If you’ve ever built an application powered by Generative AI, you know the feeling: one small change to a prompt, a model swap, or a slight tweak to a node can turn a perfectly functional workflow into an unpredictable mess. Unlike deterministic code, AI outputs introduce an element of delightful, yet frustrating, chaos.
This unpredictability is exactly why you can't just rely on guesswork when deploying AI. You need a dedicated, repeatable testing mechanism: an LLM evaluation framework.
In this hands-on tutorial, we'll guide you through the why and how of creating a low-code AI Evaluation Framework using n8n. You'll learn the key concepts, understand techniques such as “LLM-as-a-Judge”, and build a custom evaluation path that ensures you can deploy updates, test new models, and maintain quality with total confidence.
Why do you need an evaluation framework for your AI workflows?
An evaluation framework is the foundational practice that shifts your development process from relying on guesswork to relying on concrete, measurable evidence. Here are the five main reasons to build an evaluation framework into your workflows:
- Deploy with confidence: An evaluation framework acts as a dedicated testing path. By running tests against a consistent dataset, you ensure long-term reliability and high-quality outputs. This allows you to catch regressions or new issues before your end users do. It also lets you test against "edge cases" to ensure your system handles unexpected data gracefully.
- Validate changes objectively: When you tweak a prompt, did it actually improve the output, or did it just change the writing style? Without a framework, the answer is purely subjective. Evaluations give you evidence. You can definitely see if a prompt tweak or a fix for a specific error actually improved results or if it introduced new problems.
- Experiment and iterate faster: Fear of breaking production often slows down experimentation. Evaluations provide a safe sandbox. You can test radical changes to your logic or prompts and see the quantified impact immediately without affecting real users. This allows for rapid A/B testing, like comparing two different system prompts, to see which scores better against your benchmarks.
- Make data-driven decisions on models: New models are released constantly. An evaluation framework lets you quickly compare them. You can decide if switching to a new model makes sense for speed or cost-efficiency, or if a smaller model (like a Gemini Flash Lite) can perform just as well as a larger one for your specific task.
Why use n8n for LLM evaluation?
We’ll use n8n as an example for building your own LLM evaluation framework because it treats evaluation as a continuous, workflow-native practice rather than a one-off benchmark. With built-in and custom metrics, automated feedback loops, and ongoing monitoring, it shows how evaluation can directly support iterative improvement and production reliability.
Here are the key aspects of n8n’s flexible evaluation approach:
1. Straightforward implementation on the canvas
Traditional monitoring and testing tools, such as LangSmith, often come with a steep learning curve that requires configuring APIs, logging libraries, and external infrastructure. n8n eliminates this friction by bringing AI evaluation directly to its canvas.
This approach allows for straightforward and less error-prone implementations, relying on the visual, drag-and-drop interface you know and trust. You don't need to write custom Python scripts; you just need to connect nodes.
2. Evaluation as a dedicated workflow path
In n8n, an evaluation sequence is structured as a dedicated path within your existing workflow. This design is crucial because it ensures:
- Separation of concerns: You can execute the testing sequence separately from your production triggers (like webhooks or schedules).
- Focus on iteration: Developers can focus purely on testing, analysis, and metric calculation without disrupting the production logic that serves end-users.
3. Customizable inputs and metrics
The framework is highly flexible, allowing you to run a range of test inputs against your workflow and observe the outputs. Critically, the metrics applied are completely customizable. You can measure anything relevant to your specific use case, for example:
- Output correctness: Is the generated answer factually accurate based on predefined criteria?
- Safety and fairness: The presence of toxicity, bias, or alignment with safety guidelines.
- Tool calling: Whether the AI agent correctly invoked the right external tool or function (essential for complex agents).
- Deterministic metrics: Efficiency measurements like execution time or token count.
This collective data is essential for analyzing the effect of specific changes (e.g., swapping a model, modifying a system prompt) and comparing overall performance over time.
Key AI evaluation metrics and methods you can implement with n8n
LLM evaluation requires a nuanced approach, combining qualitative, context-aware assessments with quantifiable hard data. The flexibility of n8n allows you to implement both, often just by configuring the dedicated Evaluation node.
Here are the key methods you can deploy directly on your canvas:
1. LLM-as-a-Judge (the gold standard for open-ended tasks)
This is the standard approach for open-ended tasks where traditional metrics fail (e.g., creative writing or summarization). It involves using a highly capable model (like GPT-5 or Claude 4.5 Sonnet) to evaluate the quality of outputs generated by a target model (often a smaller, more efficient model).
How to implement it in n8n?
You no longer need to manually configure a "Judge" LLM and parse JSON responses. Instead, open the Evaluation node and select one of the AI-based metrics:
- Correctness (AI-based): automatically scores (1-5) whether the answer’s meaning is consistent with your reference answer.
- Helpfulness (AI-based): scores (1-5) whether the response successfully addresses the initial query.
- Custom Metrics: If you need to test for something specific, like "Did the AI adopt a pirate persona?", you can use the Custom Metrics option to define your own criteria.
2. Evaluating complex agent workflows (RAG and tool use)
If your workflow uses Retrieval-Augmented Generation (RAG) or relies on the LLM to call external tools, you need to evaluate the entire system, not just the final text generation.
How to implement it in n8n:
- Tool usage: Use the built-in Tools Used metric in the Evaluation node. This returns a score checking if the agent correctly triggered a tool call when expected.
- RAG faithfulness: You can use the Correctness (AI-based) metric to verify that the generated answer aligns with the ground truth found in your documents.
3. Quantitative metrics
These provide unambiguous data points that complement the qualitative assessments from the LLM-as-a-Judge.
How to implement it in n8n:
- Deterministic Metrics: These are tracked automatically by n8n’s evaluation process:
- Token Count: Essential for tracking cost.
- Execution Time: Critical for monitoring user experience latency.
- Categorization: Perfect for classification tasks (like our sentiment analysis example). It checks if the output exactly matches the expected class (returning 1 for a match, 0 for a miss).
- String similarity: Measures the character-by-character distance between the result and the expectation. This is useful when you want to catch minor formatting errors or typos without penalizing the model for a valid answer.
- Safety & performance: For metrics not yet built-in (like specific Toxicity checks or detailed execution latency), you can simply define them using the Custom Metrics feature within the Evaluation node.
- Traditional ML Metrics: For structured tasks (like entity extraction), use the Custom Metrics feature to compare the output against a ground truth using classic metrics like Accuracy, Precision, Recall, or F1 Score.
4. Policy and safety evaluation with the guardrails node
For enforcing safety, security, and content policies in real-time, the Guardrails node is essential. You can use it to validate user input before sending it to an AI model, or to check the output from an AI model before it's used further in your workflow. This allows teams to validate AI responses in real-time, checking for content quality, safety, or custom rules before routing failures to fallback agents or human review.
The node offers two primary operations:
- The check text for violations: Any violation sends items to a “Fail” branch, which is ideal for evaluation where you want to halt the workflow on an issue.
- Sanitize text: Detects and replaces violations like URLs, secret keys, or personally identifiable information (PII) with placeholders. This is useful for cleaning data within the workflow.
The true power of this approach lies in combination. You can set up a single Evaluation node to check for Categorization (accuracy), Tools Used (logic), Helpfulness (quality) as well as safety, while simultaneously giving you an overall view of performance.
How to build an LLM evaluation framework for a sentiment analysis workflow with n8n?
To illustrate the capabilities of n8n’s evaluation features, we are building a workflow that performs sentiment analysis on incoming emails, categorizes them as Positive, Neutral, or Negative, and routes them to the appropriate sales team.
We want to ensure the categorization works properly. To do that, we will build an evaluation workflow, feed it some tricky use cases, and compare different models to find the cheapest one that performs the task reliably. We will test Gemini 3 Pro, Gemini 2.5 Flash, and Gemini 2.5 Flash Lite. The latter is the most affordable option. If it can handle our workflow, that is a huge win.
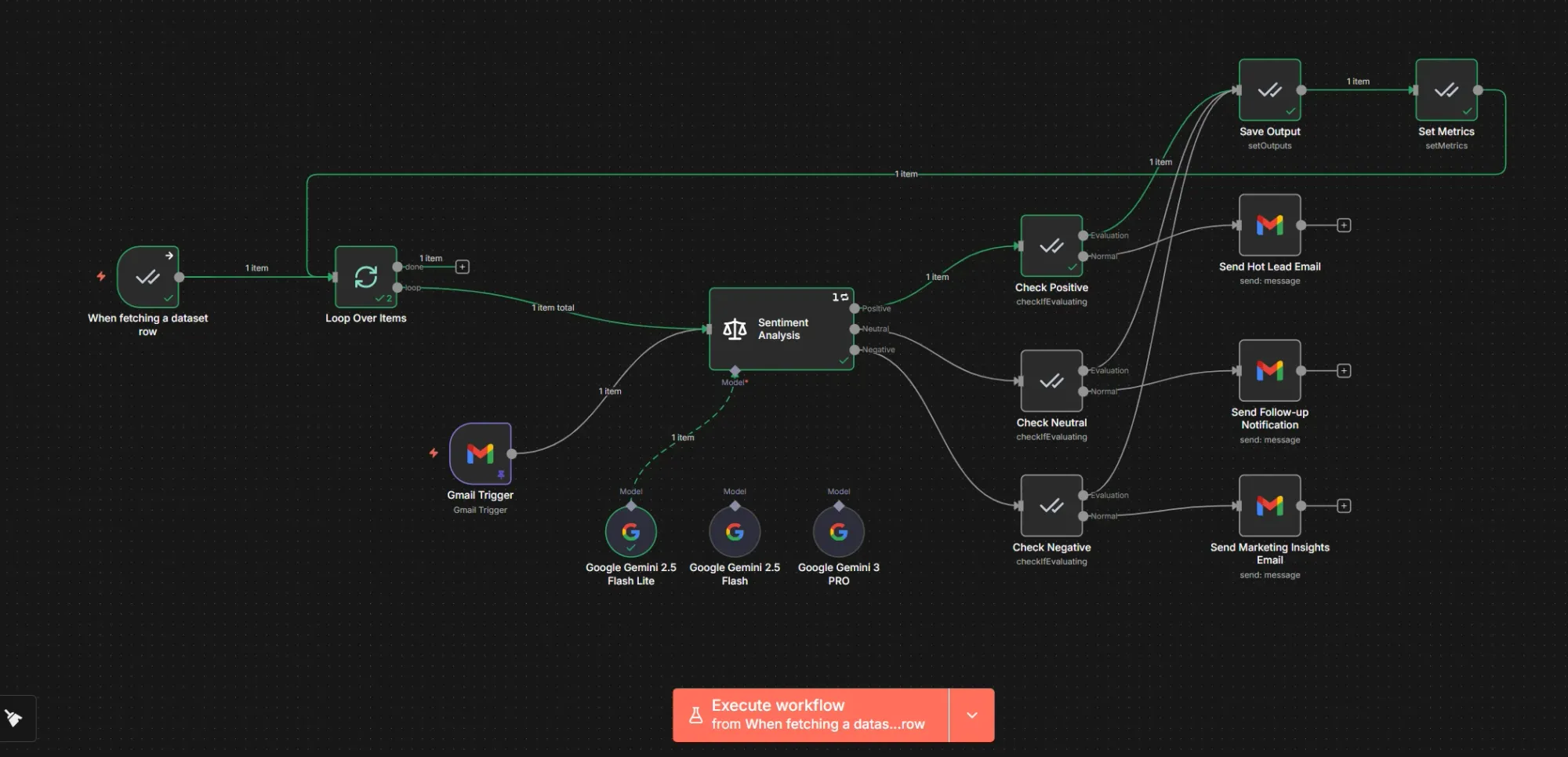
One of the best parts of the n8n implementation is that it allows you to house the evaluation logic directly alongside your actual workflow.
Step 1: Setting up the ground truths using Data Tables
To run evaluations, we first need to establish test cases and ground truths. The new Data Table feature in n8n is perfect for this. Think of it as a database table that lives directly in n8n, which workflows can read from and write to.
For this example, I created 10 test cases. The goal is to find the smallest (and cheapest!) model that performs correctly, guiding us to tweak the system prompt for perfect accuracy.
To stress-test the models, the test cases are tricky in a few ways:
- Competitor frustration: The text might list frustrations with a competitor’s solution. While it contains negative words, the intent is actually positive for us (they want to switch). Traditional ML often fails here, but LLMs should catch the nuance. We want to see if the smaller Flash Lite model can match the accuracy of Gemini 3 Pro on this.
- Sarcasm: Phrases like "I was thrilled to see my project pipeline freeze for six hours yesterday" should be classified as Negative. Only a capable LLM will catch this tone.
- Mixed signals: Combining a small compliment with a major complaint. This should be classified as Negative overall.
Once the data table is set up, it looks like this:
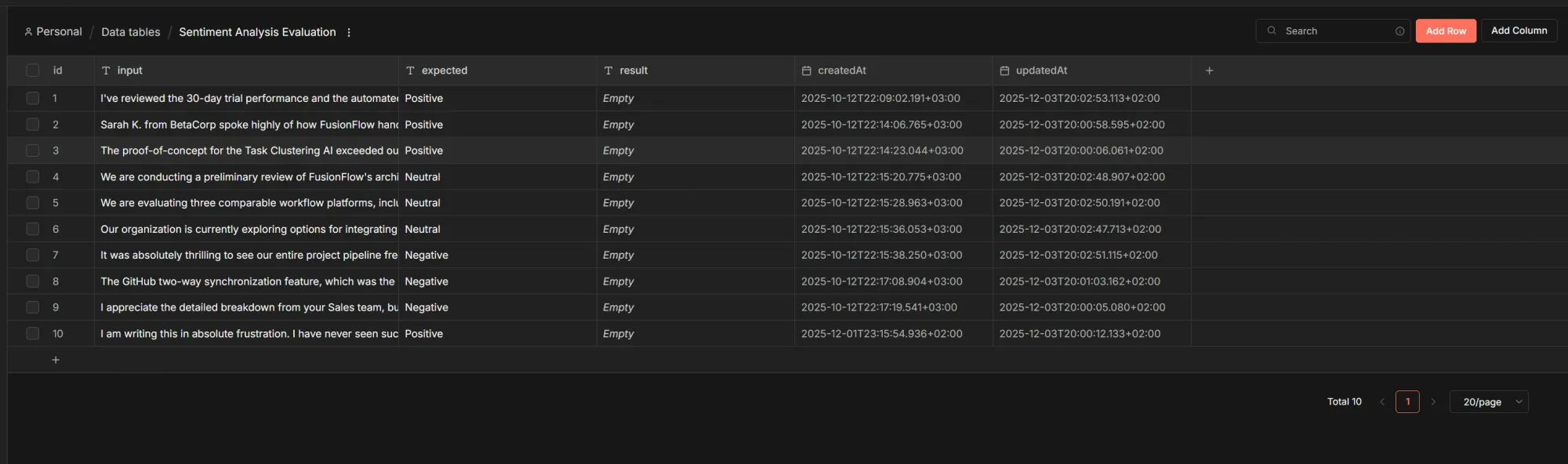
The expected column contains our ground truth, and the result column starts empty, this is where we will store the latest evaluation output.
Step 2: Creating the evaluation workflow
Now, let’s build the evaluation workflow. We start by fetching all records from the data table and looping over them.
Inside the loop, we pass the data to the Sentiment Analysis node, configured to categorize emails into three buckets: Positive, Neutral, or Negative.
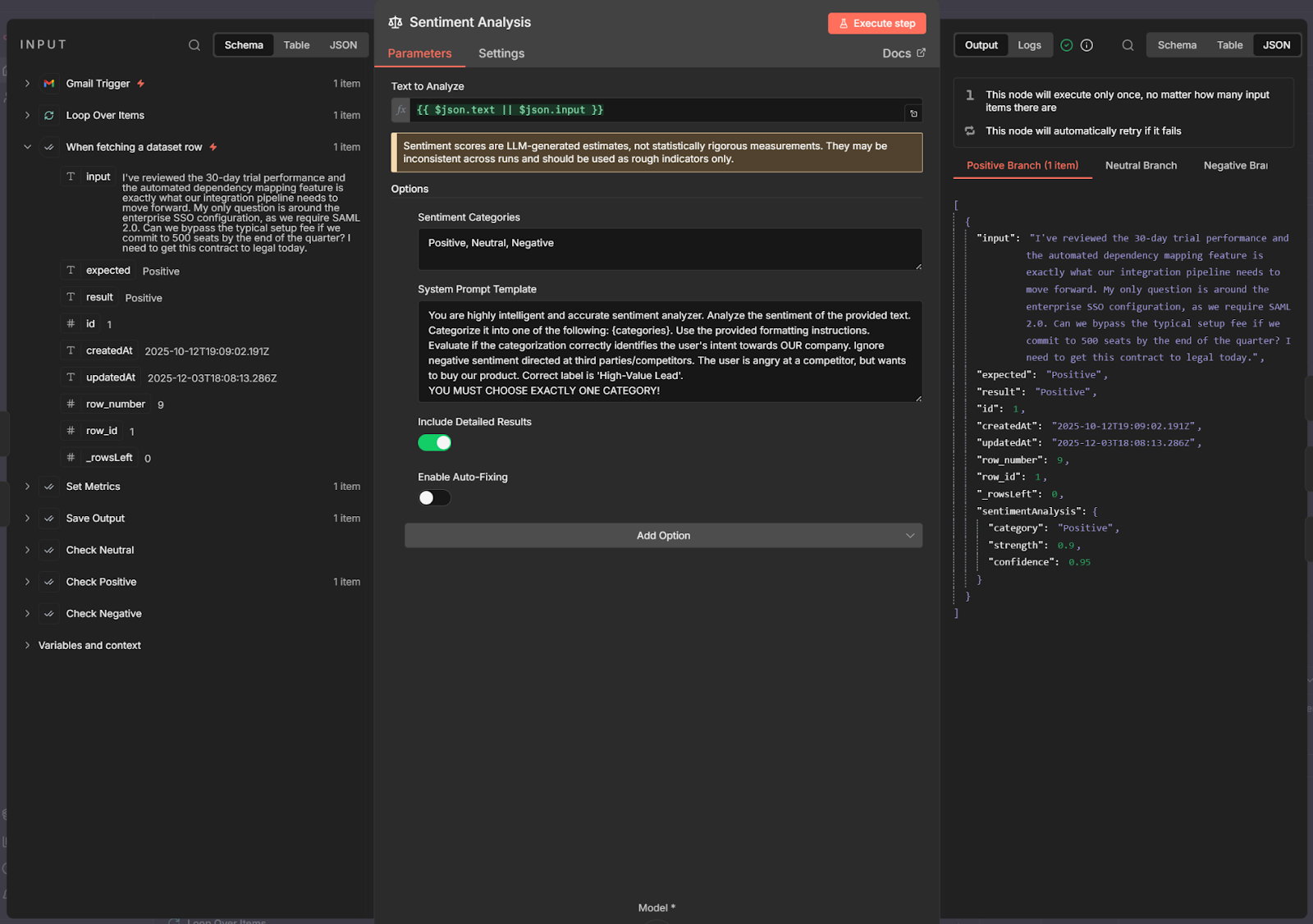
Normally, the workflow forwards the email to the appropriate team based on the category. However, we don't want to send real emails during an evaluation. To solve this, we use the Check if Evaluating node. This splits the workflow into two paths: one for the active evaluation, and one for the normal production run.
On the evaluation path, we use the Set Outputs option of the Evaluation node. We select our "Sentiment Analysis Evaluation" table and map the output of the analysis node to the result column.
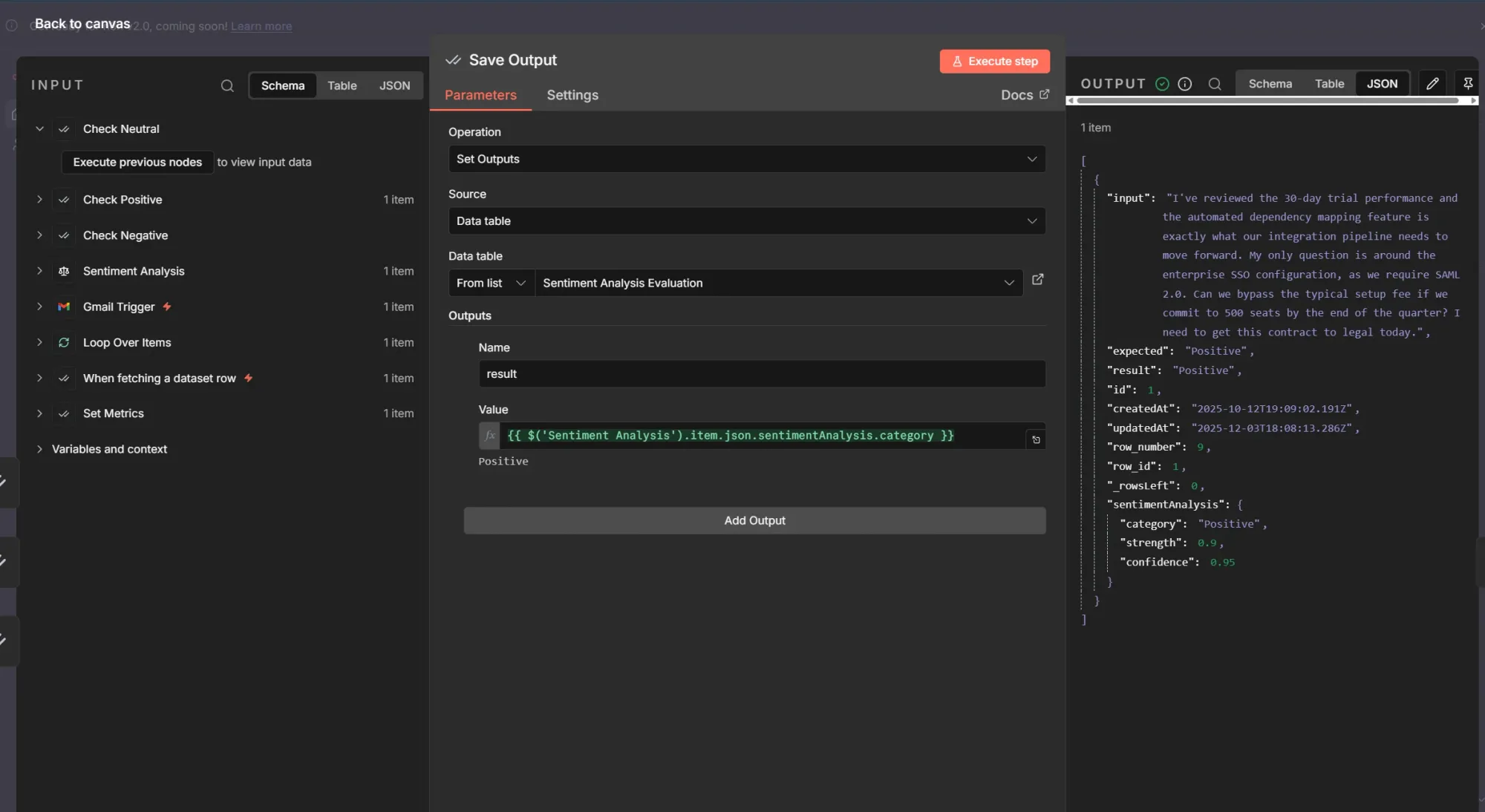
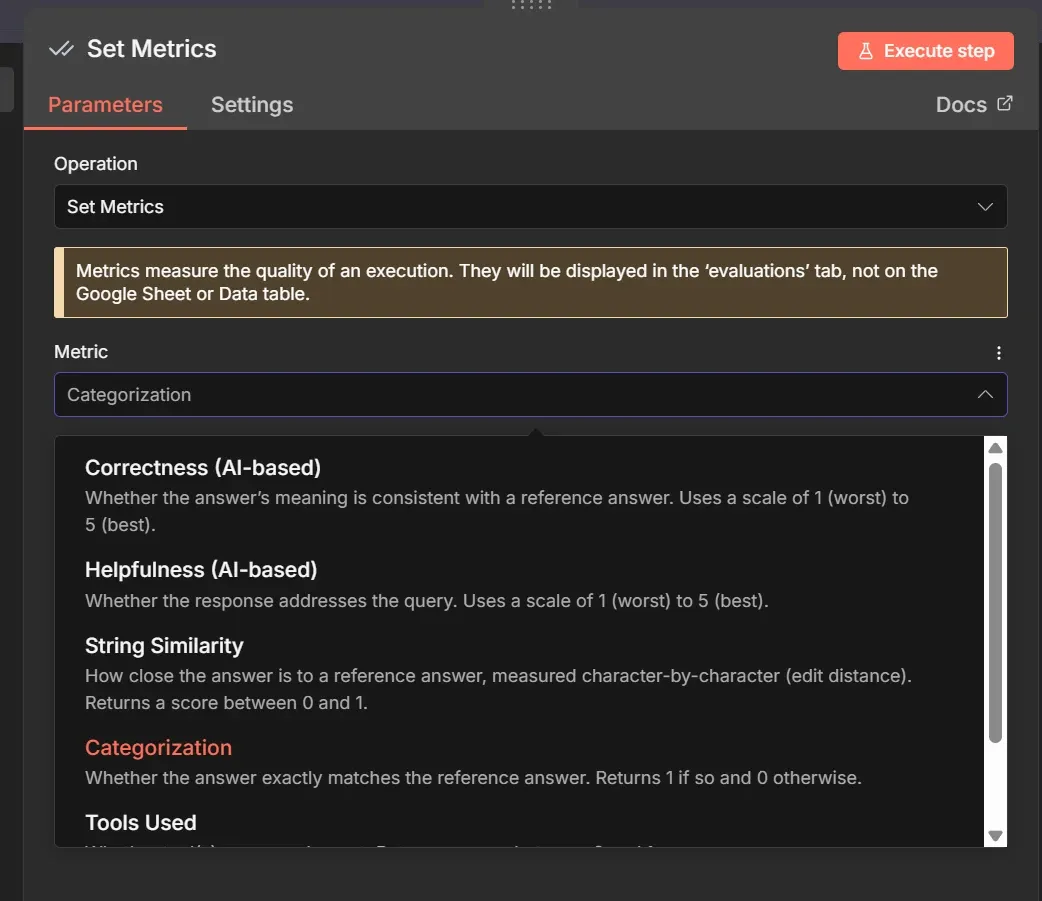
Step 3: Computing metrics
Computing metrics is vital to understanding performance at a glance. We do this using the Set Metrics option of the Evaluation node. We can select the built-in Categorization metric, which is designed specifically for this use case.
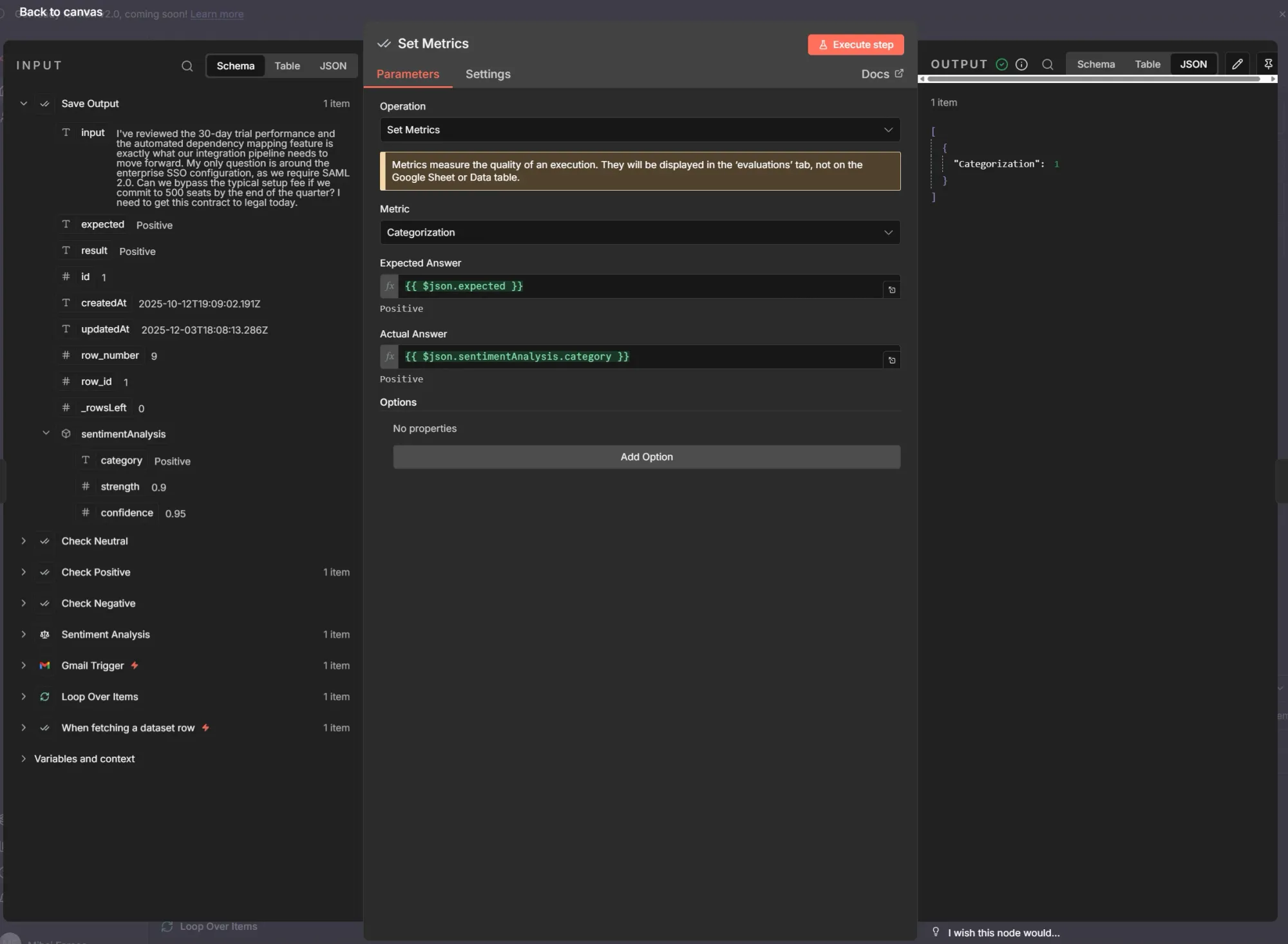
This metric simply compares the expected answer with the actual one. It returns a 0 for a mismatch or a 1 for a match, exactly what we need.
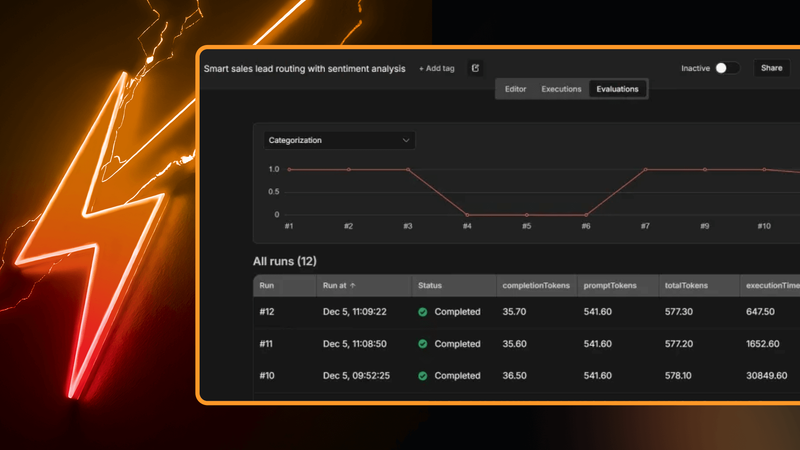
Step 4: Running the tests
Now we can run the evaluation directly from the canvas to test it. Alternatively, we can use the new Evaluations tab at the top of the canvas. Runs started here are saved, providing a visual chart of metrics over time.
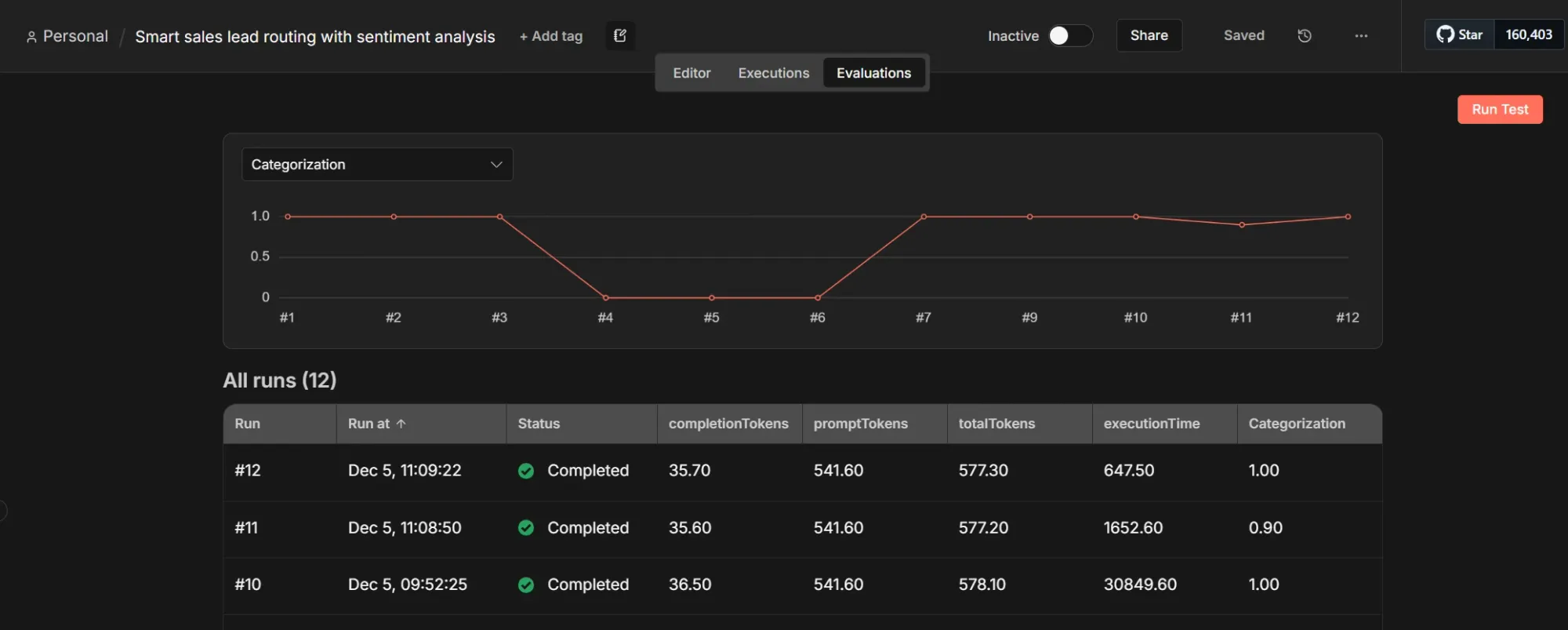
We ran this evaluation three times, yielding valuable insights: All three models handled the test cases perfectly, despite the tricky edge cases. However, the performance differed significantly:
- Gemini 3 Pro took over 30 seconds.
- Gemini 2.5 Flash took about 1.6 seconds.
- Gemini 2.5 Flash Lite finished in just 650 milliseconds.
This makes the decision a no-brainer: Gemini 2.5 Flash Lite is accurate enough for this task and is the fastest and cheapest option. This is the clear benefit of having an evaluation framework!
Best practices for building your LLM evaluation framework in n8n
Building an LLM evaluation framework is as much about process as it is about the tools. Here are five best practices to ensure your evaluations remain reliable and scalable:
- Always separate evaluation logic: Never mix testing logic with production actions. Always use the Check if Evaluating node to create a clean separation. This prevents "test pollution"—like sending 50 test emails to your sales team—and ensures your metrics are calculated only during actual test runs.
- Curate a "Golden Dataset": Your evaluation is only as good as your data. Don't just generate random strings; build a Data Table containing real-world edge cases, previous failure points, and tricky adversarial inputs (like the sarcasm example). As you discover new failures in production, add them to this table to prevent future regressions.
- Combine qualitative and quantitative metrics: Reliance on a single metric can be misleading. A model might be fast (low latency) but hallucinate facts (low correctness). Always pair deterministic metrics (like Execution Time or JSON Validity) with qualitative ones (like LLM-as-a-Judge) to get the full picture.
- Isolate variables during testing: When comparing performance, change only one variable at a time. If you swap the model and change the prompt simultaneously, you won't know which change caused the improvement (or regression). Test a prompt change on the same model first, then test different models with that fixed prompt.
- Keep human-in-the-loop for the "Judge": While "LLM-as-a-Judge" is powerful, it isn't infallible. Periodically audit the decisions made by your Judge node, especially for subjective metrics like "Helpfulness." If the Judge is consistently misinterpreting your criteria, you may need to refine its system prompt just as you would for your main agent
Wrap up
We have moved from the "delightful chaos" of unpredictable AI outputs to a structured, engineering-grade process. By building an evaluation framework directly in n8n, you have shifted from guessing to knowing.
You now have a system that allows you to:
- Catch regressions before they hit production.
- Quantify the impact of every prompt tweak.
- Compare models objectively to optimize for cost and speed.
This framework is your safety net, allowing you to innovate faster and deploy with the confidence that your AI agents will perform exactly as expected.
What’s next?
Now that you understand the concepts, the best way to learn is to see these workflows in action. We highly recommend watching these tutorials from the community to deepen your understanding:
- Beginner's Guide to Workflow Evaluation in n8n (Stop Guessing!) – A fantastic overview of why evaluation matters and how to set up your first "exam" for your AI.
- The Beginner’s Guide to n8n Evaluations (Optimize Your AI Agents) – A deep dive into optimizing agents using the evaluation tools we discussed.
- Evaluate Your RAG System with N8N – Essential viewing if you are building Retrieval-Augmented Generation workflows and need to test factual accuracy.
Start small, build your first test dataset, and happy automating!