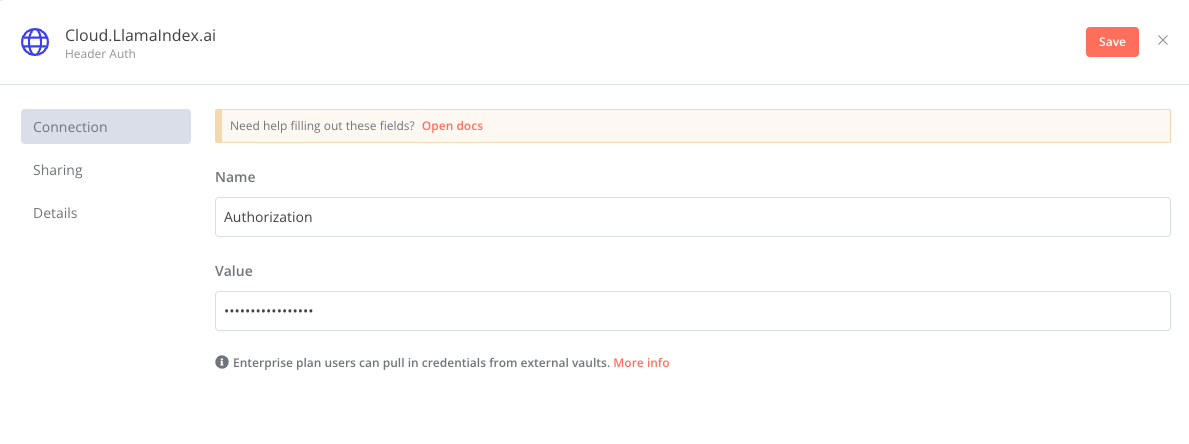
To use LlamaParse, we first need a LlamaParse API key which we can get for free by signing up to https://cloud.llamaIndex.ai. At time of writing, LlamaIndex is offering a free tier which allows for 1000 uploads a day.

Once you have the LlamaParse API key, create a Header Auth Credential that we will use when making calls to the LlamaParse API in our n8n workflow.
- Go to the Credentials tab
- Click the Add Credential button
- Search for Header Auth
- Enter "Bearer <API Key>" into the Value input box and click Save.
Step 2: Create the LlamaParse API workflow
Since n8n does not have a built-in node for LlamaParse, we’ll have to work directly with the LlamaIndex API. Don’t worry, this is quite manageable as there are only 3 APIs calls we need to make.
- API call to upload a PDF to the LlamaParse service.
https://docs.cloud.llamaindex.ai/API/upload-file-api-v-1-parsing-upload-post - API call to query the status of the PDF processing job. This may take longer if the PDF is large.
https://docs.cloud.llamaindex.ai/API/get-job-api-v-1-parsing-job-job-id-get - API call to fetch the parsed output of the PDF once the job is completed.
https://docs.cloud.llamaindex.ai/API/get-job-raw-md-result-api-v-1-parsing-job-job-id-result-raw-markdown-get
Here, I’ve implemented this flow using the HTTP request node, a SWITCH node to determine if the job is completed otherwise to query again and a WAIT node to throttle calls to stay within API service rate limits.

Step 3. Data Extraction using OpenAI GPT-4o
To extract the data from our parsed PDF output, we’ll use the LLM Basic Chain to feed it to the OpenAI GPT-4o Model and ask the model to pull out the relevant invoice data attributes we care about. Here’s the list of attributes we want for our scenario:
- Invoice date
- Invoice number and Purchase order number
- Supplier name and address, VAT identification number
- Customer name and address
- Any shipping addresses
- Line items, including a description of the goods or services rendered
- Price with and without VAT and the total price
The output should be JSON formatted so that we may easily insert this data as a row in our reconciliation spreadsheet. To achieve this, it is important that we use the Structured Output Parser and give it a JSON schema for the desired attributes.



Step 4. Add Email Trigger to Start Capture Invoices!
Now that the hard work has been done, we can set up a simple email trigger to watch for invoices as they come through. Depending on how you receive the invoices, you may need to filter based on subject line, labels or checking for attachments.
- Create an Email Trigger Node for your workflow
- Set an interval of how often the workflow should watch the inbox for new invoices.
- Under filters, apply any criteria which will help get actual email invoices sent to the workflow.
- Under options, be sure to check the option to download attachments. We’ll need this to get the actual pdf from the invoice. If you have multiple invoices, you may need to process them individually.


Step 5. Done!
In this article, we’ve successfully implemented a powerful AI-based PDF parsing and data extraction not only for invoices but for any PDF document with tabular data in n8n.
Utilizing powerful parsers like LlamaParse and models like GPT-4o for this use-case can provide significant productivity benefits at a fraction of the cost to traditional solutions such as OCR, whilst using n8n provides a simple no-code automation solution to reduce development and maintenance costs.