How many times have you read about ChatGPT so far?
And how many posts were actually useful for you?
With this article, you will learn how to go beyond basics and achieve interesting results with ChatGPT and other models from OpenAI.
We’ll also introduce a set of techniques to bridge the gap between ChatGPT and the n8n workflow automation tool:
- Simple one-step requests (examples 1.x);
- A brief introduction to prompt engineering (examples 2 & 4);
- Prompt chaining (examples 3.x);
- Extra examples for voice recognition and image generation (Whisper-1 & DALLE-2).
But before we get started, take a look at the landscape of various language models. There are dozens of them! And we only speak about language processing.
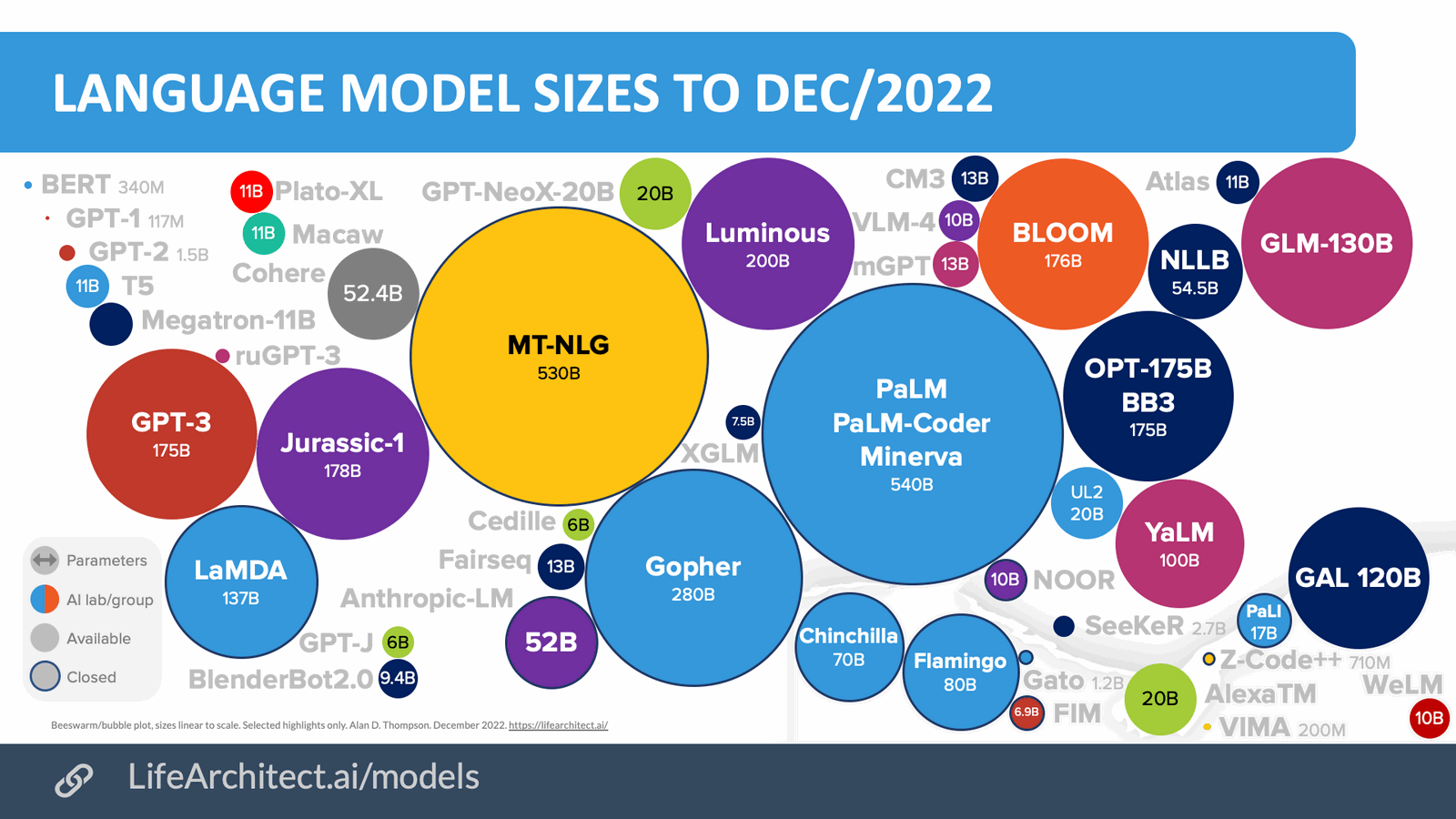
Techniques we discuss today (prompt engineering and prompt chaining) are transferable and can be used with other models, such as GPT-4, once they become public and connectable with n8n.
What is Gpt-3?
We are sure you’ve already heard about GPT-3. But what is it exactly?
Shortly speaking, in 2017 researchers from Google Brain have invented a deep learning model called a transformer. Soon after, the OpenAI team used this technique to improve natural language processing models. They released a chatbot called Generative pre-trained transformers (GPT), which was a game changer. GPT-3 is essentially a third generation of these models: bigger, stronger, but not necessarily faster 🙂
Gpt-3 vs ChatGPT vs other OpenAI models
Since the release of the GPT-3 model in 2020 OpenAI didn’t stop and continuously improved its models. At the moment they have eight sets of models. Most of the sets contain several models.
ChatGPT is an upgraded version of the GPT-3 model set. There are also models beyond GPT-3 from the same company, among the others there is DALLE-2 for image generation and Whisper for speech recognition.
ChatGPT meets n8n
With such an abundance of models from just a single company, we won’t be able to cover them all in a single article. Instead, we prepared a walkthrough with some useful techniques on how to get started with ChatGPT in your n8n projects.
First of all, you will need an account on the OpenAI platform. Once registered, you need to provide a valid payment method and generate an API key. In addition to that, your account also holds an Organisation ID. These two keys need to be added to the credentials for OpenAI Node.
Also, take a look at the example OpenAI & n8n workflow. We will be using it during the article:
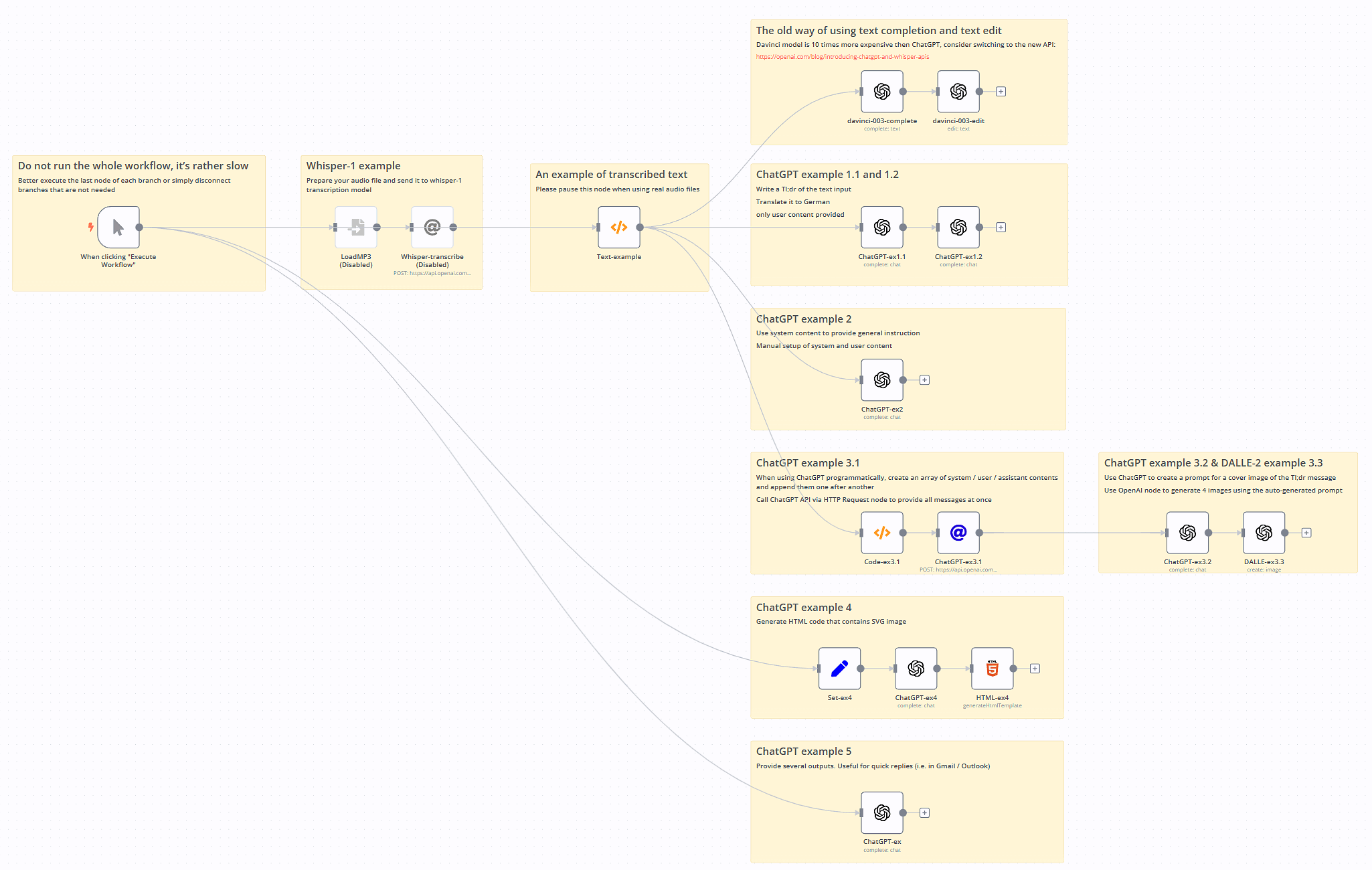
Working with GPT-3 the old way
InstructGPT API became available to the public just one year ago (it is also known as text-davinci-003). n8n users are able to work with the model in several modes: text completion, text edit and text insert. This conversational model is very easy to use, let’s consider two modes for now.
Summarize text
In text completion mode just provide all the instructions (they are called prompts) in one field and see the result.
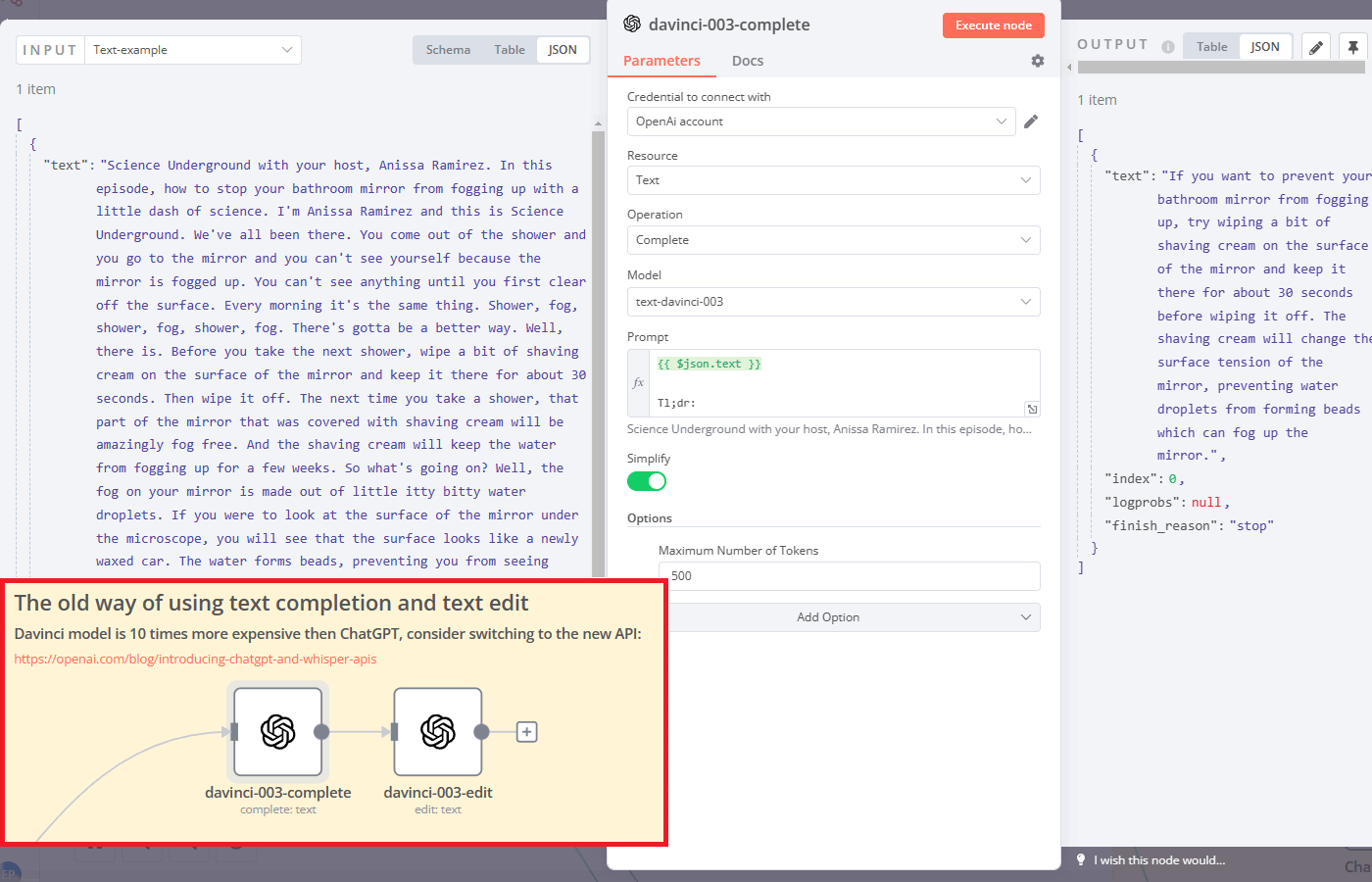
We used a transcript of a science podcast (more on that later) and used it as part of the prompt for the text-davinci-003 model. At the end of the prompt, we added Tl;dr to instruct the davinci model that we want to get a short summary of the text.
On the right side of the screenshot, you can see the result. Impressive, isn't it? You can automate loads of similar one-step tasks via n8n in just a few minutes.
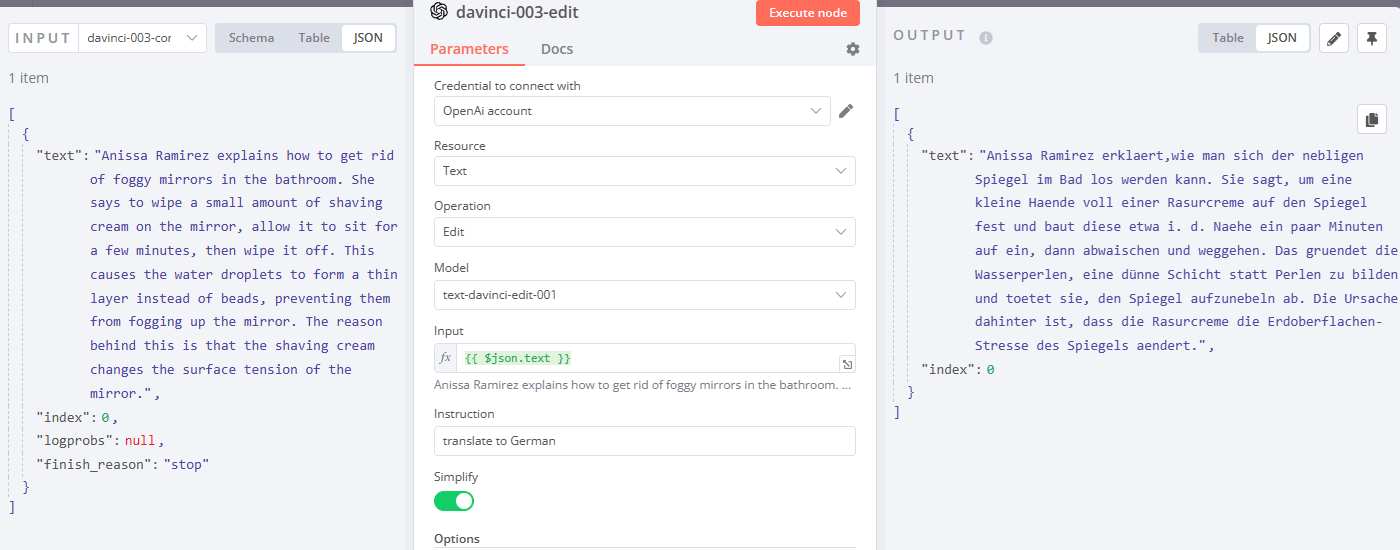
Translate text
In the same use case, take a look at the second OpenAI node. Here we pick an Edit Operation, provide the result of the previous node as input and write an Instruction: “Translate to German”. Here is what we get:
Use ChatGPT instead of InstructGPT
Before ChatGPT API was released earlier this month, InstructGPT was considered the most advanced conversational model from OpenAI. Starting from March 2023 it has become somewhat obsolete. First of all, ChatGPT is 10 times cheaper, and second - ChatGPT provides better-structured messages. How fast time flies!
Let’s take a look at the next several examples, this time with ChatGPT. First examples 1.1 and 1.2. demonstrate the same use case, but with a gpt-3.5-turbo model instead of text-davinci-003.
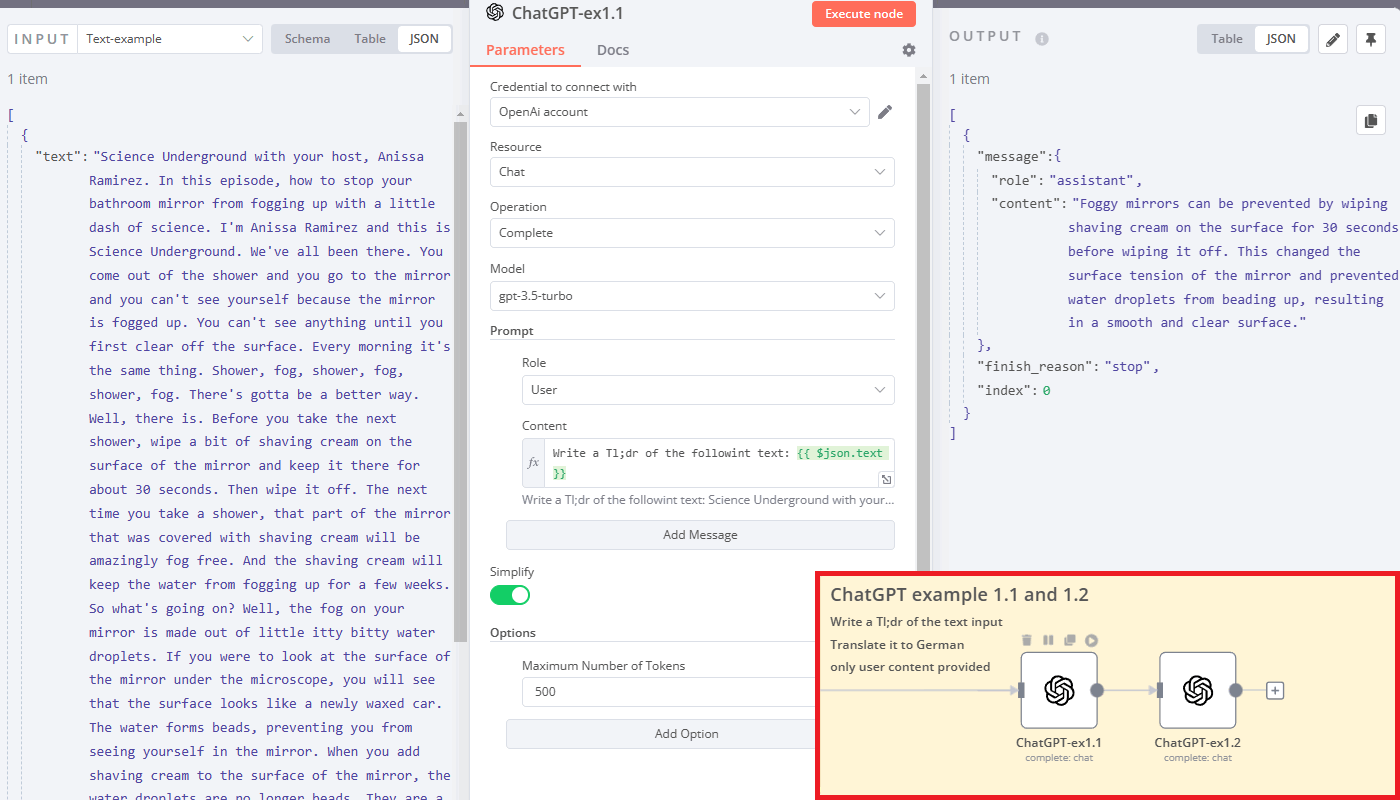
You can see that the prompt is provided in the message with a user role and some content. Why is it so difficult? ChatGPT better structures the chat history between AI and a user. AI responses are labeled as an assistant role as shown above.
Give ChatGPT a role
Yes, that’s true! ChatGPT can play a role.
If you want ChatGPT to react a certain way throughout the whole conversation, just store the instruction in the message with a system role. In example 2 we ask ChatGPT to add emojis to every message it produces:
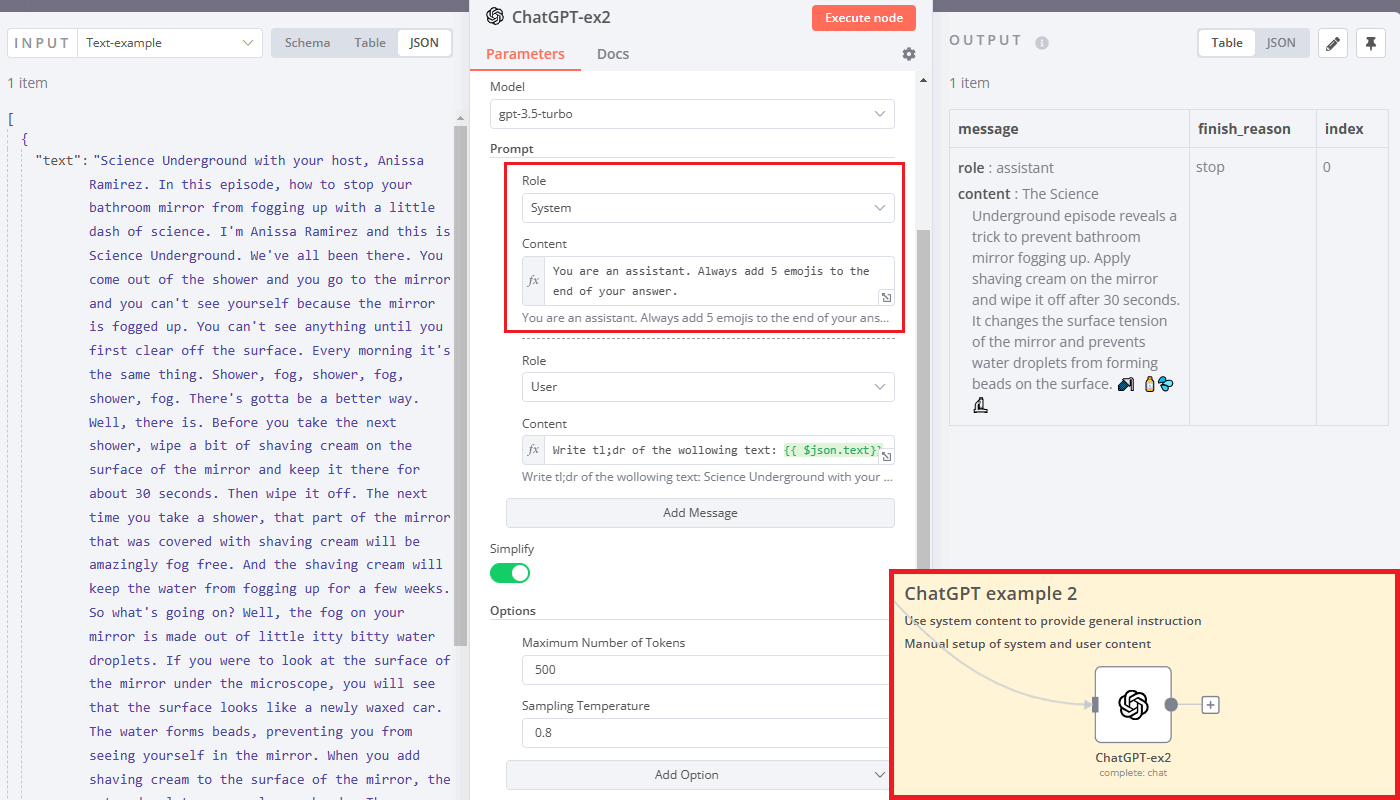
This is how funny chatbots are created: a single system prompt is added under the hood before the user requests. This makes ChatGPT behave in a certain way, i.e. always produce answers like a Shakespearean sonnet.
Make ChatGPT less of a Dory
Remember that Pixar cartoon Finding Dory? There was a fish with memory loss issues.
So far ChatGPT is completely clueless about the previous conversations. It only takes one system message, one user requests and produces a reply. The history of the chat is not saved anywhere.
To overcome this you need to make a trick with a Code node and call ChatGPT via the HTTP Request node. Take a look at example 3.1:
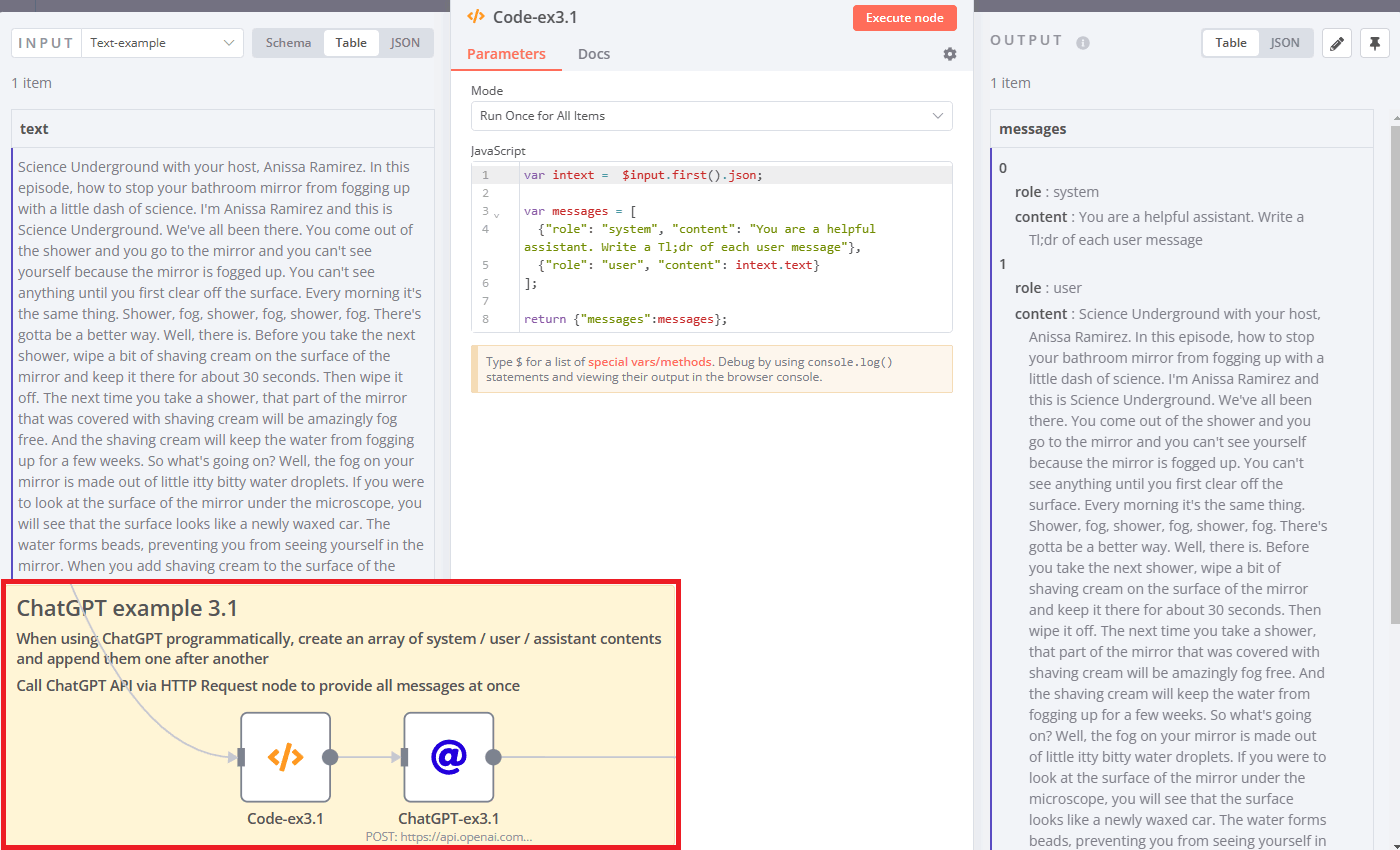
Example 3.1 has the same functionality as example 2, except for one important difference. Here Code node is used to generate an array with system and user roles for ChatGPT. Next, this array is passed as a messages parameter into an HTTP Request node.
So far it looks a bit over-engineered. But wait a second!
If you connect a database, you can store new user messages and the AI replies in one place. On the subsequent run you can fetch previous messages, combine them into an array and run ChatGPT once again. Here’s how you give an AI model a memory of the conversation.
Unlock the chain reaction achievement
In the previous example, we made ChatGPT aware of past messages. Essentially, this technique is called prompt chaining. You take the output of one model and use it as input for the next run or the new model.
Now we’ll figure out how this works with several different models.
Let’s take a look at examples 3.2 and 3.3.
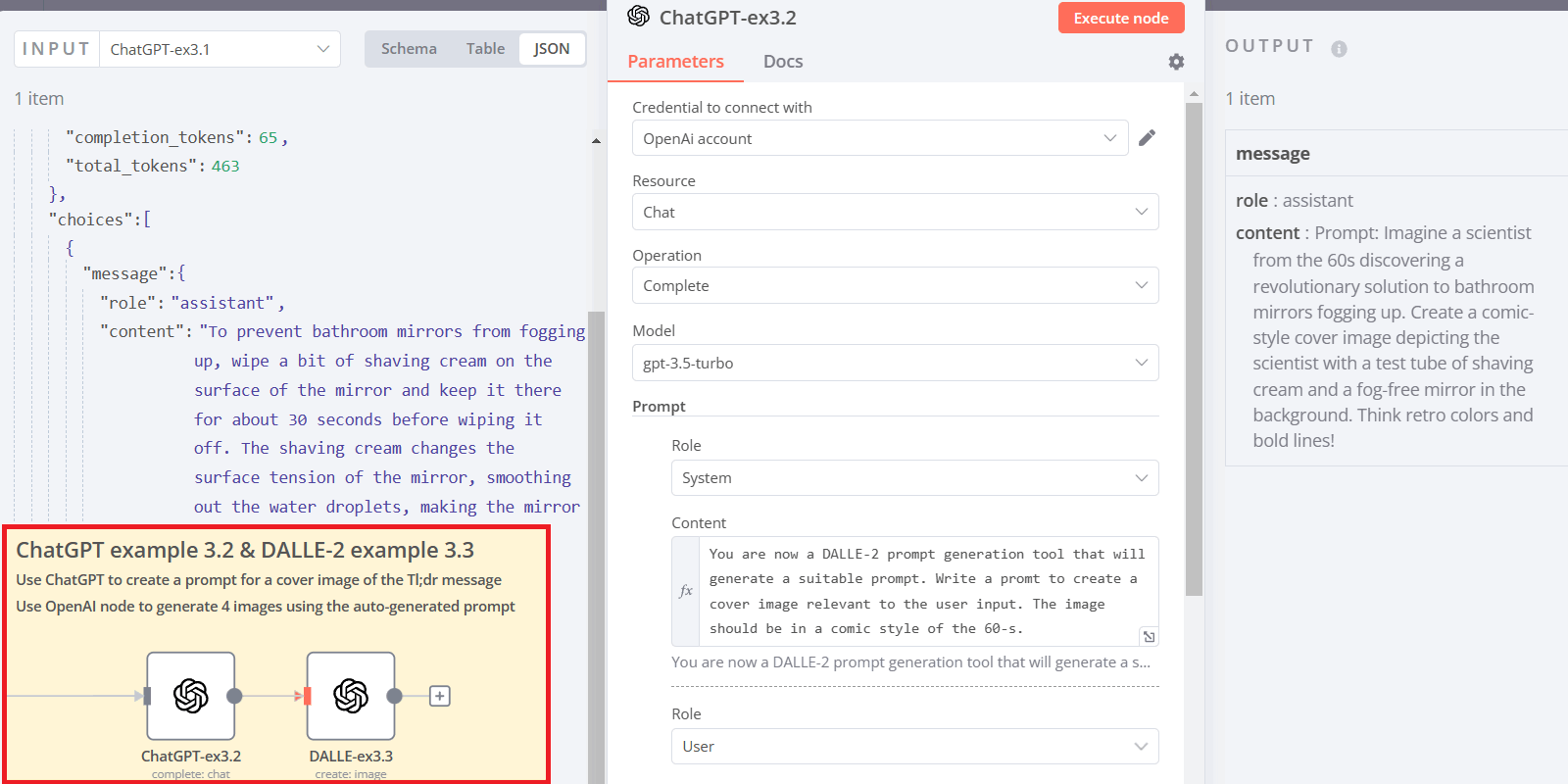
Here we take a Tl;dr output from one ChatGPT run and provide it as an input to the next OpenAI node with a different ChatGPT role. Finally, we generate several cover pages for our hypothetical post.

Prompt chaining is extremely powerful. You can combine different AI models to solve real-life business tasks. Consider the following scenarios:
- Load product reviews → Get sentiment → If positive, write a “thank you” reply; if negative write “sorry” message → Create a task for a team when a negative review is detected
- Read email → Get user intents and keywords → If user intent is a supported action, automate further steps, i.e. plan a meeting, open a task and so on
ChatGPT as a [very junior] programmer
Should you worry as a programmer that AI will steal your job? Most likely not, because another programmer capable of using AI will 🙂
Jokes aside, ChatGPT can create code snippets and functions. Let’s take a look at example 4.
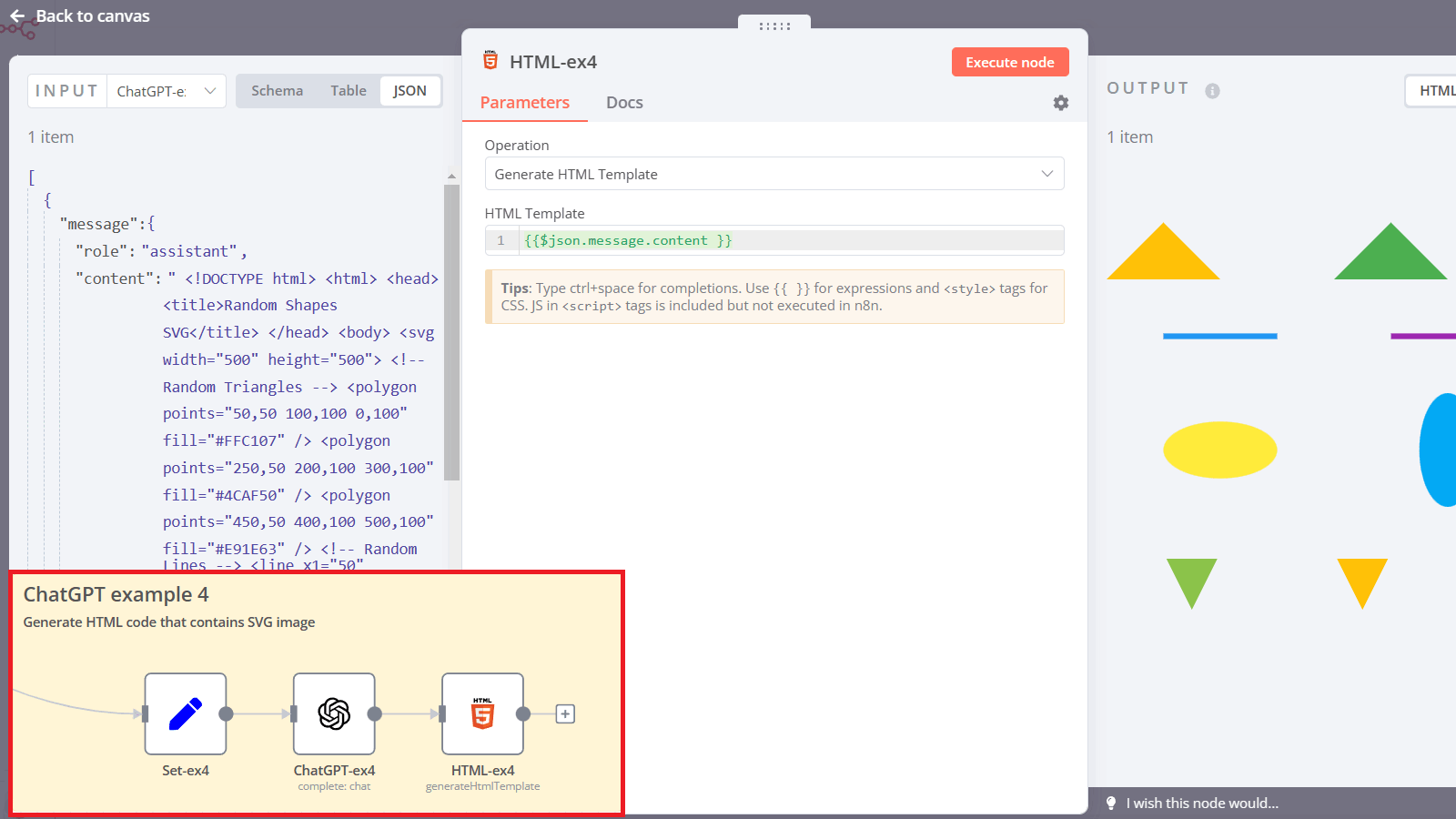
In this case, we are running an OpenAI node and sending ChatGPT a prompt: “Create an HTML code with an SVG tag that contains random shapes of various colors. Include triangles, lines, ellipses and other shapes”.
The output of the node is a valid HTML page with a <svg> tag, we can check it via the HTML node. ChatGPT is capable of helping programmers and engineers in many other ways:
- Create a docker yml config files
- Generate ICAL events that you can send via e-mails
- Write functions in JS, SQL, Python and other languages
- Fix broken code snippets
- Explain what the code is doing
Even better results can be achieved once again with chaining. For example, you can first extract column names from your dataset and use them along with the prompt to generate some SQL requests. This way you can help business users who want to get some information from the database but lack SQL skills to write the requests in plain English themselves.
Multimodality
Multimodality is a hot topic once again since the recent Microsoft announcement of the GPT-4. But what does it mean? In essence, this is the ability of the neural network to work simultaneously with the text, image, sound, video and so on.
Current DALLE-2 and Whisper models only allow working with text and either sound or image. However, with the chaining technique, you can get closer to multimodality even now.
Remember how we worked with a text example in the beginning of the article? We used an mp3 file of a short science podcast, then transcribed it via API and got a text.
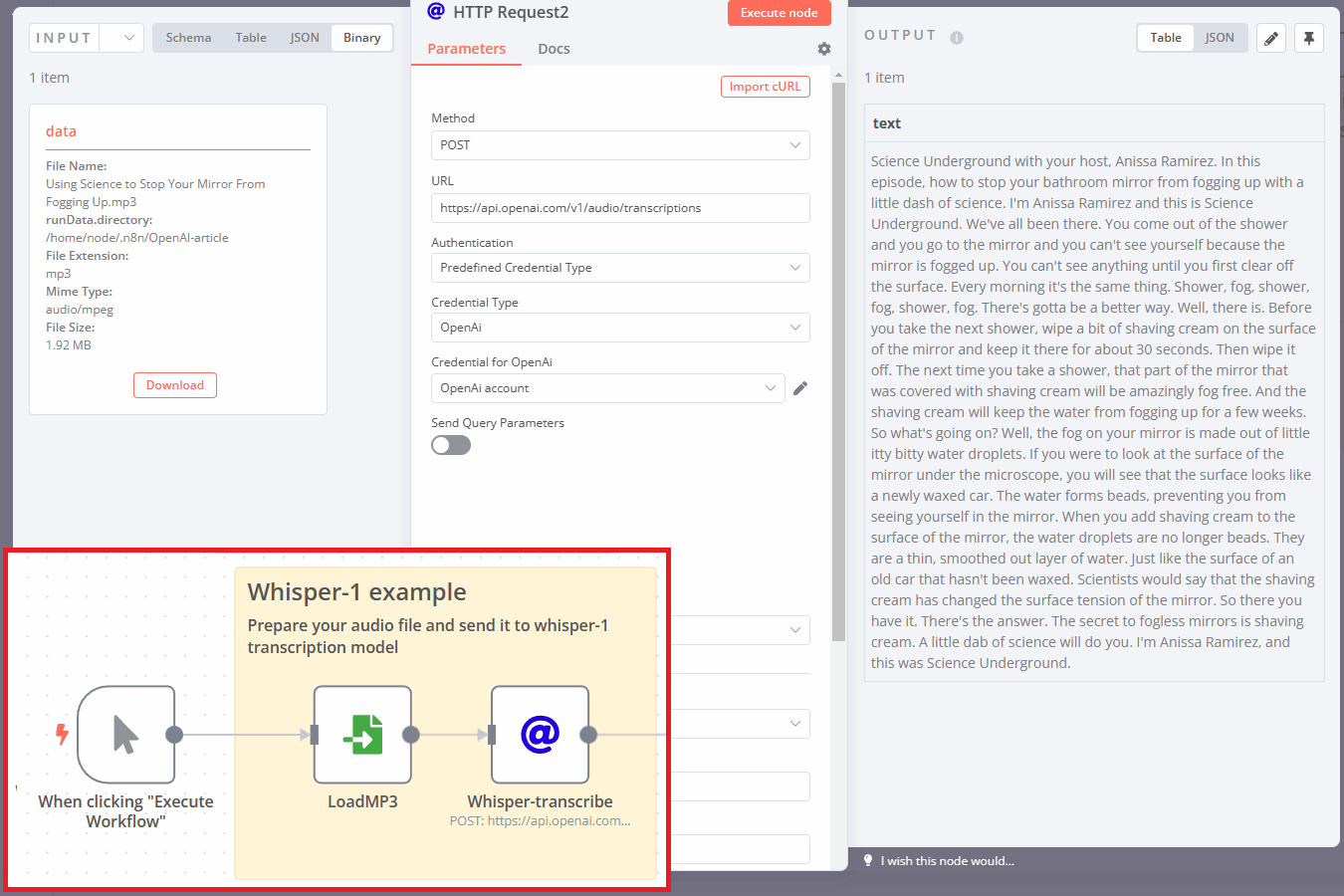
In examples 3.1-3.3 we shortened the whole episode into a brief summary, then got a prompt for the DALLE-2 image model and finally received a few comic-style cover images.
Essentially, we used three different models and also called the ChatGPT model twice. But if you are building a SaaS, you can allow your users to send an audio file and get text + image back just from a single API endpoint. With this trick, you can achieve some sort of multimodality.
Other use cases – building a knowledge base
There are several advanced use cases that didn’t make it into this article. One of them is called embeddings.
Consider the following scenario: you are building a knowledge database or documentation. How can you make a computer to provide an answer based on your specific knowledge base? This task was solved in many different ways in the past: manually, via search indexes and so on.
OpenAI provides its own approach:
- First, you need to classify all documentation articles
- Then figure out which of them are the most relevant to a certain user question
- And finally, use one or several documents inside a prompt of ChatGPT to provide an answer
How to achieve this technically?
Each text request, be it short or long, is coded as a long vector of numbers. By comparing the distance between vectors one can say which of the texts are more “similar” to each other. Supabase, an open-source backend service mentioned in one of our previous articles on low-code open-source tools, provides a mechanism for creating, storing and comparing such vectors. Here is an article about a Postgres extension called pgvector and how this extension is used in Supabase. With n8n and Supabase you can create a knowledge base and automate replies on user questions.
What’s next?
- Take the example OpenAI & n8n workflow as an inspiration and solve your tasks
- Check out several free n8n workflows with OpenAI integration. Register your n8n account in the cloud and start automating for free! You can also install n8n on the server.